Tensor is the generic math name for "arrangements of numbers” of any rank. Some kind of tensors has specific names like “arrays” (rank-1 tensors) and “matrices” (rank-2 tensors), but they are all tensors. Although both Numpy and PyTorch support n-rank computation, they call the class “array” and “tensor”, respectively. Anyway, don’t get confused with the technicalities of tensors and PyTorch, if you are familiar with Numpy, learning PyTorch will be straightforward.
Regarding why GPUs are faster that CPUs for tensors, I’m not expert in hardware/low level programming, but basically GPUs are optimized to execute the same operation multiple times in parallel, which is very convenient for matrix operations and neural nets in particular (tons of multiplications and sums happening at the same time). Finally, Numpy does not run on GPU, since it is not coded to make use of the GPU special hardware. PyTorch instead leverage on specialized libraries (CUDA and cuDNN) provided by Nvidia to squeeze the potential of the GPUs. As I mentioned, I am not an expert, but that’s the general idea.
Hey, I am also facing the same problem. Did you find any solution to this or any workaround ?
Also using download_images, we get this error (Error: “content-length”) but it does downloads some images for you. After this when we use the verify_images it removes many images leaving you with very less images. Anything we can use to solve this ?
I checked out the video and I just need a clarification at 1:29:03 in the video. Could you call call Stochastic gradient descent finding the least squares line? Because from the explanation given that is what’s going on at least according to me.
Hi.
In lesson-2 planet notebook.
We have only training and validation data.
After I’ve trained the model I downloaded the test data and wanted to make prediction on it.
It seems learn.predict works for only one image and learn.pred_batch works only when you’ve passed test set while creating databunch object.
I’ve created databunch object without passing test set. If I want to make prediction on test set without modifying that earlier created databunch object, How can I do that ?
That’s a very interesting point. Gradient descent is just a fancy term for taking the derivative of a function and updating the weights so as to minimize the error between predicted and actual values. So yes, you could call it for any function no matter what that function it is. But for that line drawn at that point in the video, the derivative would be zero. So the weight or coefficient would not be able to be updated, since:
updated_weight = weight - (learning_rate * derivative_with_respect_to_the_weight). This would become:
updated_weight = weight - (learning_rate * 0)
updated_weight = weight
And your algorithm would stop “learning” what is the best value for that specific weight. This is a real problem in deep learning, and people try to select the best function to use so that the derivative never turns out to be 0 during any iteration. The stochastic part of gradient descent just means performing derivatives with random mini-batches of your sample. So if you have 1 million samples, you perform gradient descent (take the derivatives with respect to the weights of the functions used to calculate or predict the output) with 100 random samples, and update the weights for those samples. Then continue with the next 100 random samples and so on.
I assumed the OP, by saying “It gives rate of change of one variable wrt the other” meant 'the rate of change of the function (the independent var) wrt one of its dependents. The OP’ll tell us if I misinterpreted.
I think (but just IMHO) that the gist of the grad is that it gives the global rate of change of the function (a vector is not just the mere list of its coordinates), and always tells you the direction of maximum slope along the (hyper-)surface.
[Disclaimer: I am not a native speaker myself, and my english sucks as well. I posted my reply not because I enjoy being picky, but because it served my purpose of inviting people to try and think more abstractly about mathematical objects.]
Yes. Without the s and assuming one variable as the function, it’s just a partial derivative.
But even adding the s, such description could be misleading: generally, reading variable people do automatically think about a dependent variable (and not the function). I bet that a lot of people construed it as rate of change of an independent var wrt one of the others.
Another point worth to stress is, like I was mentioning, that the gradient is not just the list of all partials, regardless the fact we can hendle it as such for our present purposes.
It is a vector, e.g. an element of a vector space, enjoying a lot of unique properties. It is useful, imho, not to think about vectors just as arrays (lists of scalars), since it spoils the mindset of those who desire to dig deeper in math.
You know, If I was a teacher, I would never give a linear algebra course using the coordinate isomorphism, at least not in the beginning. It hinders people in understanding the gist of vector spaces, and the mappings between them.
TBH, I’ve no idea what you just said I obv don’t know much about the math.
Agree about missing out the ‘s’ though.
IMHO, this isn’t a ‘linear algebra’ course. The aim should be to convey an understandable intuition in the context of ML within a reasonable span of time.
Just reading fancy words like “coordinate isomorphism” and “vector spaces” would be enough to ‘hinder’ many including me. People who want to dig into math will pursue their interests independently.
Hope I don’t come off sounding rude. Just my 2p.
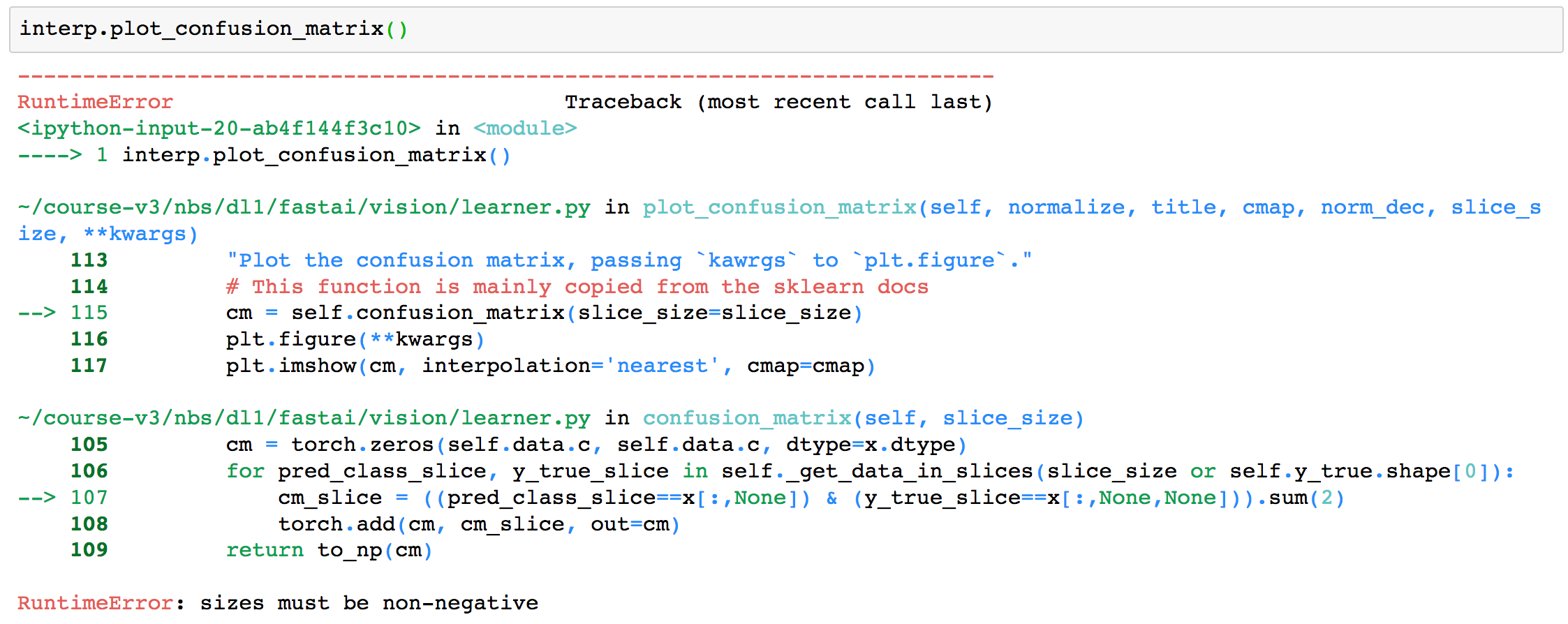
I’ve been having issues with plotting my confusion matrix since I’ve updated fastai. I’ve also updated pytorch and cuda since I’ve had issues previously.
fastai version 1.0.19
torch version 0.4.1
cuda version 10
Of course. I was not talking about this course, and not even about a general computation LA course. I was making reference about the typical 1st year college LA course, which turn out to be the usual background of a data science practitioner.
What, exactly?
It would be my privilege to express myself in a clearer way, if I can.
Mh, I was answering specifically to a person who got a math PhD as his wife. But my point stands for you as well: even the independent, self-taught learner could get better results as he starts to think more abstractly about stuff (again, imho).
Not at all. I’m pleased to learn about other people’s ways of thought.
It is tricky. To those who love and deeply understand math, such discussions are interesting and helpful. I will say: I am not one of those people! Personally, I find it more useful to just think about the lists of numbers and what the computer does to them.
This is not to dismiss those that find a more abstract view of linear algebra helpful. There is no doubt that many feel that way. I have endeavored to study linear algebra in that way, and am slightly less incompetent than I once was, but I didn’t (personally) really find the process that enlightening in ways that helped me with deep learning.
So I’d say: don’t fret if coordinate isomorphisms and vector spaces are not concepts you’re comfortable throwing around. And if you are, and you find them helpful, that’s great too!
Pray your wife misses this thread, otherwise you’ll find your meals way less tasty than usual
Jokes apart, It was the opinion of a person who loves math. It made me a better person, in the broadest sense (yes, previously I was even worse ). But I understand it’s a matter of nature and inclinations.
Sorry if I sounded like grandstanding, but I really didn’t mean that. I struggle every day in the attempt of grasping DL stuff that maybe the more pragmatic finds easy to learn.
Sorry, but I need to give my 2 cents about this since it’s an area I’m very familiar with. There is nothing wrong with using math the way you see fit. A vector is and will always be a list of scalars. For someone else, it’s the rate of change of a magnitude over time. For others it’s the direction of a signal for a certain magnitude. Those who deeply understand math know that math is just a tool used to describe the world around us and not a subject with abstract concepts. What’s interesting about math is the fact that we can create our own or use an existing equation to describe or solve a problem. So I think you shouldn’t count yourself as someone who doesn’t deeply love math since your interpretation of deep learning architecture is easy to understand and works well from a mathematical perspective.
How do I just view the current error rate of my model without having to train it? I would assume that I can access the accuracy or error rate as an attribute of the learner but can’t seem to find anything in the docs. Typing learn. and hitting tab doesn’t give me any attribute or method to view these metrics either.