That should be the ideal goal of a neural network. To act as the most efficient lookup table.
2 Likes
I’m not sure if anyone has encountered this but when I run FileDeleter it disconnects me from my remote server and sort of kills it in a bad way. Only option is to stop instance => re-launch => re-run notebook (and skip FileDeleter).
Tried it on AWS, Colab and GCP. Every time the same result.
Update[11/4/18]: @sgugger bringing this to your attention as I couldn’t find any answer on the forum, still trying to understand the issue better with the code.
Always try using models.$MODEL as your arch, fastai.vision.models has most of it.
I think you can also look at the part where jeremy talks about how models.resnet34 is just a functional way of defining a resnet type arch and not actually using the resnet34 model, for which we use pretrained=True.
Interesting, I too found a similar situation (in fact a little more mind boggling).
My guess for this situation is
- The error_rate is just the miss classification rate and if it stays the same, then for every epoch, your model is miss classifying the same number of images if not the exact same image
- You val_loss bumps up a little as your train_loss goes down, this doesn’t look like a problem since both are in a similar range and the loss_func only helps the model find better weights w.r.t the given data. In every epoch, the loss_func tries the same with minor weight adjustments which fluctuates the avg loss over the epoch BUT the marginal changes doesn’t really affect the FC layers(in this example) eventually leading to same/similar classification tags ( This is to best of my knowledge)
- You many also find situations where the error_rate drops then goes huge then drops a couple of times in ~20 epochs, I found this happening today and still trying to figure out how to improve. But my learning stands
Loss function is helping the model learn, metrics is my specific way of checking how exactly the model learned, these two are related but not coupled
Could you add a snippet showing how will you use models other than resnet (custom models) (that aren’t defined in fastai). As of now it only has support for Resnet, wideresnet and Unet.
1 Like
Hi, I have been trying BooldCell classification and I am having trouble inferring losses of the model prepared.
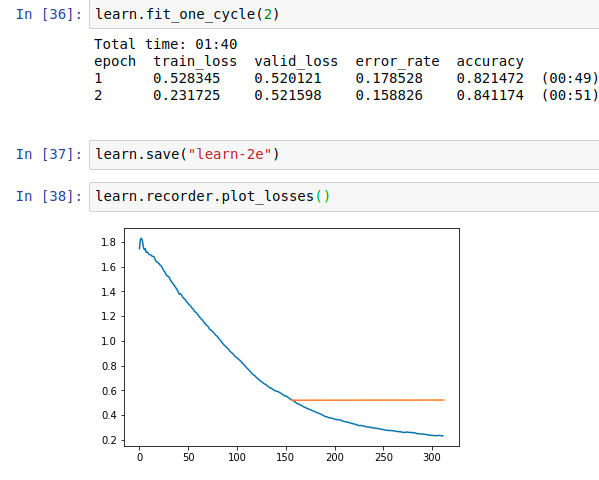
I was wondering should we consider the epoch exactly where the error rate starts getting worse. The lr_find() for resnet34 or resnet50 is also not giving any clear trend in the range of 10e-6 and above.
Resnet34
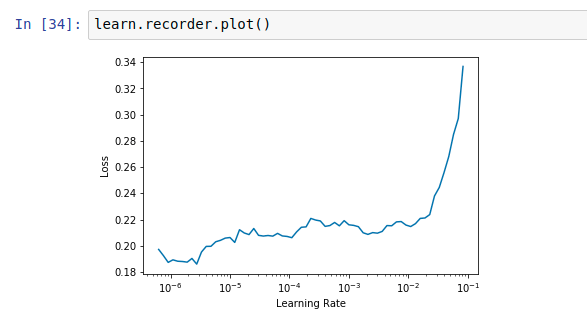
Resnet50
The default value seems to be doing fine for 1-2 epochs. Is there any logic in increasing the LR. If anyone can help me understand how to deal with such a situation please let me know. When I unfreeze and fit with default LR the error drops but it doesn’t improve after 1 epoch.
Also Jeremy mentioned about the error rate might be good indicator of over-fitting but as the error rate improves if the validation loss starts getting worse should we consider it positive or negative effect.
If I am not clear anywhere please let me know.
It looks like you are fitting better to the training data (train loss < valid loss) but your accuracy is still increasing/error rate still is going down, so not a real overfitting.
Based on your lr_find results, try to setup your learning with a max_lr parameter like this:
learn.fit_one_cycle(x, max_lr=1e-6) (x = number of epochs)
When you don’t supply a max_lr parameter it uses 0.003, which is maybe too much in your case and you end up “going down the minima valley jumping around or jumping out of it” (nice animation, see the last two images).
I would be curious about what happens when you train a couple of epochs on top with a max_lr?
2 Likes
Thanks @MicPie… will update with my notebook once I am done with everything. I tried 0.003 after unfreezing and the result became better which implies the learning rate was fine. But anyway I will do further experiments and try what you have pointed out. 

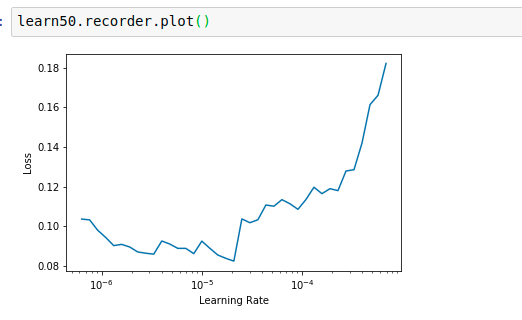
Does anyone know what it means if my learning rate looks like this, @jeremy says to look for the downward slope but I don’t have one. Right?
Thanks,
Christian
3 Likes
Someone know why the number of downloaded images for me is always maximum 100 even when I set it 500 ?
Thank you in advance
You should increasing the skip_end argument when plotting, like learn.recorder.plot(skip_end=10). Once you skip some of the final iterations where the loss is too high, the slop on the left will look much steeper.
4 Likes
Have you checked how many urls do you have in your .txt file? Eventually you may have only 100 urls, and in that case the problem is not the download_image function, but how the file was created. Google Images but default display the first 100 images, then you have to scroll down few times and even click the “show more” button and continue scrolling down until you reach the end of the page. Then finally you run the JS script to get all the urls (700). Jeremy explained it last class, so you can reference there as well.
1 Like
Thanks a lot @joshfp . Yeah it is because of the number of urls in the .txt file .  I don’t remember that Jeremy said to scroll down few times then use the JS script. I will review it again.
I don’t remember that Jeremy said to scroll down few times then use the JS script. I will review it again.
1 Like
hello, How can i train the model with full image size instead of 224? I am trying to train the model on x ray images.
I think you can train on any size (thanks to adaptive pooling), just specify the size argument in the ImageDataBunch. Some factor you should consider:
- All the images must be the same size (in order to fit in the batch).
- Batches will be bigger, so probably you will need to reduce batch size in order to fit in your GPU.
- Very large image may take lot of memory and time (personally I have never tried).
3 Likes
oh… I see… Thanks… I will give it a try
A general question about tenors. Why do we need tenors? Why not just use NumPy arrays for our deep learning calculation?
I head somebody said GPU does not support NumPy arrays. Why?
I believe that according to Jeremys tips you have a slope at 1e-5 to 1e-4. You could try 1e-4 to 1e-3 but I think a smaller learning rate is the way to go.
Tensors, provided by PyTorch, provide two things:
- GPU support: making computation a lot much faster (actually GPUs are one of the reasons of deep learning explosion).
- Auto differentiation: so basically you only take care of defining your neural net, and PyTorch backpropagate (compute the gradients) magically for you.
PyTorch’s tensors and Numpy’s arrays are compatible things and you can convert them back and forward when required.
4 Likes
Thank you. So that means when people invented TensorFlow or Pytorch, they created a new class, called Tensor, which has similar properties as Numpy array, but it also has auto differentiation properties.
I am also always why/how Tensor makes computation much fast in GPU. Why Numpy arrays (or whatever arrays they call) cannot run that faster in GPU?
Thank you again.
1 Like