Has anyone else had any trouble downloading the train-jpg.tar.7z archive that’s shown in the lecture? I was able to download it last week, but now it doesn’t seem to exist. If I run
I ran into this same problem just now with the 404 error. There seems to be a way to still download the two files that we need manually. It’s a much slower process, but in theory we should get the same result in the end.
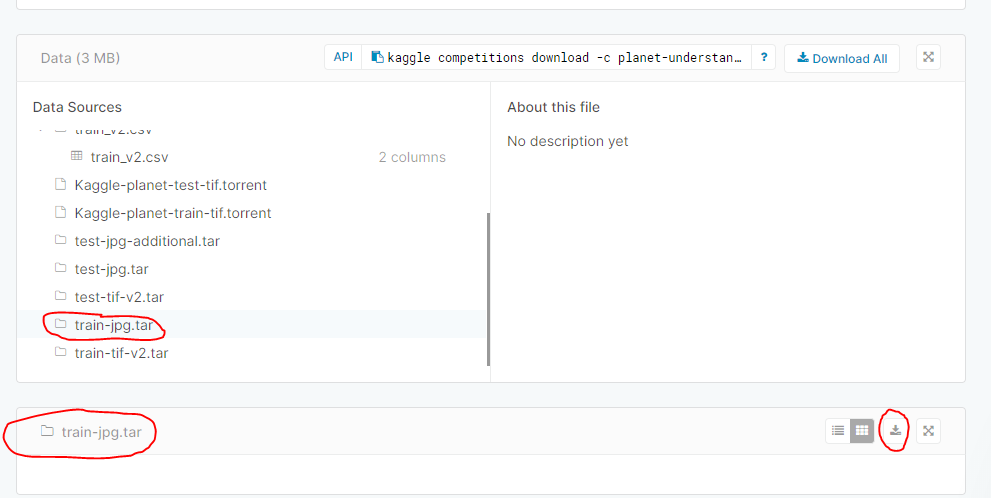
Click on the files that you want to download. You’ll have to do them one at a time. According to the lesson 3 planet notebook, these files are:
train-jpg.tar
train_v2.csv
After you click on the file you want to download, you should see a window at the bottom of the screen with the file name, and a couple of boxes in the upper right-hand corner of the window. One of the boxes gives you the option to download the data.
Here is a picture that hopefully illustrates what you need to do where:
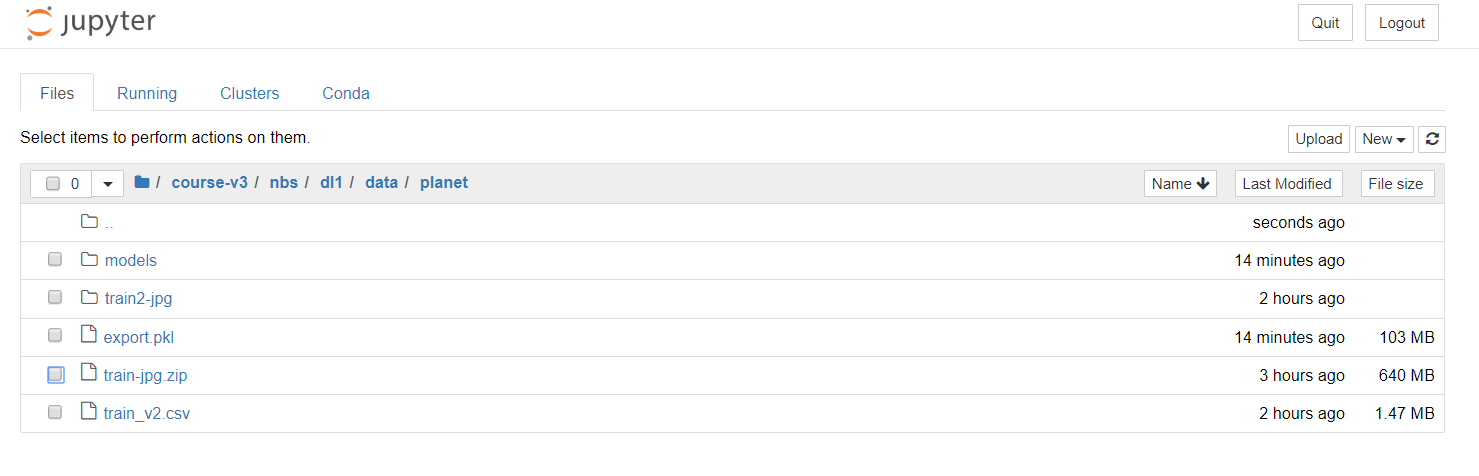
I was able to download the files manually, and am now uploading them to GCP. It’s going to take a while (there might be a more efficient way to do this - curious if anyone has tips), but I think this should allow you to get the data into the cloud in order to analyze it with the lesson notebook.
Just a follow up - I was able to work with the data I got using the method described above. Transferred it to GCP, moved it to the correct folder as described in the tutorial (’/home/jupyter/.fastai/data/planet’), and unzipped it using the conda package referenced in the notebook (eidl7zip).
Am going through the notebook and everything seems to be working!
What I’ve done is to download the train-jpg.tar archive and upload it to Google Drive. Now I can mount my Drive folder from my notebook and use the data from there. It’s a bit annoying because I had to download and upload the data on a slow connection, but once it’s in Drive it’s fine.
I use Paperspace-Gradient. After many hours, I found a rather messy way of doing things, but it does work, for sure: I first downloaded the 2 files from Kaggle, 1 csv file and 1 images’ folder, to my laptop. I then uploaded the zipped version in the data/planet directory.
And finally, unzipped it inside the Jupyter notebook…
unzip -q -n {path}/train-jpg.zip -d {path}
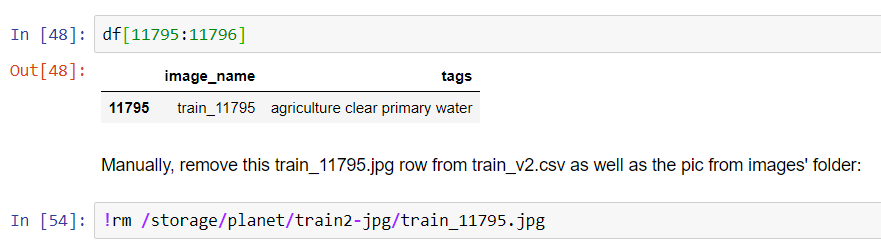
For some reason, train_11795.jpg was giving me trouble. So, I removed that single row from the csv file as well that single image from the images’ folder.
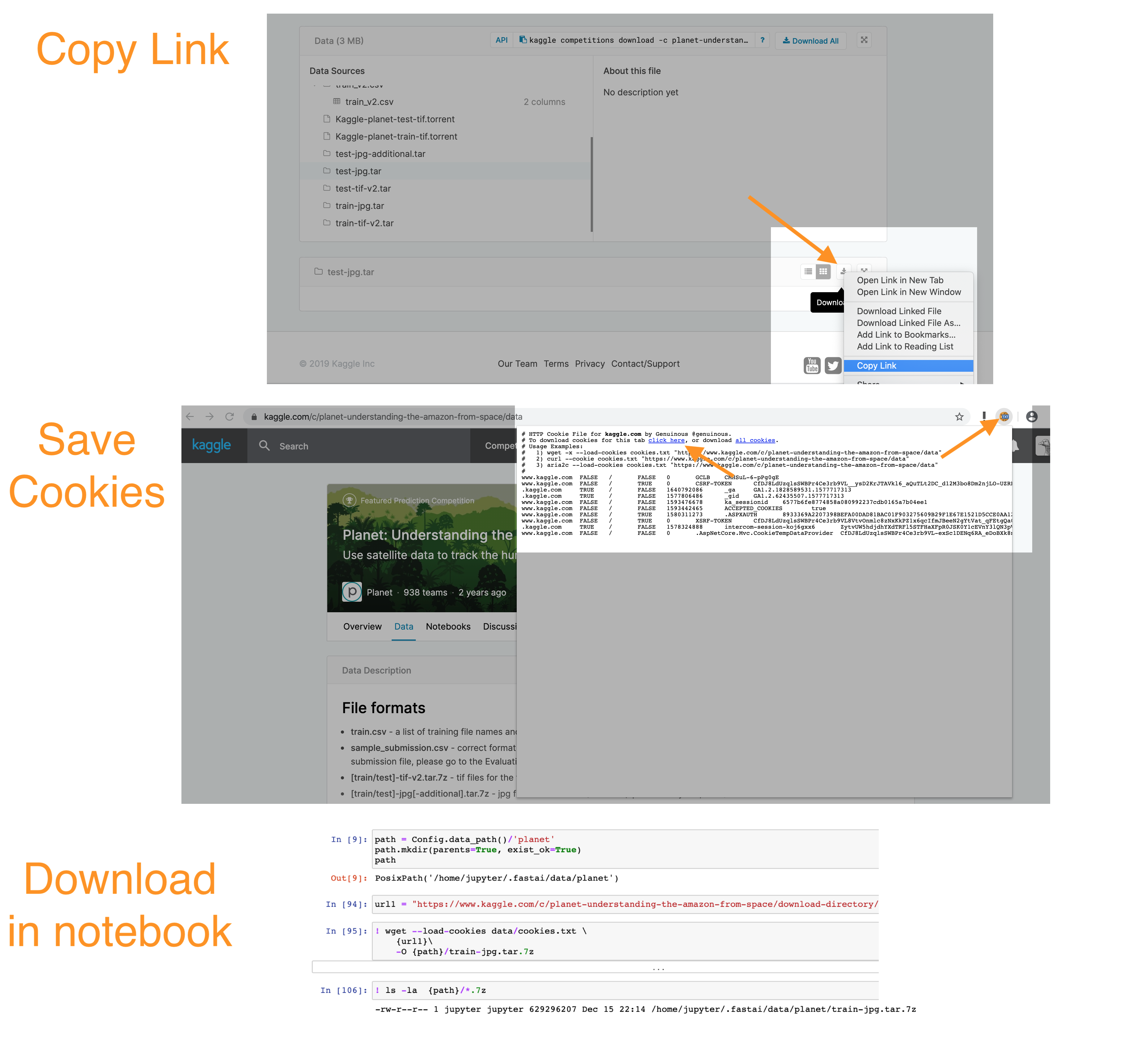
Example of copying download link, downloading the cookies and the resulting script with correct naming (you can do it with the above script, but this makes it a bit easier):
This is just what I did as well (basically). Really odd that the big train and test tar files are no longer a part of the “package” from the kaggle competition download command. That seems to be the main issue. If you just execute kaggle competitions download -c planet-understanding-the-amazon-from-space you get many of the files in the listing but not the test/train data. Strange. Anyway, the only thing I did differently was use the CurlWget Chrome plug-in to actually get the data on my GCP instance. Just posting here as a recommendation to others to use that plug in since it makes it easy to get the data on your actual cloud instance (as long as you are comfortable copy/pasting a wget command in to a terminal).
@Jonny5
Thanks for your solution. I was able to download the .tar.7z file after a long struggle.
However, now when I tried to unpack the file from {path} through the following command.
! 7za -bd -y -so x {path}/train-jpg.tar.7z | tar xf - -C {path.as_posix()}
I’m getting the following error:
ERROR: /home/jupyter/.fastai/data/planet/train-jpg.tar.7z
/home/jupyter/.fastai/data/planet/train-jpg.tar.7z
Open ERROR: Can not open the file as [7z] archive
ERRORS:
Is not archive
tar: This does not look like a tar archive
tar: Exiting with failure status due to previous errors
Can anyone tell me what is wrong?
Wonder what other people did to proceed.
Now when I checked the size of my path directory, its only 1.6 MB, which is just the size of the .csv file. So apparently, the .7z folder does not contain any data.
Following the suggestion of using wget, I used this to download to the expected folder and without any Chrome plugin:
Go to the contest page
Open Chrome Developer Tools (go to the menu > More tools > Developer Tools) and go to the Network tab
On the Kaggle contest page click the “Download All” button in the Download section
Cancel the download, click the “download-all” row in the Developer Tools and look for “cookie” under “Request headers”. Copy all the content of the “cookie” header and replace “PASTE_THE_COOKIE_HERE” in the command below
Get the download link of the file by right clicking the download button for the “train-jpg.tar” file and replace “PASTE_LINK_HERE” in the command below
Paste this whole command in your jupyter notebook and it will download the set to the expected folder
hey @methodmatters! i’m a bit of newbie here. how did you upload the file into gcp? i’m trying to figure out how to access the folder ’/home/jupyter/.fastai/data/planet’. Thanks!