Thats more or less how I figured it ![]() . Nice summary on how others can do it. IDEs like VScode throw warnings in this case. It will be nice if notebooks can also warn us in some way.
. Nice summary on how others can do it. IDEs like VScode throw warnings in this case. It will be nice if notebooks can also warn us in some way.
5 Likes
Taking the mean brings the final number back to the range/scale of the each item, rather than the sum which can grow unbounded. So, the number(mean) itself is comparable to each item(squared error) and easier to intuit/reason about, esp. when you want to answer the question "what does this final value mean in terms of each item ?"
Here’s a quick sketch I’ve done of the idea.
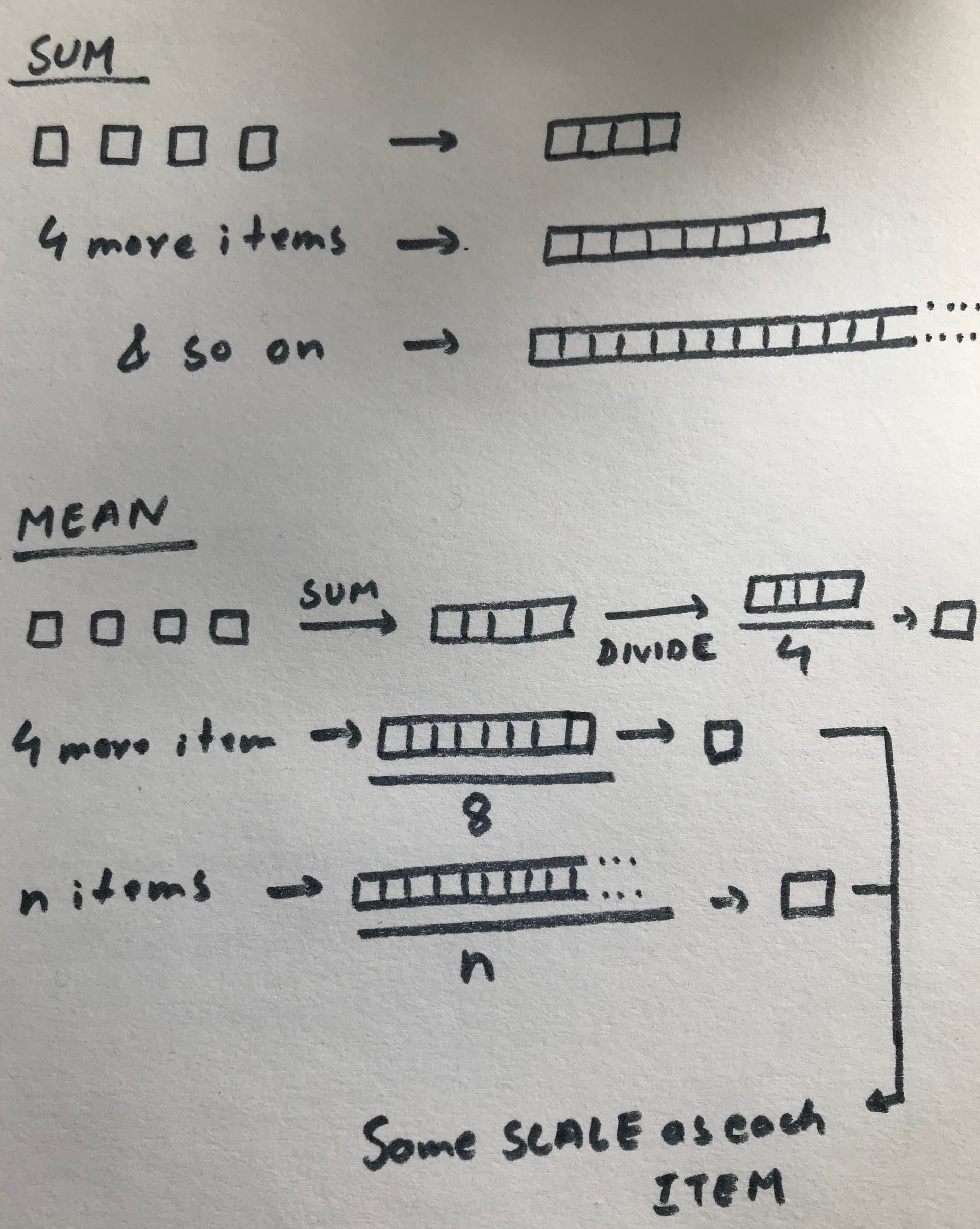
13 Likes
I wish I’d said it so clearly in the class! ![]()
10 Likes
Great reply. In general, I think that comments about how to develop and expand the correct frame of mind are perhaps the most useful.
5 Likes
Dear @suvash, thanks a lot for the explanation!!! I appreciate you taking the time to write it.
I was trying to follow @jeremy lesson 3 video as I don’t have a link for the notebook, so I was pausing the video and writing the code on my Jupiter notebook, in a Linux 20.04 WLS2 with python 3.9.
the RegexLabeller(pat = r’^([^/]+_\d+’), just did not work on my computer, so I went back to the other lessons and saw he is working with the same dataset on lesson 1 notebook 01_intro.ipynb where he has the solution to the problem.
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path,
get_image_files(path),
valid_pct=0.2,
seed=42,
label_func=is_cat,
item_tfms=Resize(224))
The other thing that is different is that when he does timm.list_models(‘convnext*’) I get a different list than the one in the video, so the convnet model he is using in the video does not show on my computer, this is the list I get.
timm.list_models('convnext*')
['convnext_base',
'convnext_base_384_in22ft1k',
'convnext_base_in22ft1k',
'convnext_base_in22k',
'convnext_large',
'convnext_large_384_in22ft1k',
'convnext_large_in22ft1k',
'convnext_large_in22k',
'convnext_small',
'convnext_tiny',
'convnext_tiny_hnf',
'convnext_xlarge_384_in22ft1k',
'convnext_xlarge_in22ft1k',
'convnext_xlarge_in22k']
I guess timm deleted some libraries… I used:
learn = vision_learner(dls, 'convnext_xlarge_in22ft1k', metrics=error_rate).to_fp16()
learn.fine_tune(3)
|epoch|train_loss|valid_loss|error_rate|time|
|0|0.028527|0.000062|0.000000|00:59|
|epoch|train_loss|valid_loss|error_rate|time|
|0|0.003505|0.001061|0.000677|01:21|
|1|0.003855|0.006161|0.000677|01:39|
|2|0.002579|0.005499|0.001353|01:21|
I really liked the link for the news models it is amazing how well they work.
I don’t understand why on my computer things are different but found a workaround.
Thanks again!
1 Like
In the course video (and the Kaggle notebook), you can see that timm is installed directly via Github url, instead of the usual pip install ..... This installs the latest version directly from Github.
The official version released on PyPI (that pip install timm gets from) is a bit lagging (last released in January as of today), that could be the reason you don’t see the same list.
5 Likes
Great explanation!
Indeed, that’s why there are known benefits of the concept of “pair programming” from the software development world, which can be “borrowed” here. Its awesome to see how this concept is essentially being implemented in this platform - great community, all! ![]()
1 Like
I have a few questions please:
When working on projects in general:
-
Is it fine to use fast.ai (deep learning essentially), and Not first attempt other machine learning algorithms like the logistic regression, etc from example, Scikit-Learn? Like for instance, if we try to publish results with a journal, then the reviewers may come back with comments such as why did you not try the other models first OR even, why were the other algorithms not even part of the attempt to solve the problem, etc - any advice please? Basically, is it essentially okay to just use fast.ai only? And then what about the above concern?
In general, I’d like to obviously use fast.ai for ‘fast’, (pun intended! ) awesome results - but please kindly advise on the above?
) awesome results - but please kindly advise on the above? -
On a similar note, I know that there are recent libraries like gradio and streamlit that makes development of applications powered by models, easier and more efficient to do, etc. However, when building an application for the real world for production, is it still okay to just use streamlit, for example? Instead of using say, Django, etc?
-
From point (1) above, if for example, one tries out different machine learning algorithms like logistic regression, decision tree, support vector machine, etc, (say, from Scikit-Learn) and create a model using fast.ai - so in this example, say there are 4 different models here. Then, we get the machine learning metric to evaluate a model - say for example, accuracy. I wanted to find out, that beyond this, does one also in general, have to perform statistical analysis to compare the models’ performances? I was doing some reading/ research and came across this statistical concept sometimes, but unsure what is best practice and whether this is needed in general? Kindly advise please.
Here is one example of the statistical aspect I am talking about: Hypothesis Test for Comparing Machine Learning Algorithms
Should we stop at getting the metric at the machine learning or deep learning level, OR, when doing different models based on machine learning and deep learning, then, should we go one step further and do the statistical test(s), re: the example resource mentioned on the link above?
To my knowledge, most of the papers in research do Not do the statistical added step above - therefore, I am querying about it - whether its best practice and should we do it? Also, from both an industry and research perspective? -
Last question for now please: for lesson 3 (the last lecture), we focused on chapter 4 of the fast.ai book. So, we skipped chapter 3 on ethics - will this be covered later in the course in the 7 weeks? Or, should we read-up on it and cover it on our own after the 7 weeks (if we don’t get time during the 7 weeks)?
Many thanks in advance. Much appreciated.
2 Likes
Oh, besides the notebook for the next lecture, do we also have to go through the next chapter (will it be based on the next chapter, chapter 5 of the book?) as well?
Chapter 3 is an amazing chapter! It’s really good reading and I think it would be good to read it and read it and re-read it as we’re going through the technical side of things. I was just reading through parts of it yesterday and I always find it interesting and enlightening.
Dr. Rachel Thomas’ lecture from 2020 version of the course is available here:

1 Like
The notebook is in the Spaces repo linked in the top post of this topic. Let me know if you have any trouble accessing it.
1 Like
Logistic regression is the same as a neural net with no hidden layers, which means it’s easy to do logistic regression in fastai. It’s worth including as a baseline in situations where it makes sense, like tabular analysis.
We’ll be talking about some other algorithms later in the course.
Generally, it’s important to compare to whatever the current state of the art approaches are in your field, and whatever the most commonly used approaches are.
5 Likes
Yes if streamlit provides the functionality you need, it’s absolutely ok to use it!
1 Like
Probably now. If the models are so similar that you need a statistical test to see whether the difference is real, then it’s likely to be not a practically significant difference anway!
Furthermore, a statistical test doesn’t make much sense here - what’s the “true population” that you’re sampling from? Instead, you should test on a range of datasets that are representative of the kind of problems your model is designed to solve.
5 Likes
It’s certainly well worth reading, although it’s not something that I feel video lessons add much to – in this course I’m trying to focus on using code, spreadsheets, etc to explain things in an environment where students can experiment and learn. Chapter 3 is probably best presented as a book chapter, not as a video.
I do plan to touch on concepts from chapter 3 integrated into other lessons, however.
6 Likes
The next lesson will be largely new material.
4 Likes
Thank you very much, Jeremy, for all your help, advices, responses, for this course and etc so far. Much and truly appreciated.
The best lecturer I’ve ever come across by far!
6 Likes
And thank you for your thoughtful questions! ![]()
2 Likes
Oh BTW you can also pre-read the notebook for the next lesson if you like, which is listed here:
3 Likes