I was having similar problem, I belive your training set have some strange images, after cleaning up it should be fine.
1 Like
I have asked the same question in this thread, see above. Still would like to have more insight into this and the intuition behind using an “extra” class or not:
3 Likes
Input images that do not belong to one of the trained classes is a problem for me, too.
Does anyone have a suggestion what to do in this case? Using vanilla Resnet will result in the network trying anything to output one of the trained classes. In most real world scenarios, there is no way to make sure that the network always gets fed using images containing one of the classes.
Using a “not_a_class” class would not allow to input a lot of negative examples, since at one point it will result in inbalanced classes.
Any suggestions? I did not find good information on this using google.
Best regards
Carsten
1 Like
I would like to create mobile app that would classify house plants and tell me if the plant is poisonous to dogs/cats (I have both at home, so). Would it be better to classify species of plant and then compare with list of poisonous plant or to train the model on which plants are poisonous for plants and which for dogs?
Does anyone know cheap/free hosting that would be nice for REST api for this kind of app? I would like to finally make a mobile app which would talk to the api.
1 Like
This may help.
1 Like
I seem to be having a problem with the lr_find() function. Instead of shooting up at some point as shown in the class videos and notebooks, my lr_find() plot always shows loss decreasing as the learning rate increases (up until about 1e-02, though that changes with each run of lr_find(). I’ve tried using the default parameters and also tried using a few different custom parameters.
Here’s my learning rate plot with the default parameters:
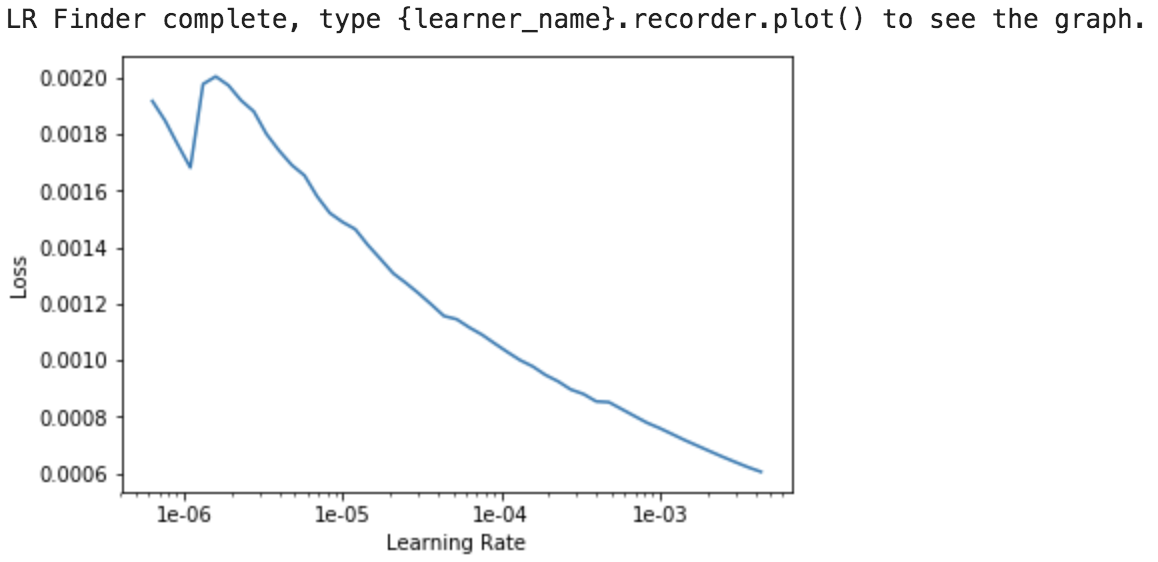
And here’s my learning rate plot with a smaller start_lr and larger end_lr parameters learn.lr_find(start_lr=1e-10,end_lr=100,num_it=200)
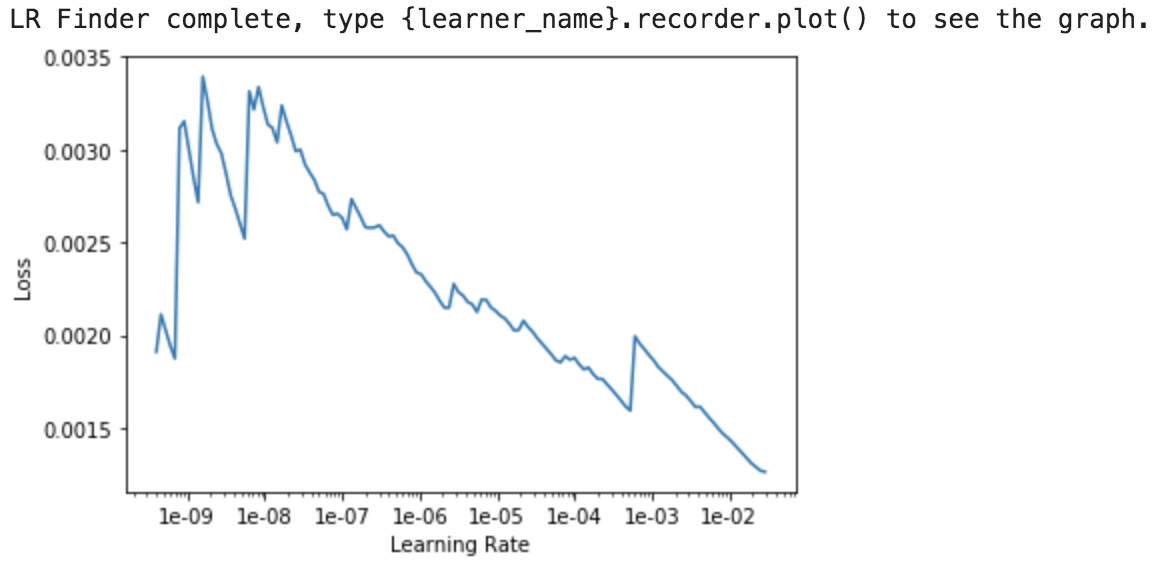
What does this mean?
1 Like
Practical question
How long should we train a model for in stage 1? Until convergence?
I’ve tried to answer this question myself, but did’t get any clear answer. Jeremy mentions in lesson 2 ‘make some progress’.
Let’s say a model is fully trained (reaches convergence) in stage 1 after 20 epochs. In order to achieve the best possible result, should we:
- Fully train it for 20 epochs, and then try to fine tune? Or
- Just partially train for 5-10 epochs and the fine tune it until convergence?
In my experience I have not seen a major difference. What I’ve seen though is that when a model is fully trained in stage 1, there’s almost no option to improve it in stage 2 (fine tune).
Does anybody have any experience/ general guideline as to how to answer this question?
If your dataset is quite different to imagenet, you’ll most likely need to unfreeze and fine-tune.
1 Like
Thanks for the quick reply!
However I think my question was not clear enough.
Assuming I have a dataset quite different from imagenet, which is the preferred option in order to get best results:
- Fully training the model in stage 1 (let’s say for 20 epochs, until convergence), and then unfreeze and fine-tune, or
- Partially train the model in stage 1 (5-10 epochs), and then unfreeze and fine-tune
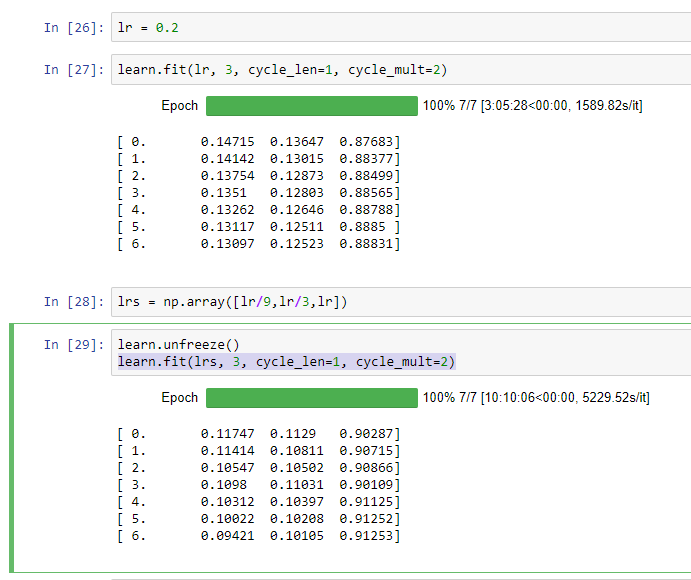
I ran through the Lesson 2 Notebook this week, and found that it took over 10 hours to run just one step (The 2nd learn.fit after first setting learning rate step as
lrs = np.array([lr/9,lr/3,lr])
Should I expect the DL process to always take so long? If it takes 15+ hours just to complete the second assignment, does that mean we are expected to spend 30+ hours to complete both the sample run-though and one experiment on our own? Or should the homework not take that long? Should we expect the runtime to continue to increase or is this an anomaly related to this example? Or am I doing it wrong?
Screenshot of my runtime for the step indicated is attached.
It is not possible to give a recipe. Train until it starts to overfit. If you are not satisfied with your results, tune up you HPs (dropout, weight decay, diverse LRs, etc…) and start again.
1 Like
I think you are using the cpu. Run a cell with torch.cuda.is_available(). If it answers True, run torch.cuda.set_device(0). Rerun your training and and report back.
1 Like
this needs to be updated in lesson2-download notebook
can i create a PR?
1 Like
I experimented with a binomial classification with a dataset that used say 36 images for training and 16 images for validation. The validation images contained 1 image that clearly did not belong to the either class. My resulting accuracy after stage 1 was close to 0.93. When I looked at interp.plot_top_losses plot, the bad image appeared every time. I did not pay attention to this fact and ran stage 2 with bigger image size. The accuracy did not get any better. So I started looking at my data again. I replaced the bad image(which was staring at me all the time) with another image I downloaded from images.google.com and guess what my accuracy improved to 100%
Lesson learned ----
-
model accuracy is reflection of the validation data. (I could not have got 15/16=0.9375 accuracy given 1 out of my 16 images was terribly bad).
-
validation data should be a reasonable representation of training data (good data and proportionate distribution across classes).
-
and what Rachel said here
1 Like
yeah! thanks for helping out.
I created it here. https://github.com/fastai/course-v3/pull/87
It seems to break the build though?
1 Like
I think Jeremy covered this in lesson 3. So, his idea was lr to be a little less than 1e-4 in this case. I would say [5e-6 5e-5] should be good
I am not sure it would be ‘definitely’. What if you got somehow a ‘bad’ dataset that it is just so happen the validation set is not diverse in otherwords ‘biased’. Although this is unlikely to happen especially if you curated the dataset very well and the algorithm to pick validation set is ‘foolproof’ , otherwise anything is still possible.
but yes, you are right in that scenario it would likely to overfit given the proof, but I would not call it ‘definitely’.
1 Like
I got a runtime error trying to run this on google colab, sorry should i post this under google colab? my apology
depends on the error, could you share more perhaps in the appropriate topic? My impression is that since this widget was changed so quickly after last lesson that a lot of issues are due to confusion about how to use it (totally understandable)