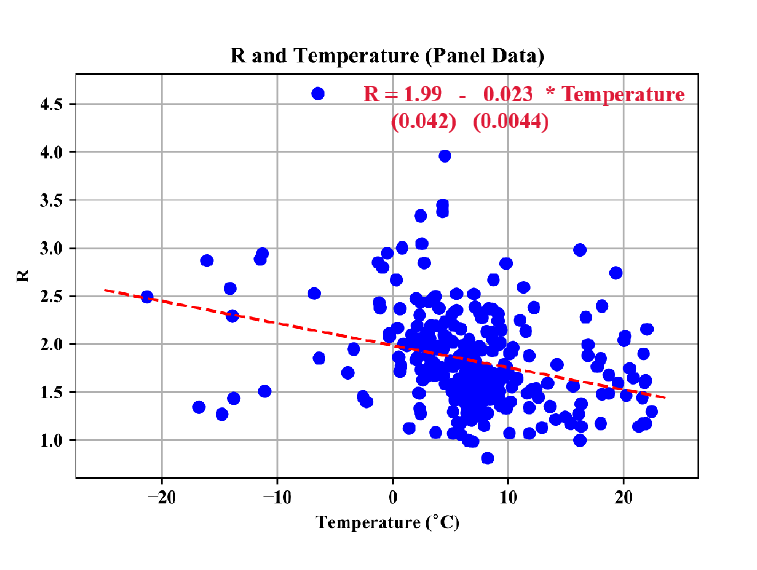
Reposting this here, since it might be a bit much for the beginner discussion:
I wrote a Jupyter notebook How can we determine a p-value for an experimental result? in which I carry out the experiment Jeremy suggested in Lesson 2 in relation to the discussion of Figure 1(a) of the paper "High Temperature and High Humidity Reduce the Transmission of COVID-19"
The result may surprise you!
https://forums.fast.ai/t/lesson-2-official-topic/66294/332?u=jcatanza