I can second that the ‘Deep Learning with Pytorch’ (published recently) is an excellent book with some great illustrations of what’s going on under the hood. Second half of the book is a full project walkthrough.
7 Likes
This line of code from chapter 4 of the book (early on in the chapter) ends with a semicolon.
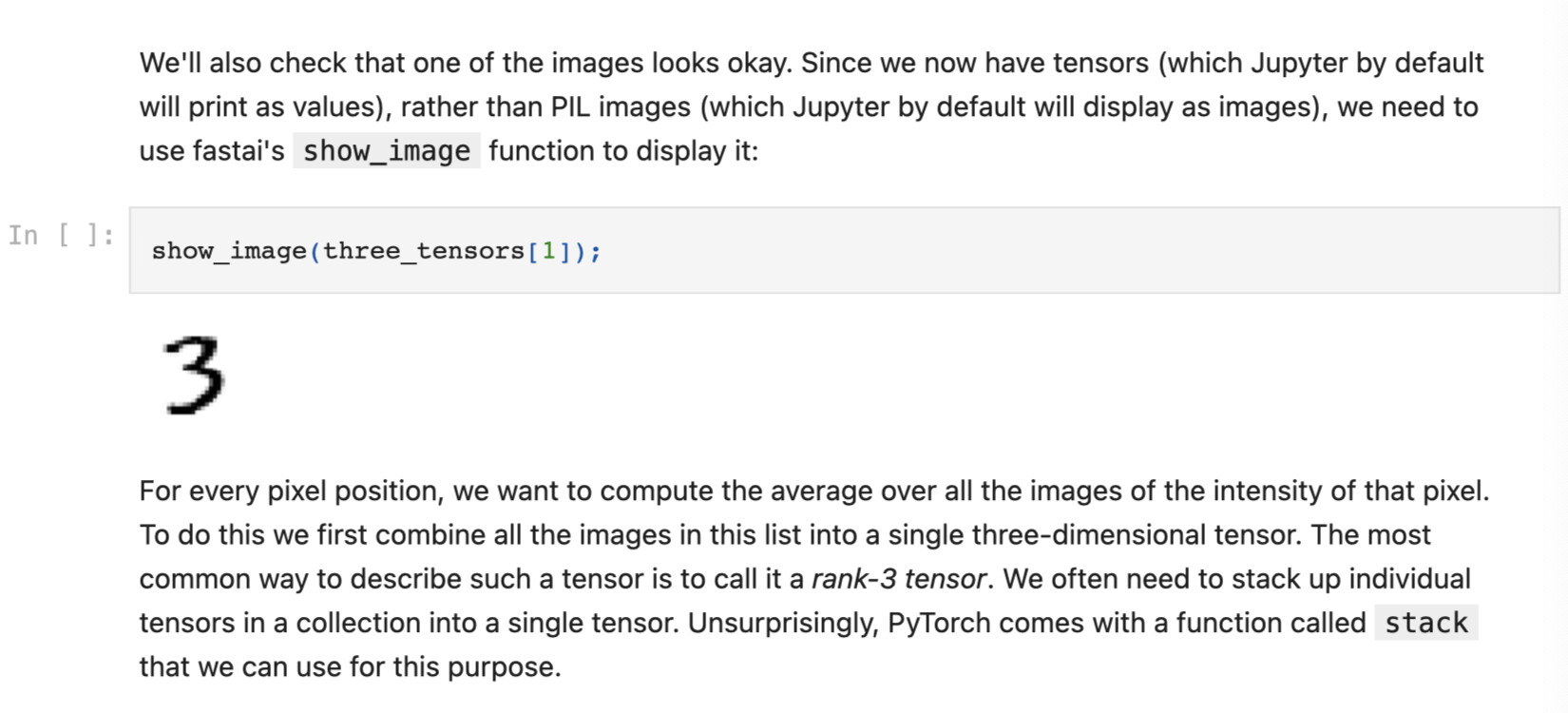
When I search for how semicolon in Python is used in Python I read that it is used to ‘denote separation rather than termination’. When I experiment a bit in my own notebook:
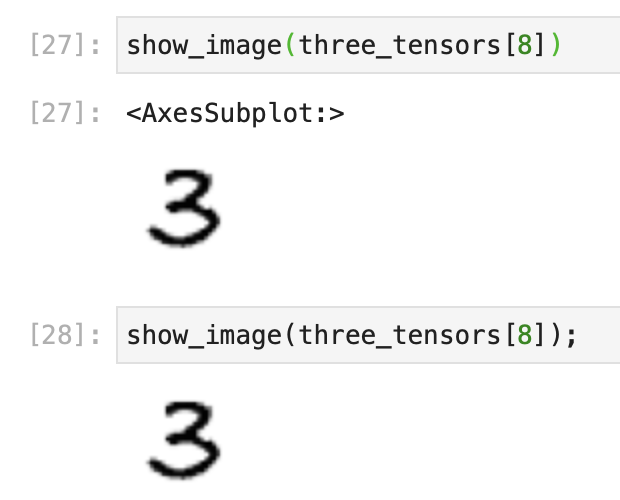
…I see that when you use the semicolon it just displays the image rather than the returned <AxesSubplot:>. Still not really sure why though. I can’t quite understand what the semicolon is doing here. Suppressing what gets returned from the function? Suppressing what Jupyter Notebook displays of the returned value from the function?
When I run
test = show_image(three_tensors[8])
This just displays the image without the axes... string. This to me suggests that the semicolon is indeed somehow repressing what gets returned. Am I on the right track with this?
4 Likes
Given your two minerals classifier images I would say a model would have no problem differentiating. One class have pencils and the other don’t ![]()
Which begs the question, what methods are available for masking the target in an image with irrelevant surroundings that you don’t want the model to train on. To make masking a part of the model processing so that the same masking can be performed on new images for prediction.
Yes indeed. If the function does*(as in side-effects like printing, writing etc.) something, and does not return anything, then there’s no need for this suppression.
When the last statement in a jupyter cell returns a value, then the jupyter env. tries to interpret it so that you can see it. By adding a semicolon to the end, you’re stopping the returned value to flow back to the jupyter “printer” and thus it does not print anything.
Here it’s included as a tip from ipython documentation, pretty sure the feature made it’s way to jupyter as well. https://ipython.org/ipython-doc/dev/interactive/tips.html#suppress-output
And another one, that also talks about using the more explicit pass on the last line of the cell.
https://arogozhnikov.github.io/2016/09/10/jupyter-features.html#Suppress-output-of-last-line
6 Likes
Ah, ok! I guess that the tutorial shared by @stantonius should be a good place to start. I’ve seen it somewhere already but didn’t pay much attention. Thank you!
You may also find this video on how to train an Unet model using fastai and timm useful. I made this few months back ![]()
7 Likes
Train a 2 class classifier one being the recognizable breeds for which we have sufficient examples and another being ‘Not one from the recognizable class’. All methods used for 'Out of distribution" detection are imperfect as what you can get in this class at the test time is very diverse and unknown.
Very well put! This post should probably get much more love than it has
Thanks @ilovescience
I think this post should be pinned somewhere . It has a gist that everyone should be reminded of over and over as we progress through the course.
1 Like
Cool! Btw, I opened the unet_learner source code, it looks like the trick is to provide metadata and cut for a new backbone. (I think I did something similar when tried fastai the last time, when tried to enable some classification backbones that were missing back then…)
And do you have these notebooks available that you demonstrate in the video? Would be great to go over them.
P.S. I think this video could be attached somewhere on the forums (if not yet?), maybe into advanced wiki/docs or something. I believe that the topic of modifying/patching fastai could be quite interesting for some people trying to tailor the lib for their needs.
1 Like
Thank you for sharing! Yeah, I was looking for the notebooks somewhere under the video, in description, but didn’t find any. So decided to ask here. Thanks again!
Thanks to you, I added it now.
1 Like
I am trying to do the sample code for the pets, but I keep getting an error, any suggestions ?
dls = ImageDataLoaders.from_name_func('.',
get_image_files(path),
valid_pct=0.2,
seed=42,
label_func=RegexLabeller(pat=r'^([^/]+)_\d+'),
items_tfms=Resize(224))
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [6], in <cell line: 1>()
----> 1 dls.show_batch(max_n=4)
File ~/miniconda3/envs/fastai/lib/python3.9/site-packages/fastai/data/core.py:102, in TfmdDL.show_batch(self, b, max_n, ctxs, show, unique, **kwargs)
100 old_get_idxs = self.get_idxs
101 self.get_idxs = lambda: Inf.zeros
--> 102 if b is None: b = self.one_batch()
103 if not show: return self._pre_show_batch(b, max_n=max_n)
104 show_batch(*self._pre_show_batch(b, max_n=max_n), ctxs=ctxs, max_n=max_n, **kwargs)
File ~/miniconda3/envs/fastai/lib/python3.9/site-packages/fastai/data/load.py:170, in DataLoader.one_batch(self)
168 def one_batch(self):
169 if self.n is not None and len(self)==0: raise ValueError(f'This DataLoader does not contain any batches')
--> 170 with self.fake_l.no_multiproc(): res = first(self)
.
.
.
.
RuntimeError: Error when trying to collate the data into batches with fa_collate, at least two tensors in the batch are not the same size.
Mismatch found on axis 0 of the batch and is of type `TensorImage`:
Item at index 0 has shape: torch.Size([3, 500, 333])
Item at index 1 has shape: torch.Size([3, 500, 335])
Please include a transform in `after_item` that ensures all data of type TensorImage is the same size
Jeremy prepared the titanic spreadsheet using the sum of squared errors for the loss function, but during the lesson he changed his mind and used the mean squared errors. He said “I guess it’s easier to think about”, but not for me! ![]()
I understand that both loss functions would lead to the same result (in terms of optimal parameters), so why choose mean squared error over the sum of squared errors?
6 Likes
I think that MSE (mean squared error) is kind of easier to think about because it shows an average forecast error instead of a sum of all errors. So essentially, it says that your forecast, on average, misses the truth to a certain margin. And in case of sums, you just have a bunch of summed up errors which is somewhat less intuitive, maybe.
8 Likes
Looks like a spelling mistake. items_tfms should be item_tfms so the resize is not happening ![]() .
.
3 Likes
Wow, great catch. Almost no clue in the error log.
I think it gets easier to read the errors in the error log with more python as well as domain experience. For example in this case, the error log does point in the correct direction. Let’s try to walk through it together. ![]()
This is the first indication that the dataloader was not able to create batches. Let’s just keep that in mind.
Moving on, we can see more errors thrown around why the batches couldn’t be formed. This mentions that tensors that were provided to a batching function were not of the same size, hence the batch cannot be created. As you can see one of the image is 500x333 and another is 500x335, each with 3 channels.
Finally, there’s more information that asks you to provide a transform that makes all the tensors equally sized.
At this point, we know that a batch could not be created because all the tensors were not equally sized.
Now, if we go back to the book, Chapter 2 talks about how this is usually the case, and why the images have to be transformed before feeding it to the network.

And, now that you know that item transforms has the responsibility to do so, you can start looking into the item_tfms and see that you indeed have a typo there.
Now, I’ll be honest. In my experience, typos are sometimes the most time consuming bugs to find, and I have sometimes spent way too much time in tracking them down, the brain simply does not see the typo until you ask somebody else to take a look at it.
This might have been a bit long and winding way to talk about a simple looking typo, but I was just trying to share how I go about reading these error traces. Most of the times, the error traces provides a lot of valuable information, but it does take a while to get used to reading it.
The key really is to not get intimidated and process the error trace one step at a time. Having a understanding of what the code is expected to do also helps a lot, but it is not super necessary.
I hope this was somewhat helpful. ![]()
16 Likes