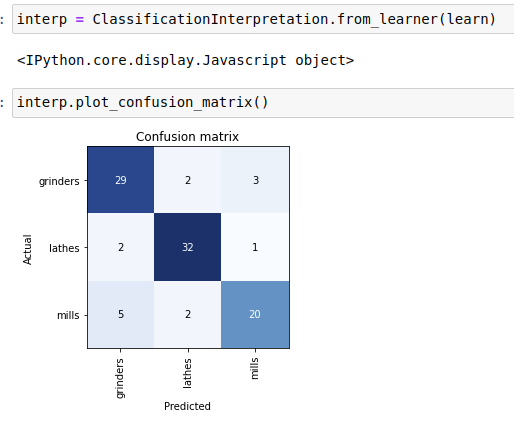
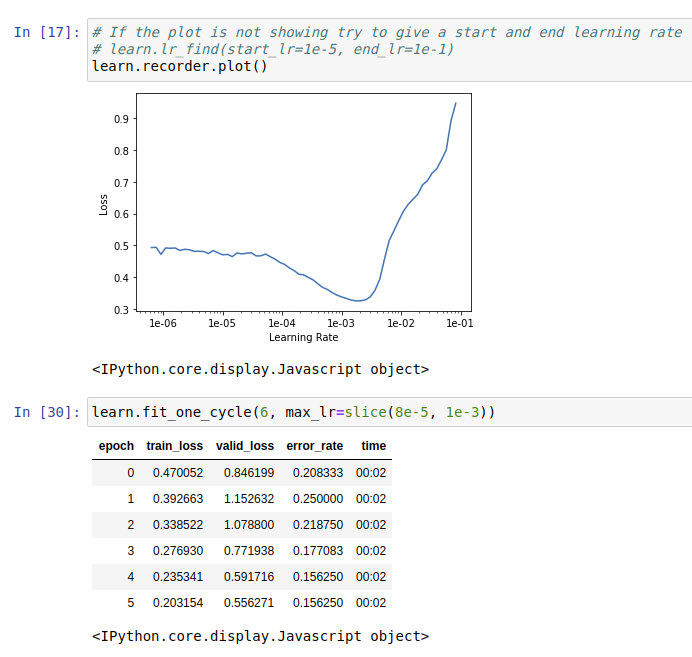
I created an image dataset of three kinds of metalworking machinery. Lathes, surface-grinders and milling-machines. After stage 2 there was a 21% error rate - which seemed pretty miserable. When I went through the ‘delete irrelevant images’ section of the notebook, there were surprisingly very few errors. Amazing really. The confidence levels seem pessimistic.
When reached the step where we are remove duplicate images. There was some sort of combinatorial explosion where every surface-grinder seemed to be flagged as a duplicate of every other surface-grinder. Interestingly none of the flagged duplicates was in fact a duplicate. I could tell the difference pretty trivially. They certainly were similar, but obviously, trivially different - at least to bipedal monkeys.
21% is not miserable when you train a model, as data can be far worse than that, in some algorithms the dataset is such the the algorithm may never converge to produce a result that is usable.
I showed your images to 3 random people and none of them could identify any of them, with any confidence. You are undoubtedly a domain expert unlike us bipedal monkeys.
Your model is exhibiting the behavior I see many models make, when the images look very similar across classes.
Although I used these machines at school and college
I can see no discerning differences between the three classes.
e.g. when you look at a cat or a dog, there is something catish about a cat and doggish about a dog. Which everyone can see even if they cannot articulate it.
Your images nearly all contain handles a bed for the material a control box etc.
I had the same problems when building classifiers for certain data-sets e.g when building a wristwatch classifer the error rate was approx 6% percent for two classes unusable with 60 classes.
I think this is the point where in kaggle competitions, people start using different models, tweeking the code and doing feature engineering to tune the model some more.
I have been wondering myself when I have this problem do I need more data eg. would 1600 or 16000 images a class help?
Hi there,
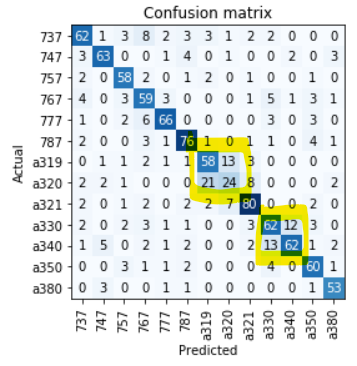
I’m dabbling with a classifier for airliners. I downloaded ~400 images of 13 aircraft types and used a pretrained resnet50 as classifier. I’m currently reaching 75.9% accuracy.
I’m wondering about two things. First, when I look at the confusion matrix, I see that the errors are not evenly distributed:
For Airbus A319/A320 that totally makes sense, these aircraft look extremely similar and are hard to discern even for me in many pictures.
For Airbus A330/A340 however, although they share a lot of features, it should be nearly impossible to confuse them, as one has two engines, the other four.
What could I do to fix this? Just throw more data/images at it? @mrfabulous1, you mentioned feature engineering, is that a viable approach for such a problem, and how would it work?
My second thought: when I plot the top losses, I get this result:
I believe Google changed their search results page a while ago, which makes it a little harder to scrape the images. I don’t know how to fix this directly, but I can recommend a nice tool for scraping Google/Baidu/Bing/Flickr. It’s called fastclass.
This runs on your local machine, however, so you will have to zip the images and upload them to your fastai environment (if you’re running it on a cloud provider).
Hey @mrfabulous1,
Ha - If you showed the pics to 3 machinists they’d know straight away - I’m not one - but grew up amongst them. Its funny - there were very few classification mistakes. It seems that the system struggled to differentiate individuals but was very good at classification.
Grinders all have a grinding wheel in-line with the moving bed, and a tray with ends to catch the waste. lathes have a horizontal axis, milling machines have a vertical axis and a tool-holder/chuck not a grinding disk and no ends on the tray to catch sparks/waste. But the rest of the bits and bobs are very similar between the mills and grinders. And all cats and dogs have ears and eyes and fur mostly
Its very reassuring what you say. I feel encouraged to keep going!
Feature engineering must be the art.
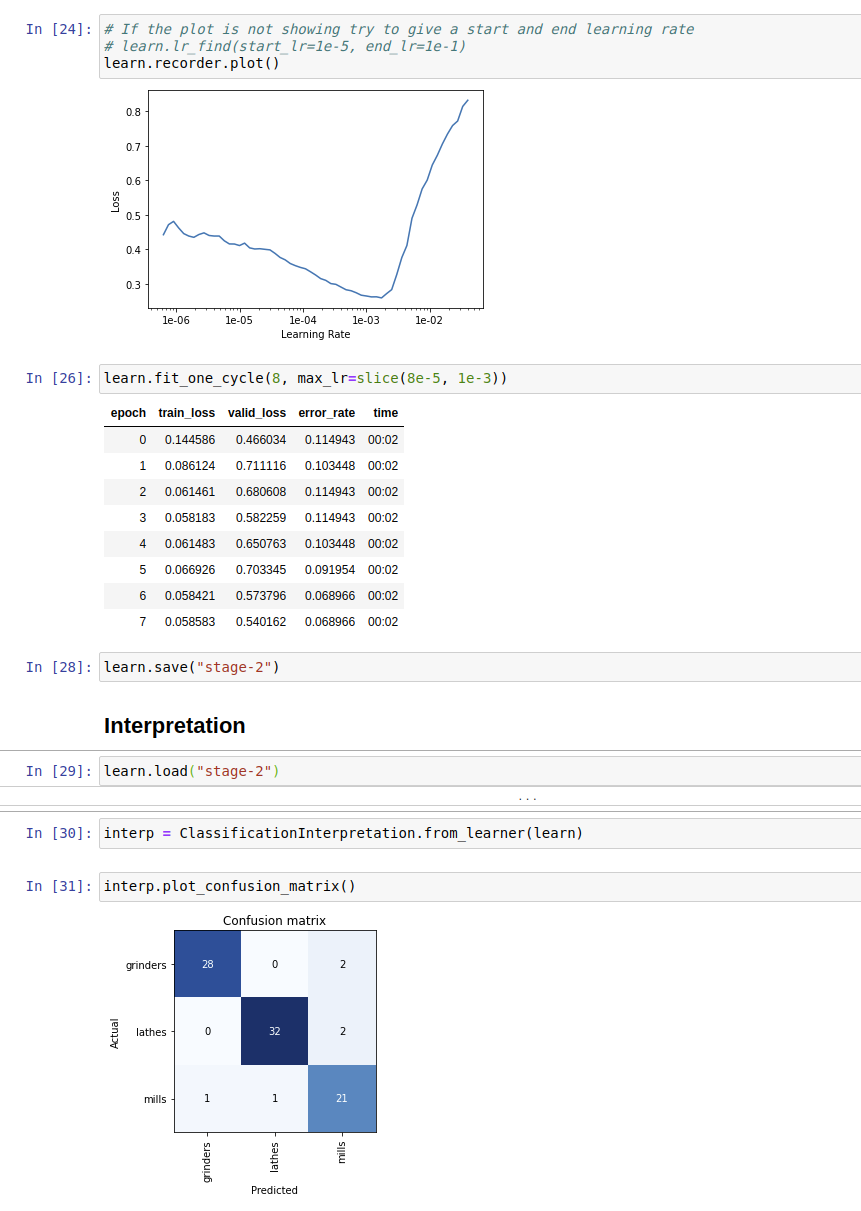
@mrfabulous1 - check this, I tried again with resnet50 on the filtered results. Pretty good i think. Must have been too lo-res for all that confusing detail…
I’ll keep experimenting with different models, augmentations, resolutions, …
I have around 400 images per category, maybe I’ll add some more and see if it helps.
Regarding feature extraction, thank you for the links. It makes sense to me on tabular data. But I’m not sure how to apply this in computer vision For example, method 3 in the second link, edge detection. Isn’t that something that a CNN should figure out for itself, via learnt (or pretrained) kernels?
The paper below is one that Jeremy uses. in one of the video’s. I think its wonderful.
The paper above gives an insight into what CNN’s are doing. There may indeed be a layer that is highly correlated to the characteristic of lathes and grinders etc.
Currently whatever one does to improve your network, its a little like a dark art, in that unless your accuracy metric goes up or down one really doesn’t know much about which layers are being used the most. But I would postulate if you could apply this paper to your network and then make changes and see what actually happens. The results would be highly interesting.
I have seen people choose use a specific layer before they fine tune.
I wonder what the inside of your model looks like.
I have downloaded bear images from google, saved them in specific folders (black, grizzly & teddy). Renamed the files as blackbear1.jpg, blackbear2.jpg etc in the respective folders.
When running the below code:
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2, ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
I am getting 2 issues (IndexError and Exception) listed below.
IndexError : index 0 is out of bounds for axis 0 with size 0
During handling of the above exception, another exception occurred:
Hi all, finally got my first ML web app up and live and wanted to share some of my experience briefly. The app and model themselves aren’t really very special, but I’ll share them here.
For me, the model building was straightforward. I was able to work through the lesson 1 and 2 notebooks without issue to download images and train my model. The accuracy was ‘ok’ at 80% and I didn’t really focus much on improving it beyond the steps in the lesson. I then both saved (.pth) and exported (.pkl) my model - this becomes important later.
From there, I basically followed the ‘Production’ instructions for the Google App Engine and I found them to be again mainly straightforward. I hit a big snag once I started trying to deploy the model though. I kept getting a massive error with tons of lines of code as it tried to run script.py. I did a bunch of debugging including:
Deploying on Render (didn’t work)
Trying to run the original example script.py (that worked)
Checking that my model_file_url worked by typing into my browser and seeing if it downloaded directly (it did)
I was starting to sweat a little bit and frantically search through the forums at this point. My eureka moment was when I downloaded the model for the original example from Dropbox and it came back as “stage-2.pth.” That is when I realized that I was using the export .pkl instead of the .pth files.
Did I miss something in the instructions? I was under the impression that we should be using the exported model instead of the saved one.
In any case, that cleared things right up and my web app was up and running. I know this was a long post/story but I’m hoping that my experience can help give someone a kickstart if needed.
I’m going to have save this thread because I’m exactly here and decided to take a breather and see if I know what I’m doing in lesson 2 before venturing on making the application. Thanks for all the tips though and I hope to make it as fancy as yours!
The code below can be used, but with some human interaction. This code is somewhat slow but returns a more complete list. Also, the code below gets the original image rather than the version stored in Google, which may be lower res or just a thumbnail. To begin with, make sure your image search results do not exceed the minimum returned by Google by default as the code takes a while to run.
So, given the search: 360 digger -toy -book -dog -"t-shirt" -leurre -hat -"total solutions" -its -antennas -"metal working" -compressor -drill copy and paste the lines below into the console.
Here’s the search for a ride-on roller -toy -battery -skates -"roller blades" -bicycle -coaster
// set up the observer
function hrefTest(mutationList, observer) {
mutationList.forEach( (mutation) => {
if( mutation.attributeName === 'href' ) {
let thisHref = mutation.target.href.split('imgurl=')[1].split('&imgrefurl')[0];
urls.push(decodeURIComponent(thisHref));
console.log(decodeURIComponent(thisHref));
}
});
}
const observerOptions = {
childList: false,
attributes: true,
subtree: false
}
const observer = new MutationObserver(hrefTest)
let urls = Array();
let anchors = document.querySelectorAll('a.islib');
anchors.forEach((a) => {
a.addEventListener('click', (event) => {event.eventTarget.preventDefault()}, {
capture: false,
passive: true
});
observer.observe(a, observerOptions);
});
Next, copy and paste the code below.
// click every image
document.querySelectorAll('a.islib').forEach((elem) => {
elem.click();
});
The code above will take time to process. On a page result of 100 images it can take 2 minutes or more. When it’s done (when all the images have finished loading), copy and paste the code below to get the final CSV.