I see that DataLoader subclasses GetAttr. Can you explain t a bit?
Can you share intuition behind observing metric vs loss on validation set during training? I thought metric like accuracy is much more volatile, especially if validation set is small, so choosing checkpoints based on minimizing validation loss seemed like a good idea to me.
One thing to consider: let’s for simplicity consider a classification setting. The value of a cross-entropy loss depends not only on whether the image is classified correctly, but also on the confidence that the model has in the prediction. So your loss can increase if the model is getting more things wrong, OR if the model is becoming less confident about some predictions.
Intuitively, the second thing might not necessarily be bad: if the model was overconfident for some reason earlier, it’s ok if it becomes less confident now (and so the loss increases) as long as the prediction is still correct. If you think in these terms, you see how you might get a loss that’s increasing and an accuracy that is improving.
For example, the model might be learning now how to classify well some data points that was getting wrong earlier (which would decrease the loss by a certain amount A), and in order to do so it might need to become less confident about other examples that it was already getting right (which would increase the loss by B). If B > A then you will get a net increase in the loss, but also an improved accuracy.
4 Likes
Hey can anyone point me in the right direction with this:
In chapter one of fastbook, there is this statement
The importance of pretrained models is generally not recognized or discussed in most courses, books, or software library features, and is rarely considered in academic papers. As we write this at the start of 2020, things are just starting to change, but it’s likely to take a while.
My interest is in just how things are changing, are there any papers that are tackling this you can point us to, or are there any interesting ideas that you can share with regards to this.
An example of this is ULMFit paper 
But if I am correct, ULMFit is a 2018 paper
Just because it’s old (three years) doesn’t mean it doesn’t work any more ![]() ULM-FiT was the start of utilizing transfer learning for text data. Multi-FiT just came out in the last year or so which uses this approach for multi-lingual problems
ULM-FiT was the start of utilizing transfer learning for text data. Multi-FiT just came out in the last year or so which uses this approach for multi-lingual problems
I didn’t mean to say that it doesn’t work, what I am trying to say is that, from the book:
As we write this at the start of 2020, things are just starting to change, but it’s likely to take a while.
It says that things are just starting to change in 2020, so I wanted to be shown the things that are happening now in that area.
I had asked this question yesterday and @sgugger had replied. But wanted to follow up here re some clarifications too. Basically I would like to get an intuition about transfer learning and its relationship with neural nets /DL. Per my understanding the concept of Transfer Learning predates DL. They way @jeremy explained it yesterday re using base resnet (trained for a different task) to improve on book/pets detector (which can be argued for classical ML classifiers too. So is there something inherent in the architecture of Neural Networks that make them more efficient to be used for Transfer Learning, compared to say Random Forests / GBTs etc @jeremy @sgugger Thanks!
I am trying to build a databunch/dataloader from already pre-processed data (store as numpy array as x_train, x_test, y_train, y_test). However, I am not sure how to do that as fastai2 expects ‘path’ (of image file names) as input… Is there any way I can feed this already pre-processed data directly to a learner ?
Yes, you can totally do that. Look at the Data block API (https://docs.fast.ai/data_block.html). Jeremy gave an overview at the end of last lesson.
It is referring to the fastai v1. I need for the v2. Moreover, I didn’t get how to pass the numpy array as input to create a dataloader going through the document.
In chapter 7, in the progressive resizing section it says that one should be careful using this on pre-trained models if the transfer learning model dataset is similar to the original dataset in terms of images and sizes as the weights will not change much, and thus if we train on smaller images it might damage the already learnt pre-trained weights.
Is this what Jeremy referred to as ''Catastrophic forgetting in transfer learning" in lesson 2?
Have a look here:
They idea with the synthetic Gabor filters seems to be super useful (see last picture in the blog post).
Be sure to check the publication, as they investigated other interesting concepts too.
1 Like
The docs are fastai v1, but the same functionality is present in v2 (although slightly different). Look here:
(minute 1:23:37)
You just need to create your own get_items (so remove get_image_files and insert your own).
The key here are convolutions, there are basically filters applied to an image (think about an edge detector filter, a corner detector filter, etc…). These guys are extremely useful in any kind of vision task. In the other hand, linear layers are not so “general” at all, remember that when doing transfer learning we just throw all the linear layers away.
For example, there is not a very good transfer learning approach for tabular learning yet. Sure, you can transfer some embeddings, but that’s it…
As for NLP, I’m not the best one to answer because of my limited experience with the topic. I know we have very good transfer learning in NLP but I’m not sure how it works, maybe someone more experienced can clarify it here, I would love to know. Transferring word embeddings is a good start, but I don’t know how to rest of it works.
2 Likes
I haven’t seen examples of using transfer learning for the “classic” algorithms like Random Forest. One of the biggest benefits of deep learning is that it learns how to do the feature extraction that we used to have to do manually. The feature extraction process tends to have some strong crossover (e.g. the convolution layers Jeremy talked about in the last lecture) between different computer vision tasks. If you think about the input to a random forest, it’s typically a little bit more processed that what goes into a deep learning model. My intuition is that most of the value of transfer learning comes from the feature extraction / representation learning, and the downstream classification / regression layers are better learned from scratch.
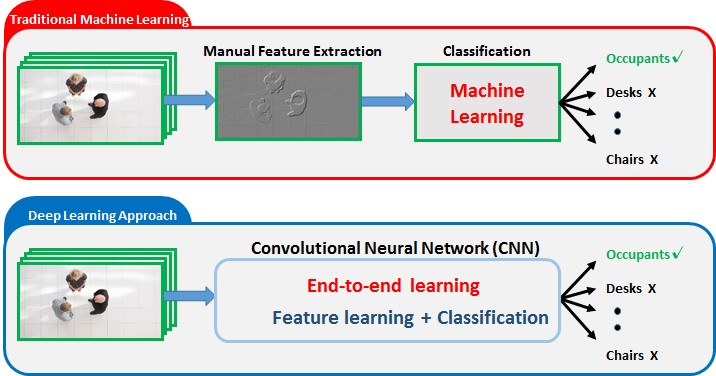
I have seen some really great examples of using a neural network to do the feature extraction / representation learning, and then using those features as part of a more classic algorithm (https://arxiv.org/abs/1604.06737)., but I think it’s much harder to integrate the two and you’d need a pretty compelling reason not to just do it all in one neural network that can be trained end to end.
1 Like
@dcooper01 Daniel There’s a reason for that: the Random Forest is not amenable to transfer learning because a tree model is an ensemble of trees that is specific to the data set used to generate it. For that reason, the weights of the trees cannot be transferred to another RF model.
Reposting this here, since it might be a bit much for the beginner discussion:
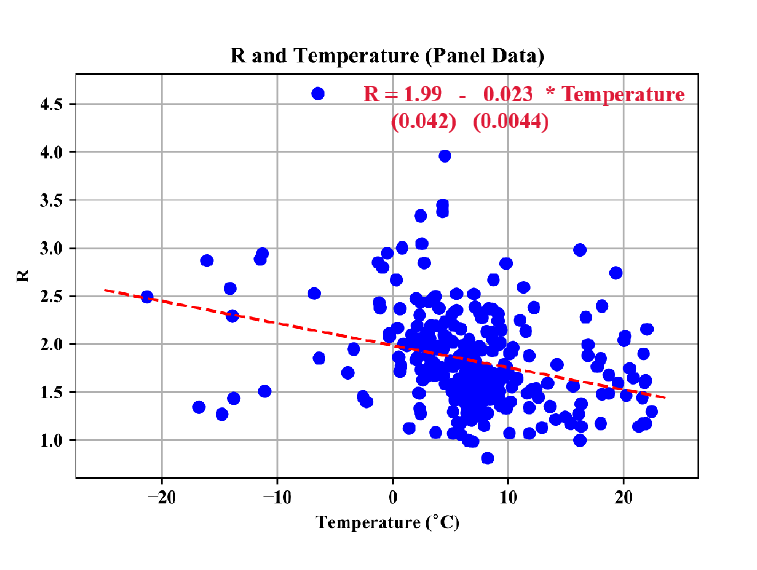
I wrote a Jupyter notebook How can we determine a p-value for an experimental result? in which I carry out the experiment Jeremy suggested in Lesson 2 in relation to the discussion of Figure 1(a) of the paper "High Temperature and High Humidity Reduce the Transmission of COVID-19"
The result may surprise you!
https://forums.fast.ai/t/lesson-2-official-topic/66294/332?u=jcatanza
Follow up:
(1) For some of you, the result of p = 1.e-5 from the notebook might not square with your intuition. That’s OK – as a scientist, it’s your job to be skeptical. Be that as it may, the utility of statistics such as the p-value is that they go beyond our intuition, which is not always well-informed.
The p-value is what it is. There are two possibilities: either I’ve calculated it correctly or not. If you find an error in my notebook, please let me know!
The extremely small p-value tells us that the slope measured in the actual data is significant, i.e. that the trend of R decreasing with Temperature is likely to be real. This conclusion is credible because a trend of decreasing R with increasing T has been observed for other viruses.
(2) In the video, Jeremy generated a 100 null-hypothesis data sets, with100 null-hypothesis slopes to compare with the actual slope from Figure 1(a). As you see in the attached histogram, the slopes from the Monte Carlo ensemble of null-hypothesis data sets fall into a broad Gaussian distribution. A hundred values drawn from this distribution is not enough to tell us whether or not we should reject the null hypothesis, as we’ll see, below.
(3) Jeremy and I are using different distribution parameters for R and T:
Jeremy’s: Temperature: mean, std = (5. ,5.) R: mean,std = (1.9 , 0.5)
Mine: Temperature: mean, std = (7. , 7.5) R: mean,std = (1.75 , 0.35)
As far as I can tell, both are consistent with the original data in Figure 1(a).
(4) So I repeated the Monte-Carlo simulations using Jeremy’s values for the R and T distributions, and to understand the uncertainty in the p-value estimate, I repeated each simulation 5 times:
- With an ensemble of 100 null-hypothesis data sets, p-values are [0.01, 0. 0, 0.03, 0.02, 0.0 ]
- With an ensemble of 100000 null-hypothesis data sets p-values are [0.012, 0.012, 0.012, 0.012,0.012]
From this exercise, we conclude that
- The p-value is sensitive to the assumed distributions of R and T!
- 100 synthetic data sets is not enough to quantify the p-value to two decimal places, so we cannot say whether it is below or above the 0.01 threshold.
- 100,000 synthetic data sets nails the p-value to 3 decimal places – it is (barely) above the 0.01 threshold so we cannot reject the null hypothesis.