No it’s not quite that. There are three ‘layer groups’, but plenty more layers. Try list(enumerate(learn.model.children())) to see what each layer number maps to. Then you can use my code suggestion above with that information. Make more sense now?..
Good resource about optimizers.
3 Likes
That it is  His entire blog is awesome.
His entire blog is awesome.
learn.TTA vs learn.predict
Apart from data augmentation is there any other difference between learn.TTA(is_test=True) and learn.predict(is_test=True) ?
Trying to grasp at least the basics of the code… but still far from it. One important aspect, transformations for image augmentation:
Notebooks of first lessons show the use of “wrappers” like “transforms_side_on”, or “top_dow”, but what if we want to customize the transformations? Like deciding how many images to create by each image, or rotating in some exact angles.
So I had a look at class RandomRotateXY(Transform), and… I dont even get the meaning of the description! 
class RandomRotateXY(Transform): """ Rotates images and (optionally) target y. Rotating coordinates is treated differently for x and y on this transform. Arguments: deg (float): degree to rotate. p (float): probability of rotation mode: type of border tfm_y (TfmType): type of y transform """
What does “rotate optionally the target y” means? how does probability of rotation relates with how many images per image are generated? . What about type of y transform? Sorry if this is obvious for you more experienced ones, I find it tought, maybe someone can share some hint on this particular transformation or about general customization of transforms…
@yinterian showed a little example here: Any Ideas on how to modify Resnet with Images that have 2 channels?
Don’t worry about the y piece for now - we won’t need that until part 2
1 Like
Only other difference is that TTA also returns the labels, IIRC.
learn.TTA ~ learn.predict with n_aug augmentations and a mean of the results, as you rightly mentioned. The following three lines show this difference.
Edit: As @jeremy mentioned, targets are also returned!
3 Likes
I wonder we mention preds, y for test set also. Guess, y will be empty set since there won’t be any labels?
Mandatory validation set?
I was trying to improve my model by moving all files from the validation set to the training set.
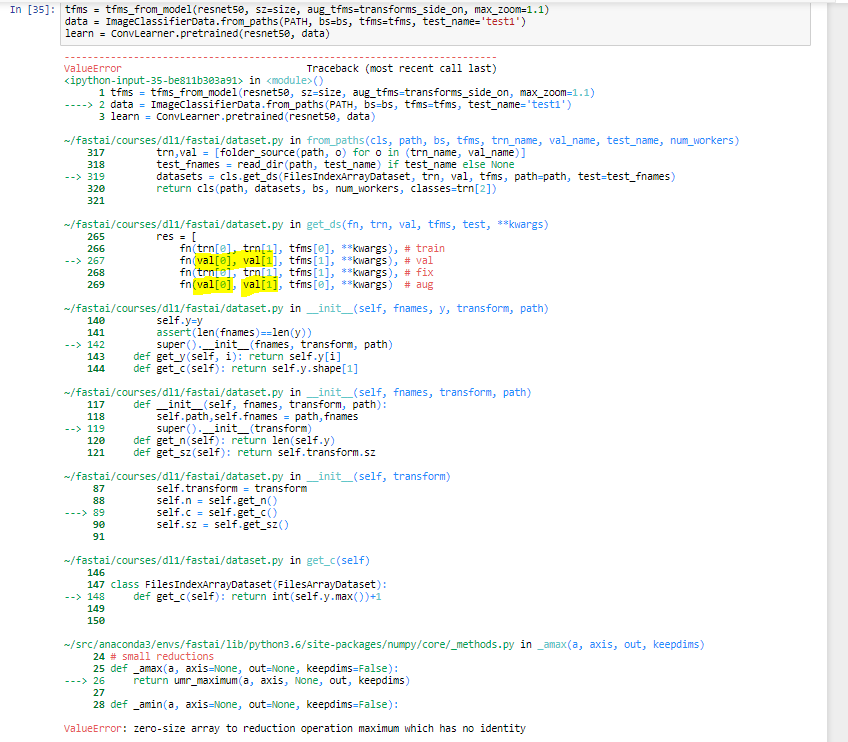
So, should I copy instead of moving files?
If I’m not going to validate (via learn.TTA()) but improve my model by giving it more images, does copying impact it in any way since model will have redundant images?
Is it possible to save the outcome of learn.TTA() for future usage? like we save model e.g. learn.save(‘somefile’)
Got it. It’s zero!
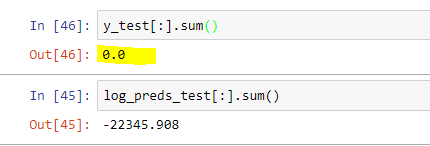
Or, all we’ve is cats!  Biased model
Biased model 
I always use this function to save my prediction arrays to bcolz (it works for any array)
def save_array(fname, arr): c=bcolz.carray(arr, rootdir=fname, mode='w'); c.flush()
Example:
save_array('preds.bc', preds)
6 Likes
If anybody is interested in more image processing / computer vision related problems: here are some from www.crowdai.org -
https://www.crowdai.org/challenges?challenge_filter=active
Didn’t want to create a separate thread for this so posting here…
If we train with image size defined by sz are the test images also made this sz or do they retain their original size? I could see this possibly affecting predictions if for example I trained with a reduced size of 224 and then predicted on test images that were sized 400 or something.
Thanks for sharing. curious if this is how you go about saving predictions from various models, for averaging them later ?
Thank you. I found the counterpart of it in utils.py of part1v1.
def load_array(fname):
return bcolz.open(fname)[:]
1 Like
Yep thats usually what I save them for ![]() Alternatively you can also just save predictions to a csv then read them back in with pandas and pretty easily avg them that way too.
Alternatively you can also just save predictions to a csv then read them back in with pandas and pretty easily avg them that way too.
2 Likes
I think I’ve heard someone asking a question on averaging in the past. Is it supposed to improve the prediction accuracy or reduce loss?
Not sure exactly on those metrics, but I think averaging over various models helps generalize the final resulting model better.
My understanding is that each model 'learn’s different details in the training data, and the best way to bring all of them together, while also preventing the influence of one specific model, is to average them.
I’m pretty sure @jamesrequa can answer this much better than me. Also, please correct me if I’m wrong here.