First of all thanks a lot for this series of classes on deep learning which actually supported me in changing the course of my career.
I have a quick comment on this lesson 4 regarding the illustration of collaborative filtering in Excel. You introduce the importance of having a bias term in the user and movies embeddings in order to take into account user or movie specifics. By adding the bias term, you show that the RMSE of the small dataset in Excel drops from 0.39 to 0.32, and conclude that bias is a useful addition to these matrices.
I do not believe the conclusion nor the reasoning is correct. You essentially increase your model’s parameters size by 20% (going from 5 to 6 rows for movies and users) and observe a decrease of the RMSE on your training set. This would be the case for any other model. In fact, I am wondering if you would have seen a different effect if you would have just added another row to the weight matrices (not in the bias).
My intuition is that the “bias” effect can be fully captured by just having on average lower/higher weights for a given movie or user and the same effect can still be achieved by simple matrix multiplication.
This may be harder for the model to learn (and hence the benefit of bias), but I find the process to reach your conclusion arguable.
Thanks again for the course, I’ve been following and re-watching them for the past years!
I tried adding other symbols at the end ',;!, but only . gets misclassified.
Does anyone have a reasoning/explanation why can the model fail on such a basic example?
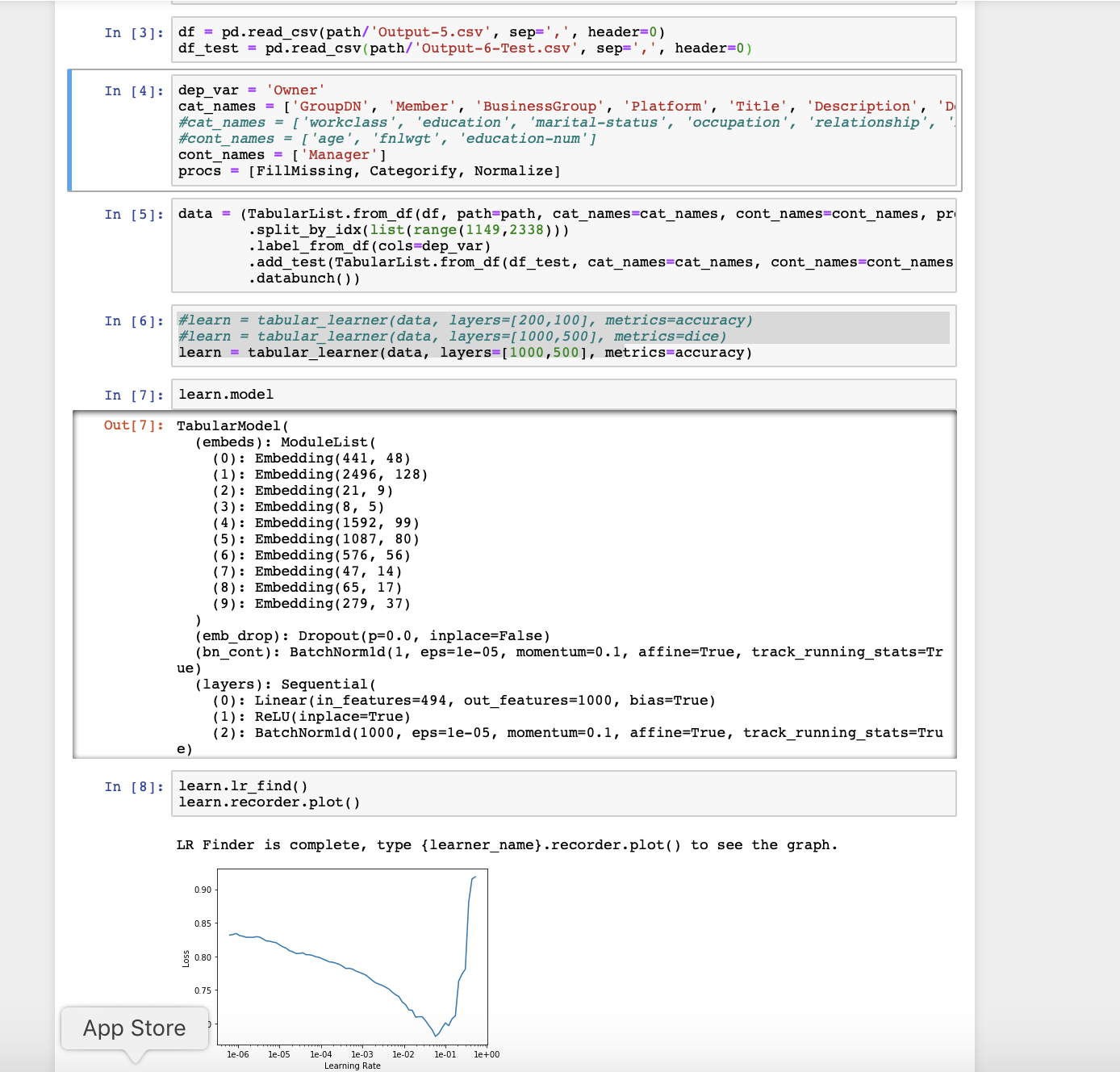
i am trying to use the tabular learner. Using to identify an owner of a group.
script successfully completes, below are the details. But in the output file i dont see any predictions (all the predictions comes as ‘No’ i.e 0). Any suggestions on what to check or how to check?
As for as I know, the * on the first line does elementwise multiplication of the user and item tensors. In the imdb movie example, these two tensors happen to have the same shape. Won’t this not work if this is not the case? I.e. if we have more users than movies, what happens in the dot = ... line?
I don’t think this is a problem. If you have N users and M items, dot will have NxM shape. In this case, when you are doing matrix multiplication you only need to ensure that you have one side of each tensor with the same size, which corresponds to the number of factors.
The TextDataBunch creates the tokens automatically and it removes most of the words from my data set, it sets them to ‘unknown’. Since my dataset is small, i don’t want anything to be ‘unknown’ since every word for me is important and most of the words appear only 1 time.
How can i use TextDataBunch but do simple tokenization and not put words to ‘unknown’?
For numericalization, we call - data.train_ds[0][0].data[:10]. i am unable to understand where is the .data[:10] being called from. The class for data.train_ds[0][0] is fastai.text.data.Text and that has no methods in it. How are we managing to call .data[:10] and which class does this method belong to?
So I’m trainig a sentiment classifier for a very specific task inlcudes English communication b/w client & team and have only 3500 examples of text annotated. I’m little worried if this much data would be enough to create a good classifier.
@jeremy, I guess this might no longer be on your watchlist but I would like to ask a question that was asked by @martijnd in Jul 2018 but was never answered. hope anyone will pick it up and answer this time.
When we want to train the language model for our own dataset on the wiki103 LM. Why don’t we have to align the vocab of our new dataset (IMDB) with the Wiki103? For example like this. data_lm = (TextList.from_folder(path, **vocab=data_lm.vocab**)
Like we do when we want to initialise the Classifier. data_clas = (TextList.from_folder(path, vocab=data_lm.vocab)
The reasoning is there’s a convert_weights function that takes those WT103 weights (or any LM weights) to our new corpus, see it below:
def convert_weights(wgts:Weights, stoi_wgts:Dict[str,int], itos_new:Collection[str]) -> Weights:
"Convert the model `wgts` to go with a new vocabulary."
dec_bias, enc_wgts = wgts.get('1.decoder.bias', None), wgts['0.encoder.weight']
wgts_m = enc_wgts.mean(0)
if dec_bias is not None: bias_m = dec_bias.mean(0)
new_w = enc_wgts.new_zeros((len(itos_new),enc_wgts.size(1))).zero_()
if dec_bias is not None: new_b = dec_bias.new_zeros((len(itos_new),)).zero_()
for i,w in enumerate(itos_new):
r = stoi_wgts[w] if w in stoi_wgts else -1
new_w[i] = enc_wgts[r] if r>=0 else wgts_m
if dec_bias is not None: new_b[i] = dec_bias[r] if r>=0 else bias_m
wgts['0.encoder.weight'] = new_w
if '0.encoder_dp.emb.weight' in wgts: wgts['0.encoder_dp.emb.weight'] = new_w.clone()
wgts['1.decoder.weight'] = new_w.clone()
if dec_bias is not None: wgts['1.decoder.bias'] = new_b
return wgts
hey i have doubt regrading fastai recommendation model, I have trained the model ,but the problem is that for prediction ,the model only accepts testdata in the form of pandas dataframe,
but the prb is ,i want to predict new products to users , but total users:45000 and total products is 4200 ,then the dataframe will be 45000*4200 ,then the memory is running out ,so is there any other ways to perform inference ,like matrix multiplication user_emb * item_emb, other than passing a dataframe.