This question is a rewrite of a question posted yesterday. It is rewritten in hope that someone can help, so that I move on to the next lesson.
I try to run the Creating your own dataset from Google Images notebook, but I keep getting errors.
It is no problem getting the images and creating the folders for each bear.
When I run path.ls() I get the following output:
[PosixPath(‘data/bears/teddys’),
PosixPath(‘data/bears/black’),
PosixPath(‘data/bears/grizzly’)]
I am supposed to run:
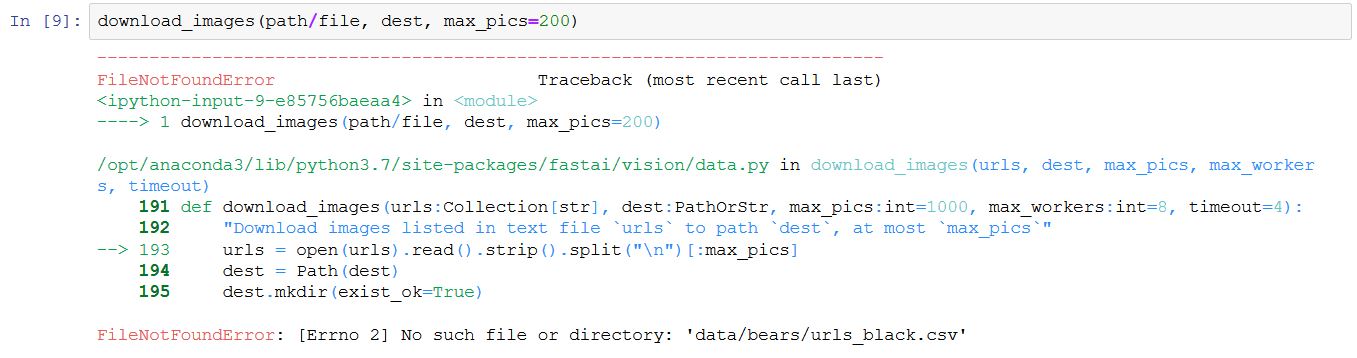
download_images(path/file, dest, max_pics=200)
but that returns:
FileNotFoundError: [Errno 2] No such file or directory: ‘data/bears/urls_grizzly.csv’
Why is that?
According to the lecture, download_images(path/file, dest, max_pics=200) is used to download
images to, in my case Google Cloud. But when I downloaded the images using
the JavaScript, the images was saved to my Mac. How do I get the images from my Mac to
Google cloud using download_images(path/file, dest, max_pics=200)?
Thank you.
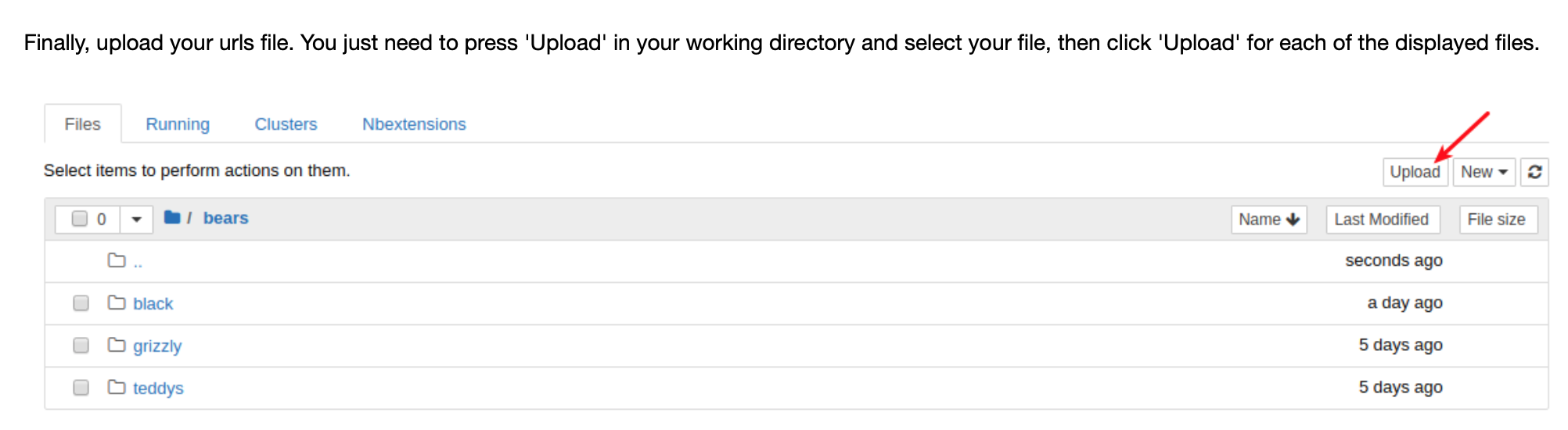
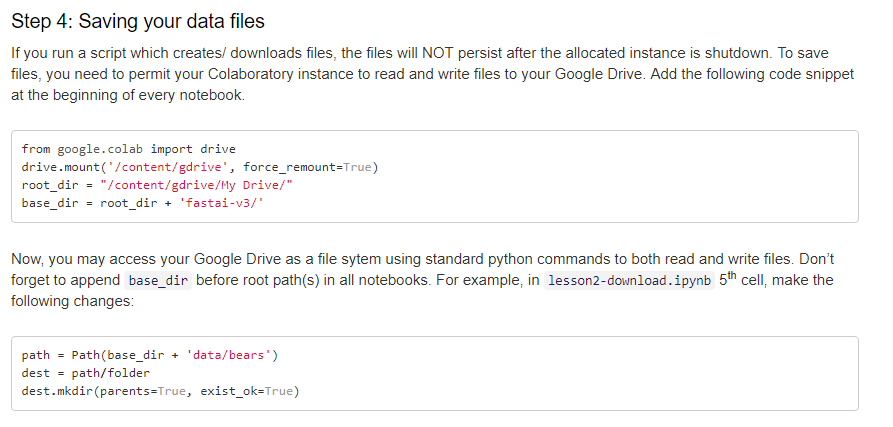
 You need to download the urls, save them in a text file and upload it on your cloud. Check
You need to download the urls, save them in a text file and upload it on your cloud. Check