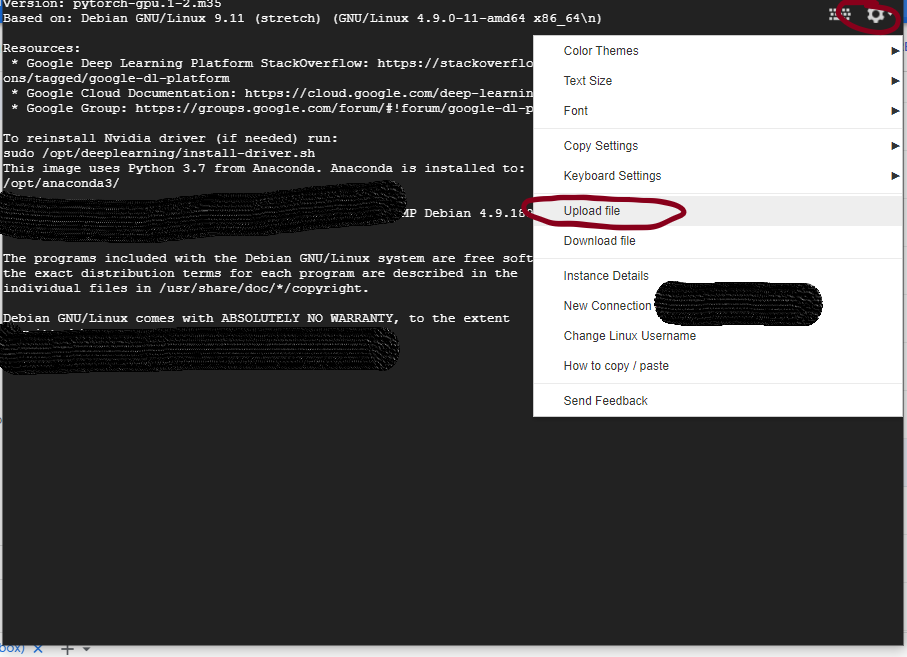
Long story short - SSH into your virtual machine. From that window, you can choose the “cog” in the upper right-hand corner. This will give the option to manually select which file to upload. You can navigate to the file on your computer, and ask it to upload.
This will upload the file into your root directory in GCP. You’ll need to manually copy the files to the directory referenced in the notebook. Nothing hugely complicated here. Again in the SSH window you created earlier, you can navigate to wherever the file is and move it to the correct directory (whichever one is referenced in the course notebooks). The commands are basic linux - e.g. cp for copy, mv for move… A quick google search should get you the basics of how it works…
Just in case if people ask and use colab. If you search my post on lesson3 on the forum, you will see my upload of the training dataset to my google drive and I shared it.
Hi @sergiogaitan, Need your help
when we upload cookies.txt file manually from our local machine, it uploaded in content folder…
then, code:- ! wget --load-cookies content/cookies.txt \ {path} \ -O {path} /train-jpg.tar
is correct ?or we want to first move cookies.txt in .fasai/data directory ?
Yes - I am having massive problems with the download process. I love the tutorials but I must admit I am losing massive amounts of time when I try to get the requisite datafiles into my notebooks. So nothing to add except a feeling of extraordinary frustration!
Have you search on the forum that someone uploaded it the training file for you on drive? Or you want people to upload it on Dropbox for you, so you don’t need to spend time to check the Google drive?
Hi @PalaashAgrawal Did you manage to solve it? I’m facing the same problem on Colab. I did what @Jonny5 was proposing but I did not get any error though. But still is not working.
You can try a simpler solution. Someone uploaded the dataset separately as a zip file. https://www.kaggle.com/nikitarom/planets-dataset
You can get this file using the wget command, or the Kaggle API command directly.
CHeers
I found a solution.This applies to any Dataset from Kaggle.So is a permanent solution(Used in Google Colab)
go to the competition page where you wanna download the .tar
press f12 and go to network panel
start the download and cancel it
You will see a request called train-jpg.tar.7z?..
right click -> Copy as Curl(bash)
paste it into notebook and put an ! markin front.
Very important: add --get at the end of the command
I dont know much bash but i just experimented around.
Took me 3 hours to find this.Its working smooth
after that you can use:-
!p7zip -d train-jpg.tar.7z
!tar -xvf train-jpg.tar
this will extract the data to your path
Hi, I ran into same error. Here is an approach that worked.
Somehow earlier the file size of train-jpg.tar.7z was showing smaller than that of Kaggle, hence the error of unable to open the file. I changed the method of copying the files over to the remote machine (where I run the notebook).
Steps:
Download the file train-jpg.tar.7z from Kaggle directly.
Copy over to remote machine, using scp command:
gcloud compute scp ~/Downloads/train-jpg.tar.7z @my-instance:/home/jupyter/.fastai/data/planet/ --zone us-west1-b