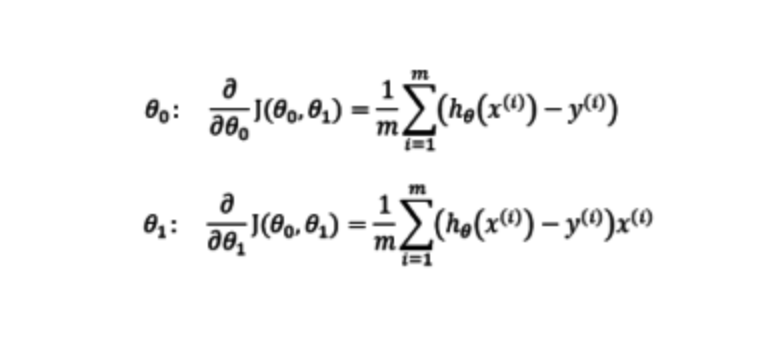I have a question regarding the update() function defined in lesson 2:
def update():
y_hat = x@a
loss = mse(y, y_hat)
if t % 10 == 0: print(loss)
loss.backward()
with torch.no_grad():
a.sub_(lr * a.grad)
a.grad.zero_()
Having seen the update rule for linear regression couple of times from a mathematical perspective, I am a little surprised by how this works. Especially the loss.backward() call. This looks something like this:
(theta are the params, J is the loss function and h_theta(x) is the y_hat)
If you would do this mathematically, you would generally first compute the gradient (derivatives) of the loss function with respect to the parameters. And once you have their functional form you can plug in your y (labels), a (parameter estimates) and x (feature) values.
If I am reading this, then I’m seeing that they first compute the loss, which is mathematically just a scalar, and from that scalar they are still able to compute the gradient…
I guess it has something to do with the fact that what is returned from mse() is actually not a scalar but a rank 1 tensor which apparently seems to store all the stuff that actually went into it (e.g. y, a and x) and is somehow still able to compute the derivatives with respect to a correctly.
Nonetheless this seems quite “magical”, would be really grateful if somebody could shed some light on this! Would be also great to understand a little better how PyTorch is computing gradients. Is it doing that analytically?
So for each label (multi-label) you have 4 images right? How about training 4 separate models and combine the results. E.g. combine the predictions of the four models into a single (final) prediction (perhaps by majority voting) ?
Would also be interesting to check whether a certain channel is better at predicting certain labels then others.
At each update, the derivative is computed at one point: the current value of the parameters. The technique used by pytorch or other DL frameworks is called Automatic Differentiation. Basically, the gradient is automatically computed step by step using the chain rule. So it is fast and accurate like you had an analytical expression.
If you want to understand more what is going on under the hood you can read
the first 3 section of this pytorch tutorial.
Thanks! It seems the magic that I am referring to is basically accomplished by the computational graph that is defined during the forward pass. Super interesting to see how this works and how one can implement new operators to work within this paradigm!
Hey…i got an issue…The javascript code that will extract image link from google images is not working or rather the option to save the .txt file is just not appearing …any suggestion??
Pls someone help…i just downloaded images for 5 categories from google images and then when i tried to run the verify function its just not verifying all categories
Not exactly right. This is true only if you are talking about a binary classification where you have 50% to get the right result with random choice. For a 10-class classification the probability to get the right class at random is 10% and so 59% would be a significant improvement.
Hi there! DL beginner and non-computer scientist here so forgive my ignorance. I had the same question as lucasvw, but I had a hard time following the PyTorch examples you linked. If possible, could you clarify your statement regarding computing the derivative for the current value of parameters within the context of the SGD example of lesson 2?
In other words, for a given update t, our line is defined by:
y(x_1,x_2) = a_1 x_1 + a_2 x_2
where x_2 is 1 but that doesn’t really matter.
If we define the loss function J as MSE for a total of n points:
Q: I have no idea how to use a Nvidia GPU to accelerate my training. I can access my graphic card by using
**" torch.cuda.current_device()"**and “torch.cuda.set_device(0)”,
I’ve also tried “defaults.device = torch.device(‘cuda’)”, but it’s still slow when I run “learn.fit_one_cycle(4)” to train my dataset. Can any one tell me does fastai detect and use GPU automaticly or not; if not, what extra code do I need to use my GPU , thanks alot
Hello guys! I was just curious if widgets even work on Google colab or not?
I am running the code but it is always getting stuck at this point, the previous statement is running but whenever it is reaching ImageCleaner it is getting stuck
I think i found the issue… the definition of ImageCleaner have changed. If you look at the API
ImageCleaner(dataset, fns_idxs, batch_size: int = 5, duplicates=False, start=0, end=40)
the third argument is… batch_size, instead of path-- so in your use case… just change the call to ImageCleaner as below
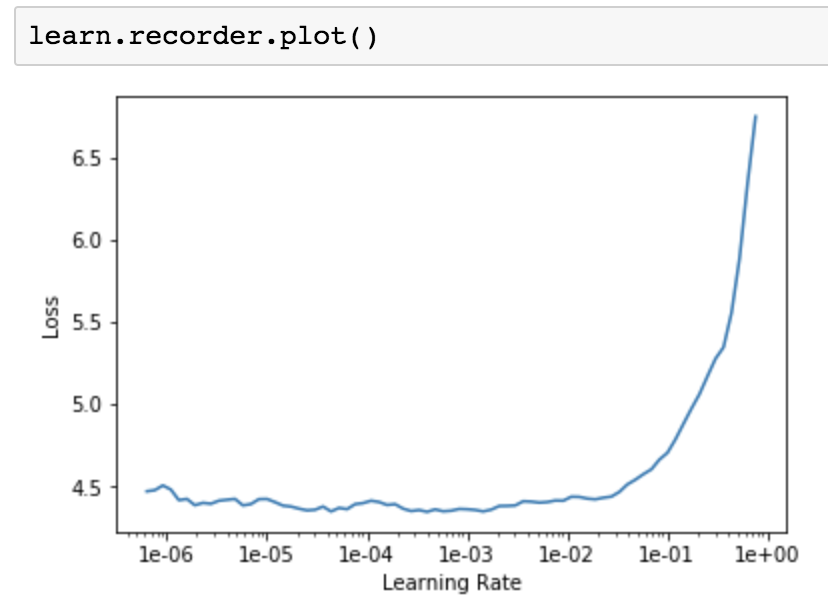
The loss increases …in future lessons jeremy taught it…simply because …with higher learning rate weights are updated with larger value so they have less tendency to approach to minimum value as they keep oscillating but if you have lower learning rate the weigth which would get updated in backpropagation would generally tend to lower to minimum value