Thanks for spotting this out! I just updated the link. Please let me know if it works!
Nope, still asks for permission.
1 Like
Now it should work 
Ahhh. I think you need to switch your loss back to CrossEntropyLossFlat for the validation since your ground truth labels are not in that form  (One hot encoded)
(One hot encoded)
I found the issue here, your parent_label function is returning “cat” or “dog”, as strings just list of characters the MultiCategorize() function thinks each unique letter is a class, therefore it outputs 0 to 5.
It can be easily fixed by adding lambda label: [label] after parent_label(like you did in the first dataloader), now you get a single digit 0 or 1, but the model outputs 2 numbers, to fix this add OneHotEncode() after MultiCategorize().
Finally, your code should look like:
dsets = Datasets(get_image_files(test_path),
tfms=[
[PILImage.create],
[
parent_label ,
lambda label: [label],
MultiCategorize(),
OneHotEncode()
]
])
Mmm it does not look right…

- Why parenthesis around PILImage.create? 2. Why are you adding OneHotEncode()? I was not using it in the first part 3) It is only returning two numbers, what do they mean?
In a DataSet that has a Y, the first array of transforms goes to the X’s, the second to the Y’s. So we have
tfms = [[PILImage.create], [parent_label]]
Meaning that the first (PIL) goes to the X’s, the second (parent_label, etc) goes to the y’s
Multi-Category wants one-hot encoded labels, rather than the simple encoded ones we use in single label classification
First is your loss function, second is your metric. So presumably the value of BCELossLogits and accuracy_thresh
1 Like


Thank you for this explanation!
I’m having trouble understanding why loss in this image is just the correct label. 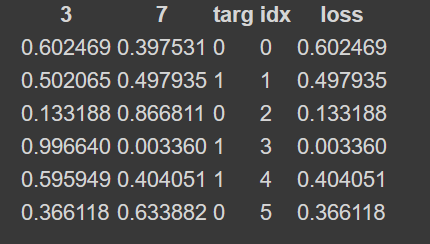
Shouldn’t the loss be how much the prediction is off by? ( if targ = 0, 0th prediction is .602, then it’s off by 1 - .602)?
I’m also having a hard time seeing where the log comes in after taking the negative loss from this. I’ve tried to use log myself, but I get an “out of domain error” as log isn’t defined for negative numbers. Does this mean you take the log on the raw probabilites(loss) before making it negative?

The loss shown in the image is just softmax values corresponding to targets. NLL just applies a negative sign in top of the output.
Cross entropy in Pytorch however is log softmax+NLL.
So for the question on log, you have to apply log on the positive values(softmax) then take negative of the result(NLL).
Ok, thank you. I understand that you now take the log on the positive values, and then *-1 them. I’m still confused as to why loss is simply the activation of the correct class. I don’t know why the loss wouldn’t be the “squished” value, or the probability of it being the correct class -1.
Also, is the reason that the final outputs are positive because at the end you use softmax?

Btw, thank you very much for your correspondence.
The idea of loss function is to penalize the wrong predictions. (Log) Softmax + NLL ie., CrossEntropy loss does that by assigning higher loss value where the predictions are not inline with the target.
I feel that the example shown in the notebook is to showcase and make the reader understand how softmax is calculated and how NLL is applied. And how CrossEntropy Loss in Pytorch is used ie., Log Softmax + NLL.

Here is a neat write-up explaining this in detail.
As for the second question, the output of log softmax will be negative, multiplying the output with -1 will result in a positive value.
1 Like
Thank you, that link did help clear some things up. But I’m still left scratching my head with the final result of the calculation. I’m really confused on how to get that last bit. I’ve tried following along with microsoft’s calc. Is that log different than the one this resource is using?

Have you ensured that you have used the log to the base ‘e’ and not base 2 or base 10?
1 Like
Brilliant, thank you. I have to walk through the math to get things to click. And now it makes more sense. I’ve never really been super comfortable with logs. Thanks again for helping me through my problems! I really appreciate it!
Glad things got sorted out. Cheers!!
After going through all the videos (8 currently) it felt very clear to me that my biggest gap was not totally owning the material from book chapter 4. I really needed to go back and build my learner which felt like a pretty imposing task from just the book itself. Using another forum post and chapter 4 I got a learner built and realized I still had a lot of fuzziness about what was going on, so I did what I normally do as a teacher - I wrote an explanation that would, theoretically, be aimed at my high school students. There’s a few things that aren’t fully explained as I covered them through other notebooks I wrote theoretically explaining stuff to students but I felt like this notebook explained chapter 4 in my own words. If this helps anyone else make sense of the beast that is chapter 4, enjoy. If any of you have time to take a look and correct any outstanding misconceptions I still have that would be greatly appreciated.
1 Like
Hi, I am understanding the parameters that are composed of the weights and the bias:
y=w*x+b. Can someone explain to me why b is a single number instead of a vector (with a bias for each pixel)?
Thanks!
1 Like
I am assuming you’re question is referring to the MNIST example in this lecture’s video where jeremy does xb@weights + bias.
My guess:
Its possible to have a bias for every pixel, but that will increase the number of parameters to be learned and one doesn’t really need it here for this simple example.
The effect of a matrix or vector of biases per pixel, would probably raise or lower the importance of certain areas of the input image (imagine it’s effect if you had a zero input).