Right now I moved on to image segmentation but I will put an issue into the GitHub if I find an example. And thanks for building this! 
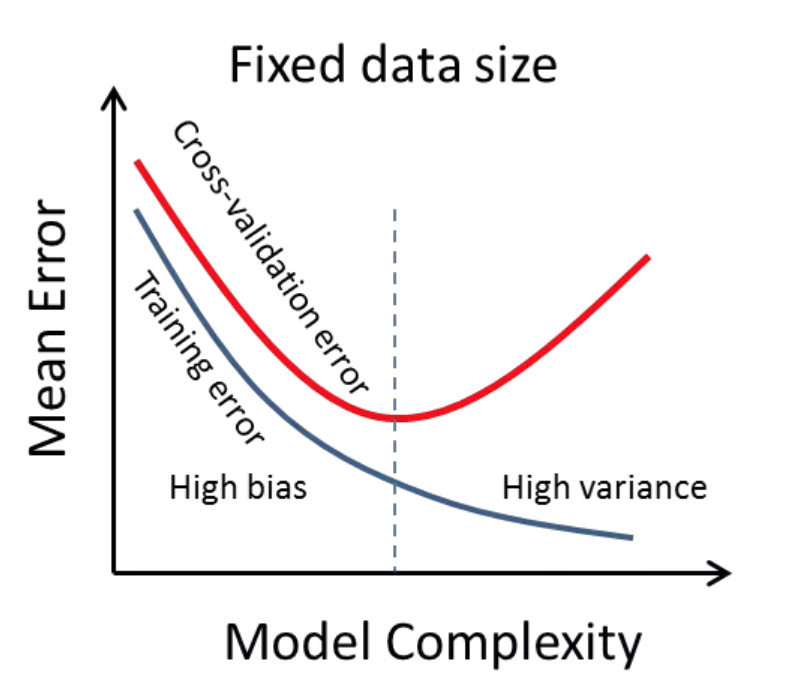
On some paper (update: https://arxiv.org/pdf/1803.09820 ) I saw a picture that explained it very well. I’ll paste some here that provide the same message.
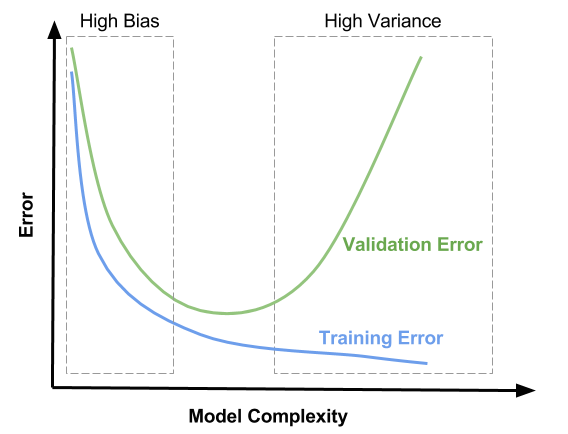
https://zahidhasan.github.io/img/bias_variance6.png
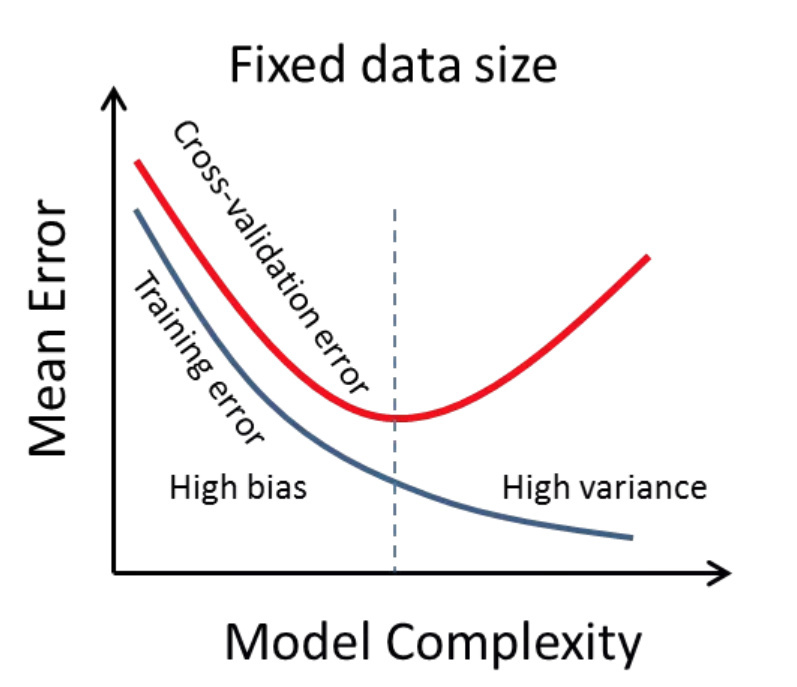
https://forums.fast.ai/uploads/default/original/2X/5/57b24adcaf41ec93767e692094f00369a4f2e6fb.jpg
Too little training: underfitting
Too much training: overfitting
But that is the case if the network is “deep” enough to learn from the data. With “deep” I mean of a suitable architecture to be able to perform well.
If the network is too small, it won’t be able to predict accurately.
If the network is too big, you will need to apply regularization as it will be very capable of just “memorizing” the training set.
(Just my view)
lr_find
It spits out the validation error (prediction error against the validation set).
If there is no validation set, then there is no error to calculate.
Most probably you loaded the images without specifying a % to be used for validation. We do that (0% validation) on the stage when we want to ‘clean’ the dataset, so we work with all the images, not just training.
How many images are needed to train a robust cnn?
Jeremy mentions “less than you would think” in the video lecture. The snippet of js code that scrapes google images gives me 80 photos. Even with the most careful tagging using -keywords tags in my search, anywhere between 25 and 50 percent of my returned results are ‘noise’ that I have to manually prune out.
My dataset per classification ends up being 30-80 pictures per class, after manual cleaning. Is that good enough?
I’ve read elsewhere on the web that you need at least 1000 images per classification. That’s a lot.
And a second question:
What is the reason for running the cleaning process AFTER training the model instead of before?
Wouldn’t it be a better trained model if we started with good data?
In lesson 2, we set learner.precompute to false only for the last layers.
Instead will it always be best to first unfreeze and then precompute all weights with augmentation for better results?
As Jeremy always says, Try it and see…
I have had good results with 100 images per category.
One reason is so that we can use the trained model to help in the cleanup process.
e.g. Show me all the Cat1 images
Then it’s easier to identify images which are not in Cat1
Is an ImageDataBunch a DataLoaders object?
Trying to sort the difference between a DataBunch, DataBlock, and DataLoader. Thanks.
Also, what should I do if I see that my training and validation loss are decreasing very nicely, but error rate is staying the same?
i’m trying to clean the image dataset i created. I’m working with google colab so when i arrive this part:
# Don't run this in google colab or any other instances running jupyter lab. # If you do run this on Jupyter Lab, you need to restart your runtime and # runtime state including all local variables will be lost. ImageCleaner(ds, idxs, path)
It clearly says “don’t run this in colab”
Then how im i suposed to clean my dataset if i can’t remove the images?
Thank you!
When try to predict class using loaded learner(classifier for black/grizzly/teddy bear, I can’t seem to get the prediction showing me the actual class, instead I’m getting this:
.
{kind=link}
{kind=link}
{kind=link}
I’ve tried both on gradient & colab, can’t figure out why.
If you haven’t already done so, you will need to learn ‘exception handling’.
i have a problem with the javascript console approach on mobile devices.
basically i’m stuck abroad for the next 2 months and i’m working from an android tablet with a bluetooth keyboard which is fine except the mobile browsers (at least chrome and firefox) don’t have js consoles as they only understand remote debugging.
does anyone know of a work-around to this which doesn’t involve me going to find access to a pc?
Have you tried something like https://jsfiddle.net/ ?
that looks like a useful toy but it’s not going to help me with this particular problem since i can’t get at the html on mobile either. i’m just knocking up a quick scraper notebook instead for now. thanks anyway!
Hello, I have the same problems , someone here in another discussion wrotte this code with work with me in safari , chrome and firefox, and solve the problem of not date. I hope it works wih you too ,
var urls=Array.from(document.querySelectorAll(’.rg_i’)).map(el=> el.hasAttribute(‘data-src’)?el.getAttribute(‘data-src’):el.getAttribute(‘data-iurl’));
var hiddenElement = document.createElement(‘a’);
hiddenElement.href = ‘data:text/csv;charset=utf-8,’ + encodeURI(urls.join(’\n’));
hiddenElement.target = ‘_blank’;
hiddenElement.download = ‘myFile.txt’;
hiddenElement.click();
Hello,
I am quite confused as to where should I put an error which I am getting while running the first code.
from fastai.vision.all import *
path = untar_data(URLs.PETS)/‘images’
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
error is in learn.fine_tune(1) and the error is : anaconda3\lib\site-packages\torch\utils\data\dataloader.py in _try_get_data(self, timeout)
can you please guide me where do I post this error