FYI when I tried concatenating the embeddings in a colab model I got slight worse results. Perhaps you could do the dot product, then concat the result with the metadata. I’m not sure what best practices are.
5 Likes
How has your experience been running Tabular learner on GPU vs CPU? I don’t see much of GPU being used.
Is there any information anywhere about collaborative filtering where your training data is a temporal series and you want to predict the optimal decision given a set of choices for each timestep in a new instance?
For a toy example, a while back I had an idea for creating a model which makes the decisions for you in a certain video game ,where a playthrough of this game is made up of an exactly similar small number of discrete decisions.
However, there are certain things that you want 1-2 of in general at some point later in the game, but don’t want in the first 5-10 steps of the game, and vice versa. The game data files I have reflect this idea, and I assume that some form of collaborative filtering model could work for this, but how would you implement that idea of the ‘shopping cart’ being a temporal series of decisions?
Has this been studied at all, and if so can anyone link me to some research or search terms?
Hi there,
I want to find similarity between two sentences. I’m thinking of converting the sentence into a vector and then doing cosine similarity for it.
I saw that similar thing is done in case of images in DatasetFormatter.from_similars - Activations of the last layer in the model are converted into a vector and cosine similarity is taken to find similarity between images.[Medium post] [Code]
Can I use ULMFiT to get the activations of the last layer for a sentence and then compare them to find similarity? Your opinion and guidance are much appreciated.
PS: This my first post in the forum and I’m a newbie. If this is not the place to post this question, please direct me to the correct topic.
Many Thanks.
2 Likes
Hi everyone, I’m trying to implement collab filtering to a problem, in business, where I have all the User ratings for movies (filled up matrix) and my main goal is to obtain an accurate embedding matrix that describes each User perfectly. Has anyone done something similar? Let me know and we can share ideas 
@Andreas_Daiminger @seb0 @jeremy
There are 3 main types of recommendation systems
1. Content-based filtering
This is where you would employ search techniques and unsupervised learning to come up with a representation of each item you want to recommend.
For example, if you have the title, description, genres for each movie in MovieLens you use TF-IDF (or the sum of word embeddings) on the title and description and something like a simple set intersection on the genres for each movie to discover the Batman Begins is close to The Dark Knight.
This allows you to say “You watched your first movie, here are some similar ones”
This is the simplest approach
2. Collaborative Filtering
This is everything @jeremy teaches so I won’t go over it really.
However, it should be noted that Explicit collaborative filtering has generally fallen out of favor and more recent recommendation systems rely on Implicit data.
- Explicit means a rating, the user actually decided to give a star rating to the movie, or clicked the like button on a YouTube video for instance
- Implicit represents the users inherent behavior. For example, the user watched the movie but did not rate it.
You generally have significantly more implicit data and it turns out the people are actually quite bad at rating stuff as “5 stars” means something different to every person.
In practice, that means you’d have a User x Movie matrix where the values would be 1 if the user has watched the movie and a 0 otherwise. A 0 does not mean the user disliked the movie, it just means they haven’t interacted with it. You need a new loss function to handle this kind of data so we generally use something like Bayesian Personalized Ranking https://medium.com/@andresespinosapc/learning-to-rank-bpr-5fe5561d48e0
(or WARP)
3 Hybrid Recommendation Engines
This IS NOT the combination of 2 separate models (one for Content-based filtering and one for collaborative filtering. That is an ensemble network)
Hybrid recommendation engines run the traditional collaborative filtering process, trying to learn User and Item embeddings. However, they incorporate user-specific and item-specific metadata during the training process.
The user embeddings and item embeddings are represented as a sum of the embeddings of all their features. So if you had the genres: action, thriller to describe the movie John Wick then the item embedding for John Wick would be the sum of the embeddings for the genres action, thriller, and the movie id instead of just the movie id like we do in traditional collaborative filtering.
In practice, this is similar to how the TabularLearner works. It learns an embedding for each of the categorical features. Each row in the table would be a different movie and each column would be a genre. The genre embeddings are learned through SGD but instead of trying to predict a classification value, we sum the genre embeddings for each row E(action) + E(thriller) + E(movie_id) = E(movie) = John Wick.
Hope this all makes sense. Feel free to ask questions.
@jeremy are you interested in adding any of this into the fastai library?
I’ve really only scratched the surface here. There is a whole class of recommendation systems that treats user interactions as a sequence and uses RNNs to predict the next user action that’s showing a lot of promise right now.
10 Likes
If you find you can get better results, and the code is clean, then absolutely! ![]() Although I suspect things like factorization machines may be better still…
Although I suspect things like factorization machines may be better still…
Hey @seb0
Not sure if you are still interested in this. But I cam across Deep Factorization Machines. It’s a very interesting approach to combine the Factorization with a NN. I will be experimenting with this the next couple of weeks. Here the paper
1 Like
Yup I am ! I will check it out. Thanks @Andreas_Daiminger
Dumb question, (I may have missed this)…
when running out of memory during training, is all lost, (97% done for ex. then couldn’t allocate to GPU…) - i.e. unless learn.save(), it’s time to start over?
is there a way to incrementally save progress, and if need be, perhaps continue with online learning when restarting kernel? Am I thinking about this the wrong way? Thanks!
In Fastai 0.7 you could use the best_save_name parameter during training to save the best model.
I am sure there is something similar in Fastai 1.0
You can see a bunch of callbacks to save your training progress here
CNNs no, at least not that I am aware of. The point is that a convolution is a filter operation that works fine with images. There is no equivalent for texts yet. This is a great research topic, though.
Hi every one. please if anyone can explain what Jeremy mains by that:
Then we’re going to split into training versus validation sets. And in this case, we do it by providing a list of indexes so the indexes from 800 to a thousand. It’s very common. I don’t quite remember the details of this dataset, but it’s very common for wanting to keep your validation sets to be contiguous groups of things. If they’re map tiles, they should be the map tiles that are next to each other, if their time periods, they should be days that are next to each other, if they are video frames, they should be video frames next to each other. Because otherwise you’re kind of cheating. So it’s often a good idea to use split_by_idx and to grab a range that’s next to each other if your data has some kind of structure like that or find some other way to structure it in that way.
he talked about this part in the notbook :
.split_by_idx(list(range(800,1000))
thanks a lot.
Hi! I am working as an intern at a startup. Since I am doing the Fastai course Part-1 using Deep Learning, I requested my firm to allow me to use their dataset to experiment and come up with some prototype or model. The startup is not yet into AI or ML domain and are into education.
I want to build a model which can suggest courses to the students based on their performance, time spent on the courses, results from the quiz attempted. Can anyone guide me or suggest if it’s possible to build such a personalized course recommender system for individuals with the collaborative filtering and embeddings?
Though my internship ends in 8 days, I would like to give it a shot which will boost my confidence and help me ahead in my pursuit to get placed into ML/DL related jobs.
Thanks,
Bhavesh Shah
Massive caveat: I’m brand new to this and don’t have a great grasp of the math yet.
Off the top of my head–theoretically, since a convolutional layer is meant to identify something like edges by performing operations on surrounding pixels to determine a value for the middle pixel, would it be possible to use a convolutional approach to a sequence? Approaching that sequence bi- or non-directionally and using the surrounding words in the way you’d use surrounding pixels.
Instead of edges, you’re looking for parts of speech; instead of corners/faces/whatever, you look for clauses.
Yes, CNNs are used during NLP as well. It is an alternative approach to RNNs. There are many papers on it as well. 
1 Like
Good to know! I’ll track down those papers. Really interesting topic.
I am wondering whether the following problem can be solved using collaborative filtering. Users answer multiple-choice Questions. If a user answers a question they may choose A, B, C or D. So the dependent variable that we would like to predict is categorical. Based on how a user has answered some questions I would like to predict which answer they would choose for a new question.
Can this be easily solved using collaborative filtering? Or would you use “Users” and “Question-Answers” instead of “Users” and “Questions”? So instead of looking saying “User 1233 answered Question 123213 with value C” we would say “For User 1233 and Question-Answer 123213-C give a value of 1, For User 1233 and Question-Answer 123213-A give a value of 0, etc”.
(Absolutely loved the Excel demo of collaborative filtering btw!)
I’ve made an app that does collaborative filtering on board game reviews: Check it out.
Basically I used the same code as in class, but afterwards explored the game embeddings with nearest neighbors (sklearn). This way you can find the most ‘similar’ games, with the idea that there might be similar games that are rated higher.
Example searches: Catan, chess, magic etcetc
Previously I only could program python in notebooks, but with the course you’ve have pushed me to use cloud computing and make a webapp with js and html. It took a lot of time, but I’m sure proud of the result. Thanks!
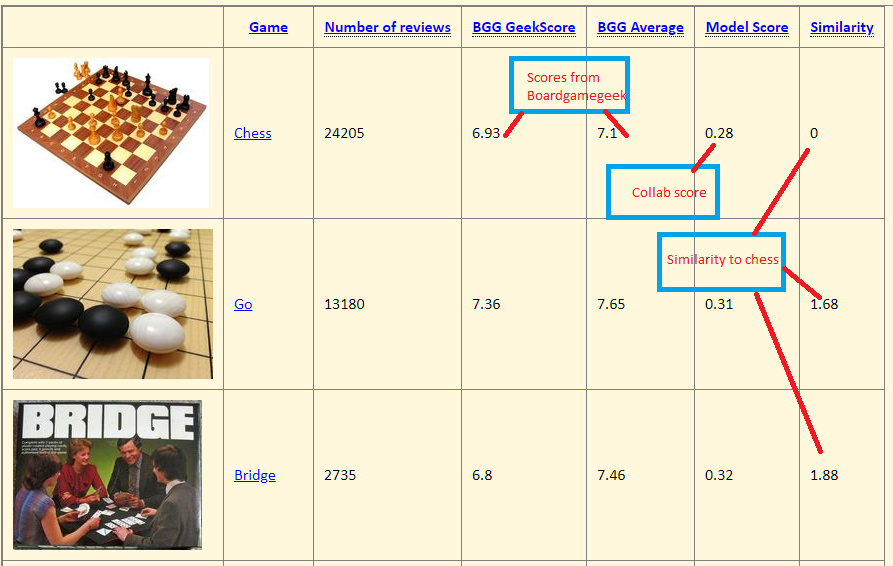
5 Likes
Morning, everyone
I am trying to use the way"data block API" as below try to load and preprocess my text files data(including some char need to been encoding to “ISO-8859-1”). After run below script, I got error “UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xe9 in position Detail error: 951: invalid continuation byte”. Does anyone know how to fix that? Thanks!
“data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=[‘Jobs’])
#We may have other temp folders that contain text files so we only keep what’s in train and test
.split_by_rand_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
data_lm.save(‘data_lm.pkl’)”