Hello @zachcaceres. Any plan to adapt ImageCleaner() to all ImageBunch methods and not only from_folder() ?
I’m using the from_name_re() method and the following code gives back the training images, not the validation ones (even with ds_type=DatasetType.Valid):
it’s unlikely that I would do adaptation of the widget for at least a month. Apologies, my plate is just too full until then.
I’m sure that Jeremy and Sylvain would welcome PRs that extend the widget and I also know that @lesscomfortable is familiar with the inner-workings and might be able to help.
tanismar [2:59 PM]
Hi there! This should be super-simple, but I can’t seem to find a way to do it. I want to implement a single image classifier (based on https://github.com/fastai/fastai_docs/blob/master/dev_nb/104c_single_image_pred.ipynb) to discriminate among the ImageNet classes. Ideally, I would just have to load the trained model (say, ResNet34), no transfer learning, no fine-tuning. However, ImageNet is not itself provided as a fast.ai Dataset (https://course.fast.ai/datasets), so I can’t figure out how to set my ‘data’ argument to pass to create_cnn() so that it keeps all the original classes. Has anyone tried this, or has some idea how to do it? Thanks in advance!
On the Resnet34 question (1:12 - https://youtu.be/ccMHJeQU4Qw?t=4332), @jeremy said you can set pretrained=False in the learner definition. Is this really true? I thoughts the model.resnet34 has weights to start from. I actually set the flag to false and got high error rate (20% vs 3%). Any update on this?
In Pytorch, Would a loss function like below work: ?
def my_loss_func(y_hat, y):
cnt = 0
for idx, val in enumerate(y) :
if val != -1 :
s = s + val - y_hat[idx]
cnt = cnt + 1
return s/cnt
Basically I want to take into account losses for only those values where the real answer is not equal to -1 (a value I fill the missing values with).
If not, any ideas on the correct way to approach this?
The only error in your code is you need to initialize s = 0 as the first line in your function.
But I’d be wary of taking the sum of differences as the loss function, because positive and negative differences tend to cancel each other, and could give you a low value of the loss function even when the predictions don’t actually agree with the data.
For this reason, I would use the rms (root mean squared) error (or mean absolute error) instead. I’ve implemented rms error below:
# compute the rms error of the model for the selected targets
def my_loss_func(y_hat, y):
# boolean indicator selects values for which target is not equal to -1
idx = val != -1
# compute and return the rms error between target and predicted target, for the selected values:
error = y[idx] - y_hat[idx] # error
s = np.sqrt( np.mean( np.dot(error, error) ) ) # rms error
return s
Hey! I’m working on the lesson2-download notebook and, when running ImageCleaner(ds, idxs, path) I get an error message that says “Runtime disconnected” and my notebook freezes. Do you have any idea of what might be going on?
I’m running it on Colab. Could it be that it’s running out of memory or something like that?
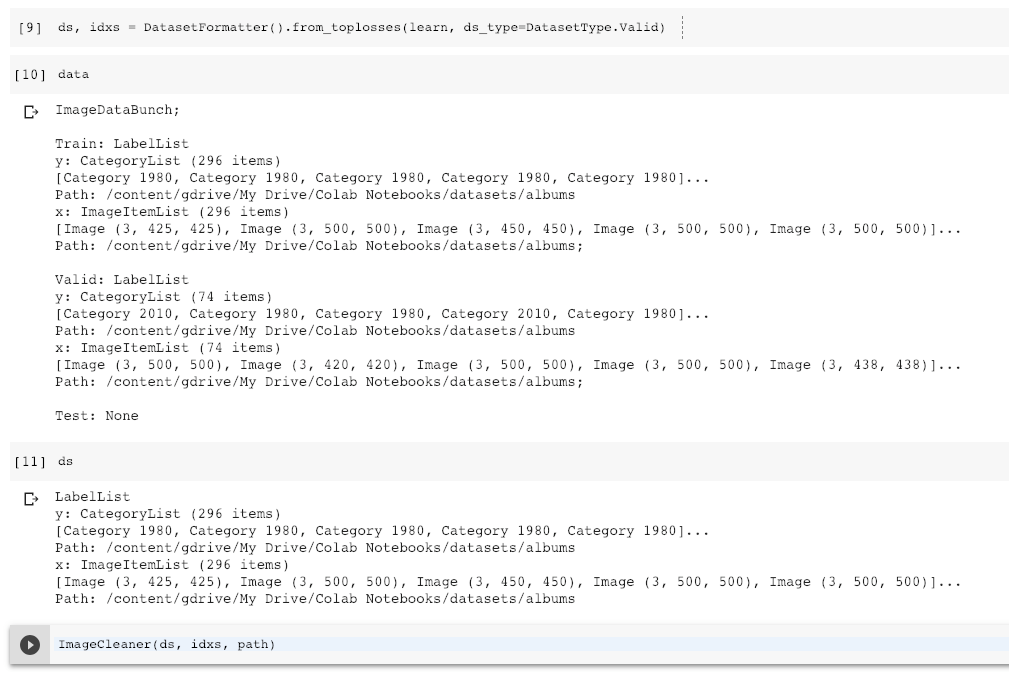
Here you can see some info on my original dataset and the one that DatasetFormatter.from_toplosses() generates:
At around 49:00 in the Lesson 2 video, @jeremy says that training loss being higher than validation loss means that you’re either training too slowly, or haven’t trained for enough epochs. However, directly above this in the notebook, looking at the output from the default learning rate setting (which I presume was pretty good, given the low error?), the training loss is indeed about 6x the validation loss.
So – this makes me wonder: Was the learning rate in the model output copied and pasted above too low? Or is there some train/validation loss ratio threshold that should alert us to a low learning rate?
Also relevant to the question raised by @atlascivan a few months ago in this thread – I had always understood that training loss should pretty much always be lower than validation loss, precisely because the training data are what are used to build the model, so the model should pretty much always do better on those than novel data. I’m not thinking about deep learning specifically, but ML in general.
I think what Jeremy meant (please try not to @ him or Rachel unless absolutely necessary) was that at the end of your training the training loss should be lower than the validation loss. With various regularisation techniques we are purposely making the training classification harder, so that the model generalises better. This explains why you are seeing higher training losses than validation ones (at least at the beginning).
In my (admittedly limited) experience I am happy when the training loss becomes less than the validation one only a few epochs before the networks starts overfitting (that is, the validation loss start increasing).
Hey, guys. In Lesson 2 (41:00) Jeremy shows how model can predict and uses a picture of a Black Bear from the dataset. I have some questions if you don’t mind:
If that was a picture from the dataset, there’s an 80% chance it was in a training part of the dataset, so the model might have seen it already and just remembers it’s a Black Bear (overfit?). Is it important to make sure the model didn’t see a picture we’re trying to predict in order to check if can predict properly?
If it’s important, how do I make sure the model didn’t see this picture? How can I see if the picture is in a training set or in a validation set?
(Not related)How can I know the confidence score when predicting a class?
Validation set (even if extracted from the existing set) is not included in training. It is checked as if it were a test set. If I recall, an image was picked just to show how prediction works - this image could be something you upload but was picked from existing folder for convenience. There is one possibility in datasets created this way (download images from Google) of duplicates, so need to check for that.
You can see what goes into train, valid and test sets using data.train_ds … etc.
and when you call predict, you get a tensor of probabilities for each class.
After looking around a bit, I found a solution: just make sure you are working the latest version of fastai. This is what you have to do:
Open the terminal and check what is your version of fastai: pip show fastai
Should be version 10.4.2, if you have an earlier one, type: pip install fastai --upgrade
You have to restart the kernel and re-run the whole thing for the changes to have effect.
I had the same problem reoccur in a notebook I trusted. Once you run the widget once and get the error message, if you refresh the notebook (just refresh the browser) it may work after that.