I just saw something very cool:
Its a library that can automatically optimise your models and they have a FastAI notebook example!
I just saw something very cool:
Its a library that can automatically optimise your models and they have a FastAI notebook example!
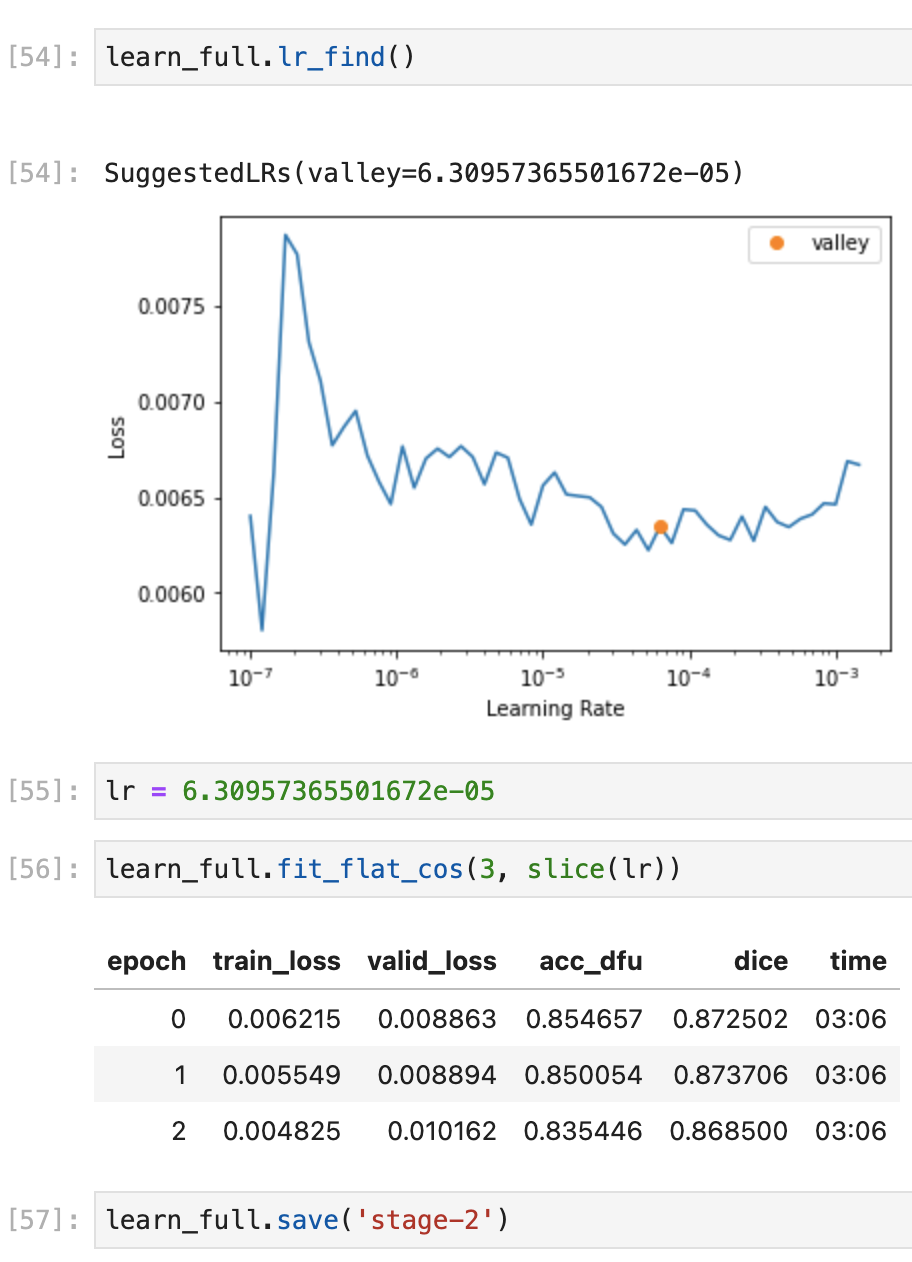
I am trying to recreate results for this challenge:
I got about ~ 0.87 DICE score on the validation set with Fast AI!
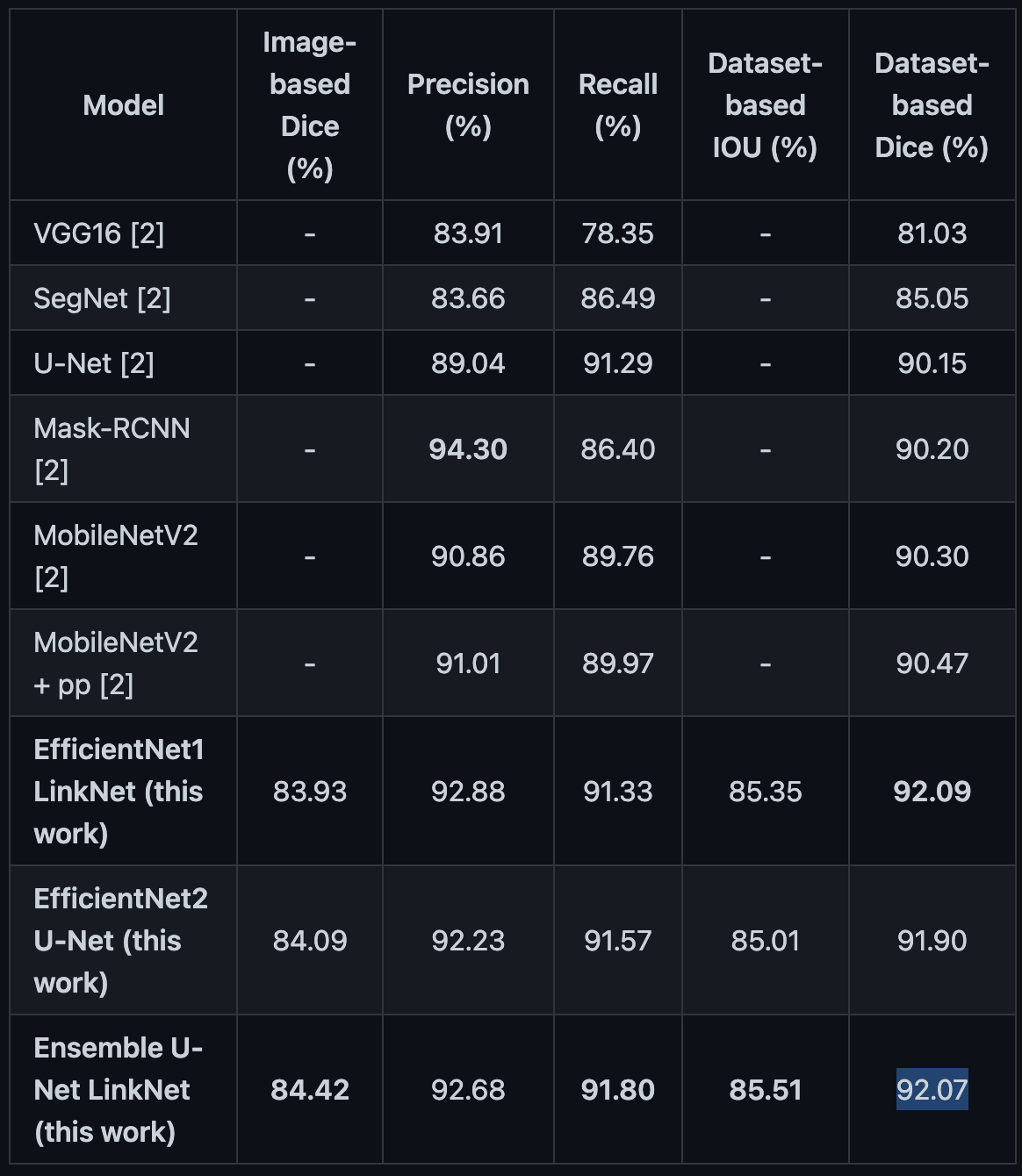
This repo was the winner but its not clear what these two scores mean.
Does anyone know what Image Based DICE vs Dataset Based DICE would mean?
In the titanic example the error is based on the average of loss between rows 662 and 714. I’ve found the error, and the optimisation, is quite sensitive to what rows are selected to form the average. For example, if you pick rows 21 to 541 then your optimised error is 0.14. If you add one row to the original set (i.e. 661 to 714) the error drops by 1%. If you pick the lot, then the optimised error is 0.13.
I understand the point of the exercise is to compare the error of a slightly more complex model vs a linear one, so the rows selected to calculate error need to be the same. However considering that we have a test dataset, how come we don’t use the entire training dataset to calculate training error? I assume there’s a good explanation for this, so it’s handy to ask in case someone else encounters the same doubt.
It’s also interesting how volatile the error is. The way I found this is when I was trying to play around and use the length of people’s names (as a proxy for poshness) as a factor. When you look at a boxplot of death status vs name length, it does show a relationship (longer names have a higher median and interquartile range). But when I tried incorporating it into the model my error wasn’t performing as well as Jeremy’s. It seems as if a different sample has a big influence on the training error, and that despite name length (divided by 82 which is the maximum name length, and for a bit of fun subtract the mean of the set to make it hover around 0) appearing to have a correlation with death, it just made the model perform worse. I’m assuming this is because I didn’t do the same exploratory analysis with other variables and the correlation between name length and death is weaker and drags the model down.
I welcome everyone’s thoughts!!
very cool indeed … according to the fastai example, it seems to be very straight forward to use. thanks for sharing!
that’s really neat. I’m also planning to run some tests later today on some notebook I have in place to test this. what about training time ? is it comparable too, i’d assume it to be slightly longer ?
That was a bug on my part - well spotted! Fixed now in the repo.
Search Youtube about an interview that Jeremy gave to Lex Fridman. He talks extensively about this, mainly in nontechnical terms.
Firstly, as you progress in the book, you’ll use Pyorch quite a lot. As Jeremy said elsewhere, you will actually implement a lot of fastai’s core features from scratch.
Anyway, if you are enthusiastic and impatient about it… There is a 60-minutes Pytorch blitz written by Jeremy. It’s on Pytorch’s site. The official tutorials are also good.
Our @VishnuSubramanian has actually written a book about Pytorch, search for it.
I would not recommend reading it though ![]() it is outdated and there are way better resources now.
it is outdated and there are way better resources now.
Why do you think this library is a interesting? As there are lot of options to make inference faster like ONNX, OpenVINO, TensorRT etc…
On a quick look it seems it supports some of the Deep learning compilers and looks like a high-level API. @madhavajay would like to hear your thoughts
Would you kindly mention some of the beginner friendly resources ?
Thanks,
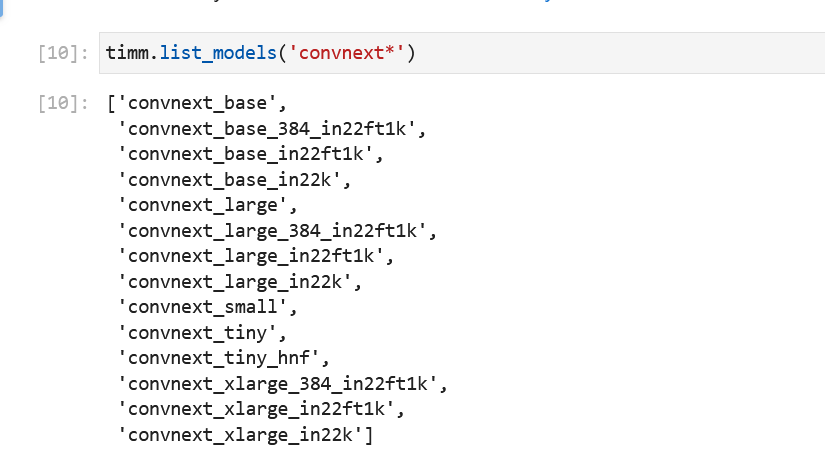
I noticed some of models in convnext, which jeremy showed in lesson are not there like specifically convnext_tiny_in22k.Did anyone notice the same?
I installed from github main, so I guess Ross added some models recently and hasn’t done a release since.
Could you please remind me, how I can use timm models with fastai? I’ve installed the package as usual, and trying to create a (U-net-)learner as follows:
learn = unet_learner(dls, "convnext_tiny")
However, this line fails.
Traceback (most recent call last):
File "...", line 33, in <module>
train()
File "...", line 27, in train
learn = unet_learner(dls, "convnext_tiny")
...
model = arch(pretrained=pretrained)
TypeError: 'str' object is not callable
I suspect that not all architectures supported for U-Net learner, as it requires extra U-shape connections. Otherwise, it would work, right?
Also, do you know if it is possible to use some other third-party libraries to integrate with fastai, like segmentation_models?
Not sure if this is what you’re after, but there are a couple of examples on how to incorporate Huggingface models by the fastai team and Zach Mueller:
I assume using any other model library is roughly the same principles as described here.
EDIT: @devforfu - I’m struggling with replies here for some reason so tagging you ![]()
Unet doesn’t support timm yet
Fastai book along the course itself will teach you a lot about PyTorch. If you want to explore further, you can look here at PyTorch tutorials and this book written by some of the core contributors of PyTorch.
I will take a look when I get a spare moment to try it out, but historically I have struggled to get these kinds of performance optimisers to work as expected. Never the less I have never seen one which actively shows a tutorial for Fast AI, so I figured it might be of value to people here in squeezing more out of their models, particularly on edge devices.