That’s interesting. If I were to bring human analogy here, all of us may be biased in some sense but merging all of our experience can bring a super-human who’s perfect than average humans! 
I had by mistake typed 3 cycles instead of 1. While each cycle takes 30 minutes, I’m wondering If I can interrupt Kernel and I expect the learn to retain the knowledge from 1st epoch.
Yes, you are right. It’s similar to an ensemble effect. Similar to the effect; each tree in a random forest brings to the overall model. You could build multiple NN models, which would have had different individual weights to start with (due to randomness) and when you average all of them, the averaged model kinds of smooths out the tiny errors caused by each model and most of the time you see improved losses / better accuracies.
1 Like
You can interrupt the kernel anytime by clicking this icon on the menu bar of the notebook.
Re-initialize the learner to be on the safer side and you should be good to go!
.

Double checking… we average the log_preds from various models?
I usually convert the logs to probabilities before taking the average.
probs = np.exp(log_preds)
Then if you had a few model probabilities:
avg = (prob1 + prob2 + prob3) / 3
2 Likes
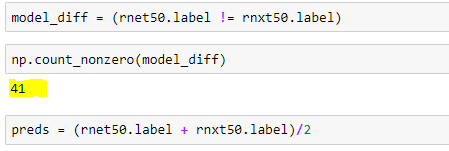
Great! I found 41 variations between resnet50 and resnext50!
~0.0011 improvements in log loss! Thank you! 
1 Like
Am I interpreting this correctly?
We will train different models on the same dataset and then we will predict on the test values by each and then average them and update the sub.csv accordingly?
What i was doing previously was combining excel’s manually…
Yep thats correct! You replace the previous single model predictions with the average of all of the model’s predictions and that becomes your new submission to Kaggle.
2 Likes
@jamesrequa, while Im hopeless in reading Python code I can answer 100% sure that any transformation (non related to image augmentation) that you do to train must be applied the same to test set for prediction.
Also I noticed that if you resize data previously to increase speed like planet notebook does the temporary file includes resized test, what I take as a confirmation of this.
2 Likes
… unless one of those humans is Einstein and the topic is Physics ![]()
1 Like
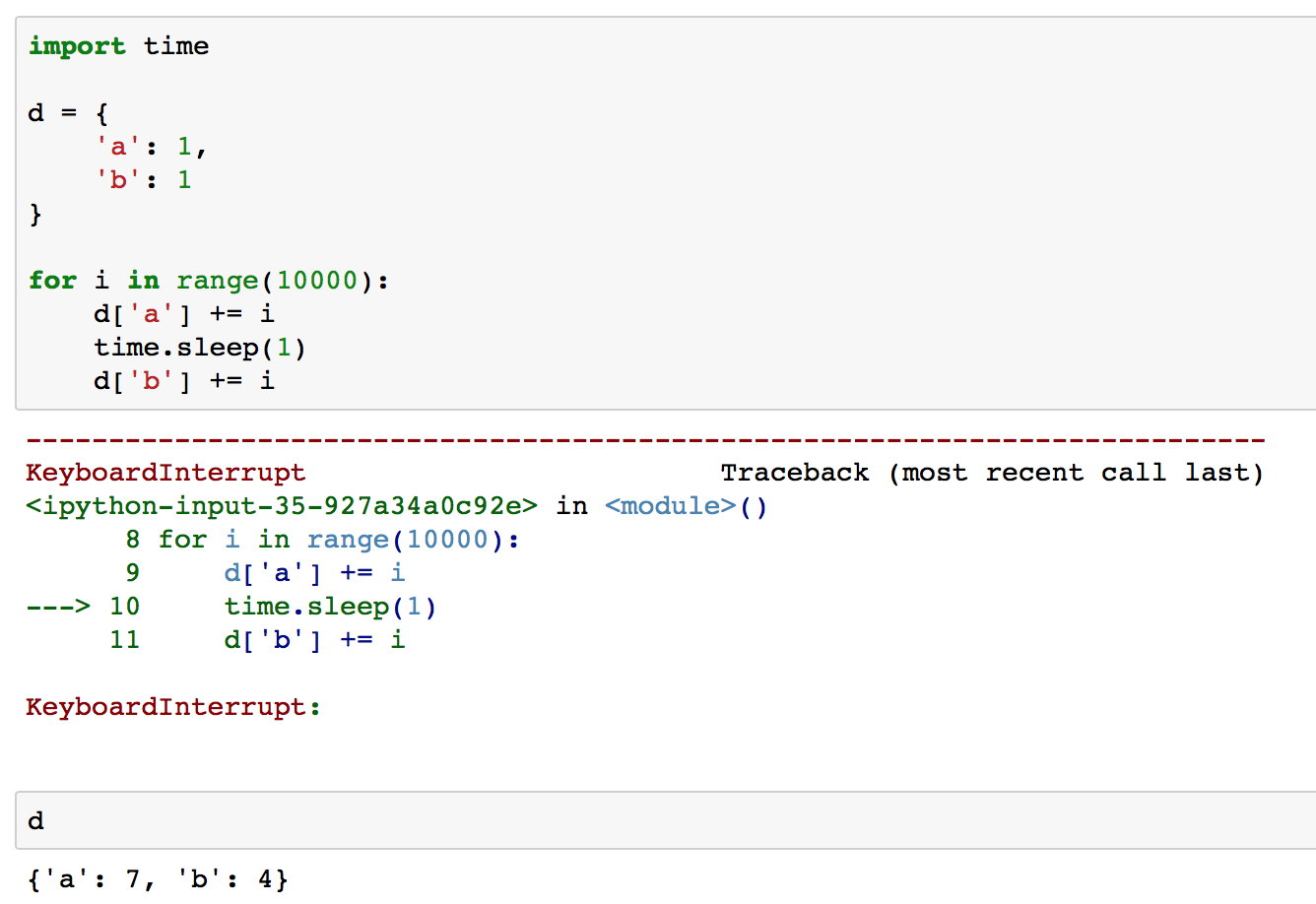
Most likely, you can expect the learner to have weights from first epoch. But cannot be guaranteed that it’s in a stable state. In the example below, I have a dict with two keys - a, b. Both should have same value at the end of the for loop, but because I interrupted the cell, the values of a and b are inconsistent. But d is still updated. Hope this is useful.
1 Like
I generally prefer the from_csv method of ImageClassfierData so that I don’t have to move the files between Train and Valiation. You can modify the val_idxs to one value say [0] (just the first image in the csv dataset. But if you are using from_paths, you may need to move or copy the files. But please note that you will be Overfitting to Train (which is now Validation data), so the metrics like Val. Loss and Val. Accuracy are not meaningful anymore if you copy validation images to Train.
I don’t know of any scenario where this will be useful. So, unless you have so few images that you can’t afford to have a validation set, I would avoid merging validation and training data. Because what I really care about is performance on TEST Data (unseen) data and having a Validation data that’s similar to Test data is the only way to ensure you get your expected performance on test data.
Idea is that once you train model with train and Val set, oprtimize it. Once you’ve the best model, rerun same steps by moving validation data into test data. That’s like restarting the whole process.
In actual validation data is for us to evaluate model or for model to learn some of the parameters.
I have seen that technique used in Traditional methods like Trees, Logistic Reg etc. My main concern is, if you add Validation data to training process and adjust weights by running for few epochs, it might start to slightly overfit to the validation set and we no longer know how it will perform on Out of Sample data (test). May be that’s what we have to do when we don’t have lots of data to train on.
I don’t think I am clarifying anything for you other than stating that I would also like to hear what others think about this process.
I heard Jeremy saying (unsure of what I inferred is what he said) something like this so thought of trying. Thanks, Ramesh.
Yes I did. We had some earlier discussions on the forum about this - hopefully one of you can find and link to them… ![]()
1 Like
Changing the size ‘sz’ during the training phases seems to me quite remarkable.
Is that possible because of the structure of resnet which is kind of size-agnostic up to some layers?
Anyway it is still unclear. My understanding is that after the training at sz=64 we can provide to the same learner double sized images. The firsts layer-‘filters’ have constant dimensions hence producing bigger activation images, but at a certain point the final layer must have the correct number of labels.
Is the network structure changing somewhere (thanks to fastai sw) or resnet is that flexible?
Thanks
Video timelines for Lesson 3
-
00:00:05 Cool guides & posts made by Fast.ai classmates
- tmux, summary of lesson 2, learning rate finder, guide to Pytorch, learning rate vs batch size,
- decoding ResNet architecture, beginner’s forum
- 00:05:45 Where we go from here
- 00:08:20 How to complete last week assignement “Dog breeds detection”
- 00:08:55 How to download data from Kaggle (Kaggle CLI) or anywhere else
- 00:12:05 Cool tip to download only the files you need: using CulrWget
- 00:13:35 Dogs vs Cats example
- 00:17:15 What means “Precompute = True” and “learn.bn_freeze”
- 00:20:10 Intro & comparison to Keras with TensorFlow
- 00:30:10 Porting PyTorch fast.ai library to Keras+TensorFlow project
- 00:32:30 Create a submission to Kaggle
- 00:39:30 Making an individual prediction on a single file
- 00:42:15 The theory behind Convolutional Networks, and Otavio Good demo (Word Lens)
-
00:49:45 ConvNet demo with Excel,
- filter, Hidden layer, Maxpool, Dense weights, Fully-Connected layer
- Pause
-
01:08:30 ConvNet demo with Excel (continued)
- output, probabilities adding to 1, activation function, Softmax
-
01:15:30 The mathematics you really need to understand for Deep Learning
- Exponentiation & Logarithm
- 01:20:30 Multi-label classification with Amazon Satellite competition
- 01:33:35 Example of improving a “washed-out” image
- 01:37:30 Seting different learning rates for different layers
- 01:38:45 ‘data.resize()’ for speed-up, and ‘metrics=[f2]’ or ‘fbeta_score’ metric
- 01:45:10 ‘sigmoid’ activation for multi-label
-
01:47:30 Question on “Training only the last layers, not the initial freeze/frozen ones from ImageNet models”
- ‘learn.unfreeze()’ advanced discussion
- 01:56:30 Visualize your model with ‘learn.summary()’, shows ‘OrderedDict()’
-
01:59:45 Working with Structured Data “Corporacion Favorita Grocery Sales Forecasting”
- Based on the Rossman Stores competitition
- 02:05:30 Book: Python for Data Analysis, by Wes McKinney
- 02:13:30 Split Rossman columns in two types: categorical vs continuous
21 Likes
Thanks @EricPB this is wonderfully helpful! FYI I’ve cleaned up your links and formatting, and also pasted it directly into the wiki post (which is editable by all).
Are you planning to do more of these? They are really great 
3 Likes