same here, did you find a way round the 99% issue? It’s stuck there for quite a while.
So to clean the noise in the validation dataset we run
from fastai.widgets import *
losses,idxs = interp.top_losses()
top_loss_paths = data.valid_ds.x[idxs]
and use FileDeleter widget and to clean the noise in the training data we run
from fastai.widgets import *
losses,idxs = interp.top_losses()
top_loss_paths = data.train_ds.x[idxs]
What confuses me is that when we run
losses,idxs = interp.top_losses()
and use the idxs to clean the training data aren’t we using the index of data in validatation with top losses in training data?.. Can anyone help?.
It is better to use “other” image sample as close as possible to what images you would expect in production. If the app is designed to recognized fruit, then it would be best to have images of other fruit as “other” images. Since irrelevant or blank images are not so useful for the algorithm to be able to discriminate apple and orange features.
1 Like
probably you need to drop more?
If i understand your question correctly, you want to learn how to add a custom head to an existing backbone? I can help you with that but I think we will be covering that in the upcoming lectures in more details.
As for the supported archs, if you are trying to use Inception-v3 or similar, I think the library already supports it, if not, you can simply go into developer mode and push code from https://github.com/fastai/fastai/tree/master/old/fastai/models to utilize all the other variants. But, I suggest you proceed with caution as these models are old implementations and might not gel in well the new lib.
That’s weird, I can’t reproduce that bug. Can you share a bit more of your code?
I’ve rerun lesson 1 without any alterations to the code and seem to have had the same issue. I’ve pulled the last version of fastai just before doing this as well so I’m unsure why I’m having his issue.
Update: I suppose I should have been pip installing fastai this whole time. Oops.
I am having a problem, Colab is dying often(after 4 hours once, and after 6 hours of train another time yielded no result), and is slow(taking about 1sec for a batch, and I have a huge dataset); so after training of say 6 epochs (almost 3.5 hours) if I find a few more epochs would have made it. But to add two epochs will add a 5 hour penalty, since I have to run learn.fit_one_cycle(8) instead of learn.fit_one_cycle(2) which will take 1 hr more. I can’t use learn.fit_one_cycle(2) because as you can see from the screenshots the loss is increasing (and it should because the learning rate should’ve decreased I guess, instead it is increasing). It will be very helpful if someone can say how to bypass this problem.
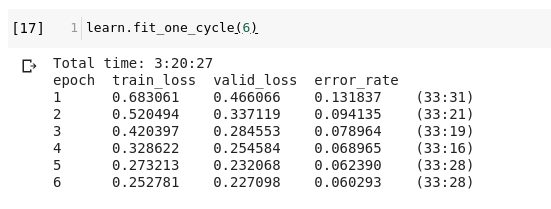
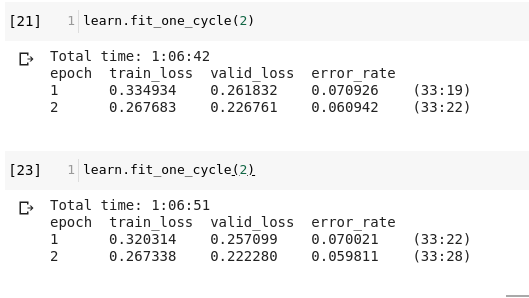
Please refer to this:
1 Like
I don’t know what happened, but the moment I lowered the max_lr by factor of 10, ie. 0.003 to 0.0003, the train_loss went down more than val_loss for the first time.
Is this what happened ---- 1cycle scheduler must have a small linear cooldown at the end, that is the learning rate must go down. But the moment I write learn.fit_one_cycle(2) the learning rate increases to 0.003, however it should have never gone to 0.003 if I ran the previous learn.fit_one_cycle(6) as learn.fit_one_cycle(8). It should have went down. So learn.fit_one_cycle(2,max_lr=slice(None,0.0003)) does the trick by decaying the magnitude. I still don’t know though whether this trick is reproducible and scientific; and not an alchemic hack.
It would be great if someone can disprove me, or tell me a way to design an experiment to test my theory
lesson 2 download, I am confused how do this on google colab.
So I have downloaded 3 files: teddies.txt, blackbear.txt and brownbear.txt on my laptop
Then I enter the next command:
folder = ‘black’
file = ‘urls_black.txt’
Then:
path = Path(‘data/bears’)
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
this is where I got confused:
download_images(file/path, dest, max_pics=200)
what should i put on the file/path?
something like this: ‘c:/Downloads/blackbear.txt’
it does not work?
something that i miss?
Thank you
1 Like
No i wasn’t talking about adding custom head, i wanted to use custom model which you can use with Learner.
# Load the Drive helper and mount
from google.colab import drive
# This will prompt for authorization.
drive.mount('/content/drive')
folder = 'black'
file = 'urls_black.txt'
path = Path('/content/drive/My Drive/FastaiData/Lesson-2/data/bears')
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
classes = ['teddys','grizzly','black']
download_images(path/file, dest, max_pics=200)
1 Like
@sgugger how to add test_data using data_block API ?
1 Like
I have trained resnet34 model on a certain dataset. I would like to use those weights in different application. How should I do it? One way of it was using load() using create_cnn() object but for this it requires initialisation of learner object which again requires use of loading ImageDataBunch(). Is there any work around for this?
I wanted to increase the number of cat breeds in the pet dataset - I have downloaded this from google images. Is there a way to combine the data that I downloaded for the specific cat breed to the ImageDataBunch we get from the pets dataset? Or would I have to manually adjust the files?
would that work? https://docs.fast.ai/data_block.html#SplitData.add_test
2 Likes
thank you …i managed to do it via the google colab upload features … I might want to post a short tutorial do do this 
lesson 2 download cleaning up error.
so seems to work until when i run this code (under cleaning up: lesson 2 download):
from fastai.widgets import *
losses,idxs = interp.top_losses()
top_loss_paths = data.valid_ds.x[idxs]
and this is what i get:
ModuleNotFoundError Traceback (most recent call last)
in ()
----> 1 from fastai.widgets import *
2
3 losses,idxs = interp.top_losses()
4 top_loss_paths = data.valid_ds.x[idxs]
/usr/local/lib/python3.6/dist-packages/fastai/widgets/init.py in ()
----> 1 from .file_picker import *
/usr/local/lib/python3.6/dist-packages/fastai/widgets/file_picker.py in ()
2 from …core import *
3 from pathlib import Path
----> 4 from ipywidgets import widgets, Layout
5 from IPython.display import clear_output, HTML
6
ModuleNotFoundError: No module named ‘ipywidgets’
anybody? Thanks
1 Like
What I’ve been doing is replacing valid_ds with train_ds and using my own defined range of indices to clean up the data.