hi @Prowton
Yeah it works good, Thank you.
Another thing is sometimes while verifying the datasets, I’m getting “your generator is empty” error.
I reset all runtime and executed from first and it worked good.
why is that?
hi @Prowton
Yeah it works good, Thank you.
Another thing is sometimes while verifying the datasets, I’m getting “your generator is empty” error.
I reset all runtime and executed from first and it worked good.
why is that?
Hi @tedmasterweb, You have all the information you need. You convert them by simple turning the first block of code into a comment( saving the code for the future) then use the second block of code. Or delete the first block of code and then use the second. .from_csv().
Hello, please I am new to deep learning and coding in general. Anytime I run this command ImageCleaner(ds, idxs, path) on google colab to clean my dataset, it stopped and restart the runtime and all progres is have made before is gone. Does the widget app not work on colab?
Any help would be appreciated please.
Had similar issue on colab. Widgets don’t work on colab yet I guess.
Had to switch to jupyter notebook for this
Hello, I just started this course and in this lesson something is unclear to me. What does Jeremy exactly mean when he says the the architecture we’re using(resnet34) for that particular learner is just a function and has no actual data ? Doesn’t it mean that it is a pretrained model that has all the weights(filters) already fixed for feature finding ? Then why does he say that we can fill in pretrained=False? Can anyone explain this to me, please?
Thank you very much. I thought I broke something in the code. I’ll try jupyter notebook.
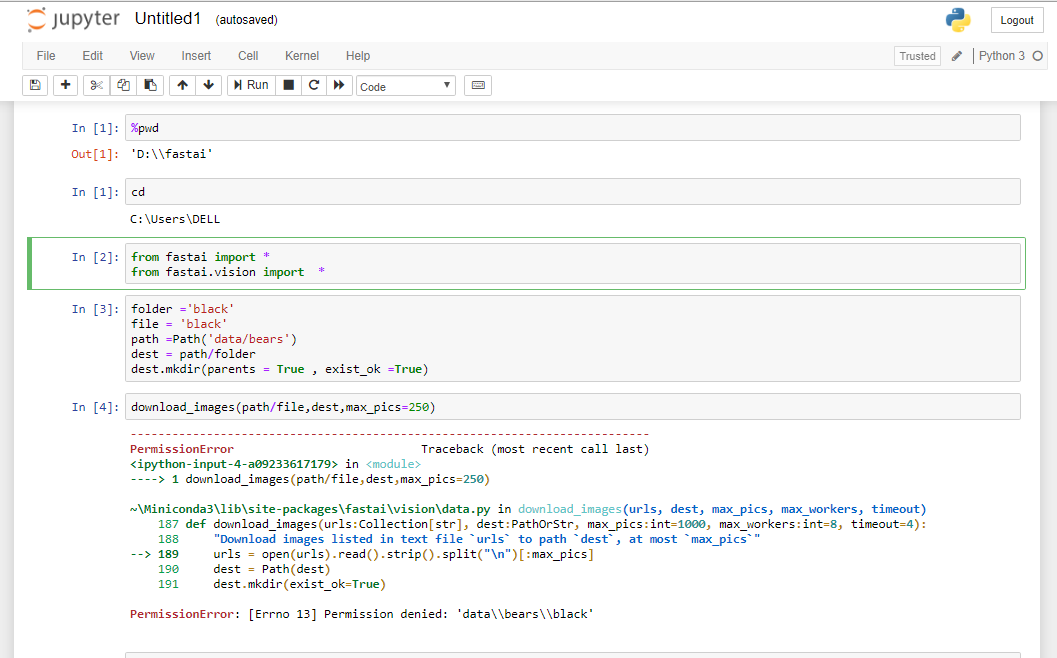
Hi i am getting the same error as shown in screenshot , how did it work for you ??
Same problem, did you find a solution?
Hello, has anyone gotten an error saying: /usr/local/lib/python3.6/dist-packages/fastprogress/fastprogress.py:105: UserWarning: Your generator is empty.
warn(“Your generator is empty.”)
This error appears after I type in:
for c in classes:
print©
verify_images(path/c, delete=True, max_size=500)
I’ve ran the notebooks many different ways but I keep on getting this same error.
I’m very new to deep learning, so getting the setup right has been a struggle. I haven’t been able to even start training a model because I keep running into problems. I’m using google colab by the way. Someone please help.
I am getting a error
PermissionError: [Errno 13] Permission denied: 'data\bears\black’
I am running the anaconda prompt as administrator …
Hey, your Kaggle really helped me. Thank you so much!!!
Suppose one used ImageCleaner once to remove top losses and created a new data bunch using the cleaned.csv. Then one wants to use the ImageCleaner again to remove duplicates. The question I have is: will the new cleaned.csv reflect the only images that survive both top loss and duplicates?
Thanks!
Tim
Allowing me to answer my own question: the new cleaned.csv contains only the images that survive successive rounds of ImageCleaner.

I created an image dataset of three kinds of metalworking machinery. Lathes, surface-grinders and milling-machines. After stage 2 there was a 21% error rate - which seemed pretty miserable. When I went through the ‘delete irrelevant images’ section of the notebook, there were surprisingly very few errors. Amazing really. The confidence levels seem pessimistic.
When reached the step where we are remove duplicate images. There was some sort of combinatorial explosion where every surface-grinder seemed to be flagged as a duplicate of every other surface-grinder. Interestingly none of the flagged duplicates was in fact a duplicate. I could tell the difference pretty trivially. They certainly were similar, but obviously, trivially different - at least to bipedal monkeys.
Can anyone explain to me what is going on?
Cheers…
Hi banksiaboy Hope all is well!
Do you have any image examples of the classes that you describe in your post.
How images do you have in each class?
Do you have a copy of the confusion matrix?
Cheers mrfabulous1 
Hi @mrfabulous1, Thanks for showing an interest - much appreciated…
Sample of the unfiltered downloaded pictures:
Counts of subdirectories of ./data/ showing number of image files in each class
$ find . -type f | cut -d/ -f2 | sort | uniq -c
1 cleaned.csv
1 export.pkl
160 grinders
160 lathes
160 mills
3 models
1 urls-metal-lathes.txt
1 urls-milling-machines.txt
1 urls-surface-grinders.txt
Confusion matrix:
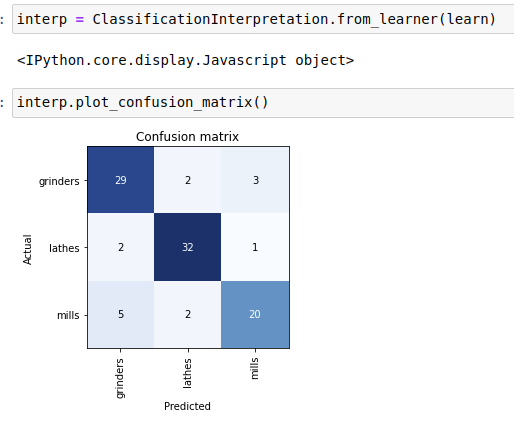
I must say I’m still uncertain interpreting the output of the learning executions…
Cheers…
21% is not miserable when you train a model, as data can be far worse than that, in some algorithms the dataset is such the the algorithm may never converge to produce a result that is usable.
I showed your images to 3 random people and none of them could identify any of them, with any confidence. You are undoubtedly a domain expert unlike us bipedal monkeys.
Your model is exhibiting the behavior I see many models make, when the images look very similar across classes.
Although I used these machines at school and college
I can see no discerning differences between the three classes.
e.g. when you look at a cat or a dog, there is something catish about a cat and doggish about a dog. Which everyone can see even if they cannot articulate it.
Your images nearly all contain handles a bed for the material a control box etc.
I had the same problems when building classifiers for certain data-sets e.g when building a wristwatch classifer the error rate was approx 6% percent for two classes unusable with 60 classes.
I think this is the point where in kaggle competitions, people start using different models, tweeking the code and doing feature engineering to tune the model some more.
I have been wondering myself when I have this problem do I need more data eg. would 1600 or 16000 images a class help?
Hope this helps
Cheers mrfabulous1 ![]()
![]()
Hi, Thanks for the wonderful course. I am new to machine learning / deep learning.
Whey trying to download images using javascript code, I am only getting the google link like the one below for all images.
Is there a way to resolve this, please.
Hi there,
I’m dabbling with a classifier for airliners. I downloaded ~400 images of 13 aircraft types and used a pretrained resnet50 as classifier. I’m currently reaching 75.9% accuracy.
I’m wondering about two things. First, when I look at the confusion matrix, I see that the errors are not evenly distributed:
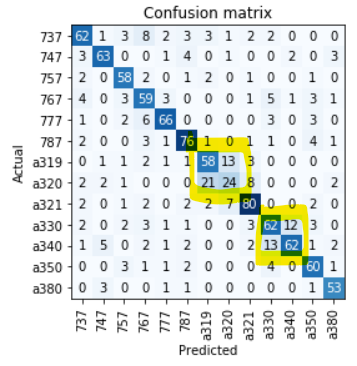
For Airbus A319/A320 that totally makes sense, these aircraft look extremely similar and are hard to discern even for me in many pictures.
For Airbus A330/A340 however, although they share a lot of features, it should be nearly impossible to confuse them, as one has two engines, the other four.
What could I do to fix this? Just throw more data/images at it? @mrfabulous1, you mentioned feature engineering, is that a viable approach for such a problem, and how would it work?
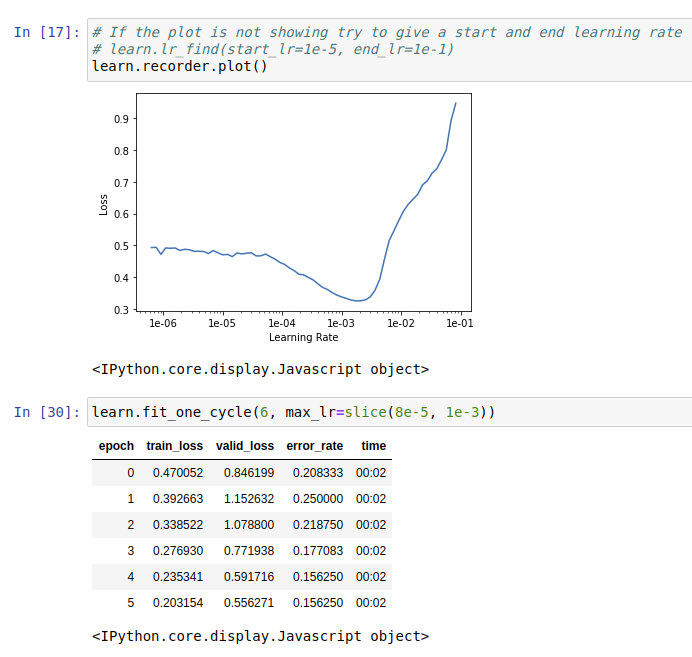
My second thought: when I plot the top losses, I get this result:
Thank you so much,
Johannes
Hi @aditya_new,
I believe Google changed their search results page a while ago, which makes it a little harder to scrape the images. I don’t know how to fix this directly, but I can recommend a nice tool for scraping Google/Baidu/Bing/Flickr. It’s called fastclass.
This runs on your local machine, however, so you will have to zip the images and upload them to your fastai environment (if you’re running it on a cloud provider).
Have fun!
Johannes