Download the weights from http://files.fast.ai/models/weights.tgz and unzip it into that ‘fastai/courses/dl1/fastai/weights/’ folder.
1 Like
Note that Adam does not change learning rates.
Find the algorithm in page 2 (alpha is the learning rate).
3 Likes
Yes, by default the library does center crop.
crop_type=CropType.NO
Would avoid that.
4 Likes
Thank you for confirming! This was very important in my case because the dataset I was working with has crucial information that cannot be left out of the image so cropping hurts the accuracy in that situation.
UPDATE:
@yinterian I just tried using crop_type=CropType.NO and it works when precompute=True but when I set precompute=False and unfreeze() I get the following error message. Any ideas what could be causing it?
TypeError: Traceback (most recent call last):
File "/home/james/anaconda3/envs/tensorflow/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 40, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "/home/james/anaconda3/envs/tensorflow/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 40, in <listcomp>
samples = collate_fn([dataset[i] for i in batch_indices])
File "/home/james/fastai/courses/dl1/fastai/dataset.py", line 99, in __getitem__
return self.get(self.transform, x, y)
File "/home/james/fastai/courses/dl1/fastai/dataset.py", line 104, in get
return (x,y) if tfm is None else tfm(x,y)
File "/home/james/fastai/courses/dl1/fastai/transforms.py", line 488, in __call__
def __call__(self, im, y): return compose(im, y, self.tfms)
File "/home/james/fastai/courses/dl1/fastai/transforms.py", line 469, in compose
im, y =fn(im, y)
File "/home/james/fastai/courses/dl1/fastai/transforms.py", line 246, in __call__
x,y = ((self.transform(x),y) if self.tfm_y==TfmType.NO
File "/home/james/fastai/courses/dl1/fastai/transforms.py", line 254, in transform
x = self.do_transform(x)
File "/home/james/fastai/courses/dl1/fastai/transforms.py", line 330, in do_transform
return no_crop(x, self.sz)
File "/home/james/fastai/courses/dl1/fastai/transforms.py", line 53, in no_crop
r,c = im.size
TypeError: 'int' object is not iterable
@yinterian one more follow up question, sorry!
I noticed in the example you provided tfms = tfms_from_model(resnet34, sz, crop_type=CropType.NO) that there is no aug_tfms being specified. Does this mean that no data augmentation i.e. flips, rotations, etc. are being applied in this case?
Let me look into this. Jeremy just did a big push.
1 Like
I see SGDR as something that sits on top of whatever optimization algorithm you chose - Adam, RMSProp, regular gradient updates. All it does is it varies the learning rate we feed to our optimization algorithm over time.
Probably you could combine this machinery in one but a) not sure what you would gain by it b) probably such combination would be harder to tune and to conceptualize. I think you would also need to add a redundant term, effectively duplicating the functionality we can achieve by fluctuating the learning rate directly.
I can’t understand where that number 3 comes from when we specify learning rates. I mean, why 3 exactly ? Is it just number that generally works well ? Or is it architecture based ?
Also, can we specify not 3, but 2 or 5 learning rates ? Would that work ? How’s fastai library decide what layers belong to what group ?
It is an arbitrary choice that makes intuitive sense and works well. I think this breaks the network into earlier conv layers (the ones which learn low level feature detectors like lines / color gradients), the conv layers that learn higher level features (it is a face, it is a dog, etc) and the fully connected layers that pull all of the higher level features together into making a final choice. So it is an arbitrary choice but the layers are grouped based on their role.
IIRC @jeremy has a nice one or two sentence explanation on this somewhere in lecture 2.
If it is role-based grouping, how do we know which features every layer computes ? I imagine it’d be a lot of work to inspect every model we can use in fastai library this way.
So in theory, we could choose 4 learning rates and pass those to fastai library and it would work ?
We study the models we use so we try to have some understanding about how they behave. And yeah, it is not easy to figure out what happens at which layer and we only can build up intuitive understanding. Though if you would like to dissect a particular network there are ways of doing this as well.
This is the seminal paper on visualizing what happens inside a convolution network. There is also a video on youtube that does the job talking to this very well.
I have not studied the fastai library extensively enough (yet) to be able to tell if you can pass 4 learning rates, but I do not think so. I think that groupings are defined on a per model basis and this particular DNN has 3 groups.
2 Likes
So we use different number of groups for different architectures ?
I want to see the relationship between different learning rates (ie. lr = le-1, le-2, le-3) and number of epochs (say 1-3). Due to initialization with random numbers, the losses and accuracy change every time (see pictures below). Can I use random.seed() to replace random initialization? If yes, where to change it?
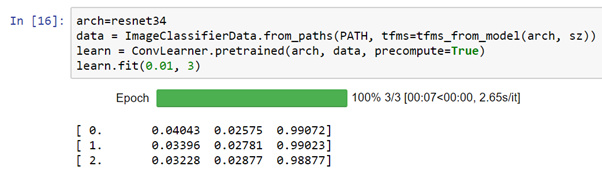
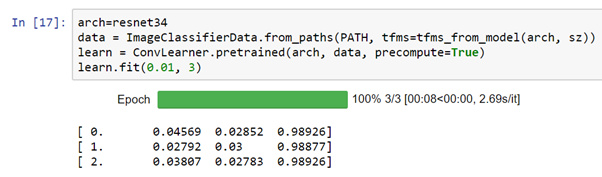
1 Like
There is an issue with using random seeds - I think not everything that happens on the GPU will take the seed into account.
If this is a stochastic process, I think what you could do is just go for multiple runs and average the results. I am not sure however if that would add a lot of value here.
Could you please let me know what it is that you are trying to achieve, what is the end result you are after?
The grouping is - as far as I can tell - something that @jeremy came up with, just something that makes sense, that helps him train SOTA models. I think this is not defined elsewhere as far as @jeremy can tell hence he invents the word for it - differential learning rates.
In the papers that introduce an architecture it is not cut up into layer groupings like we do here. I am also not aware of any other library that would currently support this apart from fastai.
@radek I want to see the relationship between learning rate and number of epoch. In theory, a lower learning rate (say le-3) will take longer to find a local minima; while the higher learning rate (say le-1) will take shorter time. But, by how much? If there is a limitation on GPU, I will take your advice and average the result. Thank you so much!
How are you all testing the model? I tried running the model locally using CPU but could not run any of the class examples successfully. Got out of memory or the process just hung. Are we suppose to validate and test in AWS only? I did not get AWS credit can spend couple of hundred on AWS.
But I thought the whole point is to validate and test code locally first then deploy it in AWS for training. Not sure if you all are modifying the class jupiter notebook to run it on CPU.
Ok, so if I understand it correctly, you are looking for intuition how this works and would like to look at the results to see how things work out in practice?
I think this might be a bit tough with those larger models like we have been using in the course thus far to achieve state of the art results. Also, we use things like batch norm and Adam which both insulate us from many of the difficulties of training a bare bone neural net.
I think you are on the right track though and for the time being I would focus on trying to achieve the best results (best validation accuracy / loss) using the API @jeremy shows in the lectures.
To speak directly to the points from your post (with regards to the learning rates) - a bigger learning rate just means a bigger step in some direction, if we are lucky it will be in the direction of the solution  But it doesn’t necessarily have to be. I think the next lecture or maybe the lecture after that one will extensively describe that I see some xls spreadsheets showing up in the repo which is a sign @jeremy is prepping to take us on a great tour of all of those considerations
But it doesn’t necessarily have to be. I think the next lecture or maybe the lecture after that one will extensively describe that I see some xls spreadsheets showing up in the repo which is a sign @jeremy is prepping to take us on a great tour of all of those considerations  (at least based on what I can infer from watching the part 1 v1 videos )
(at least based on what I can infer from watching the part 1 v1 videos )
1 Like
@rsrivastava the CPU mode has only just been developed by a student and isn’t really tested at all. So I’d avoid it if I were you, since it’s unlikely to be stable at this point!
The expectation is that you do all your work on the GPU. The good news is that I’ve got more AWS credits today! Will send them out soon
4 Likes
Testing a model == evaluating its performance on the validation set / test set.
What kind of computer do you have locally? If it doesn’t have a compatible GPU I think you will run into trouble as the models we use for class will just be too big.
pinging @ramesh to see if maybe he could hook you up with a running machine on AWS
EDIT: was late to the party, the right answer is the one from @jeremy above