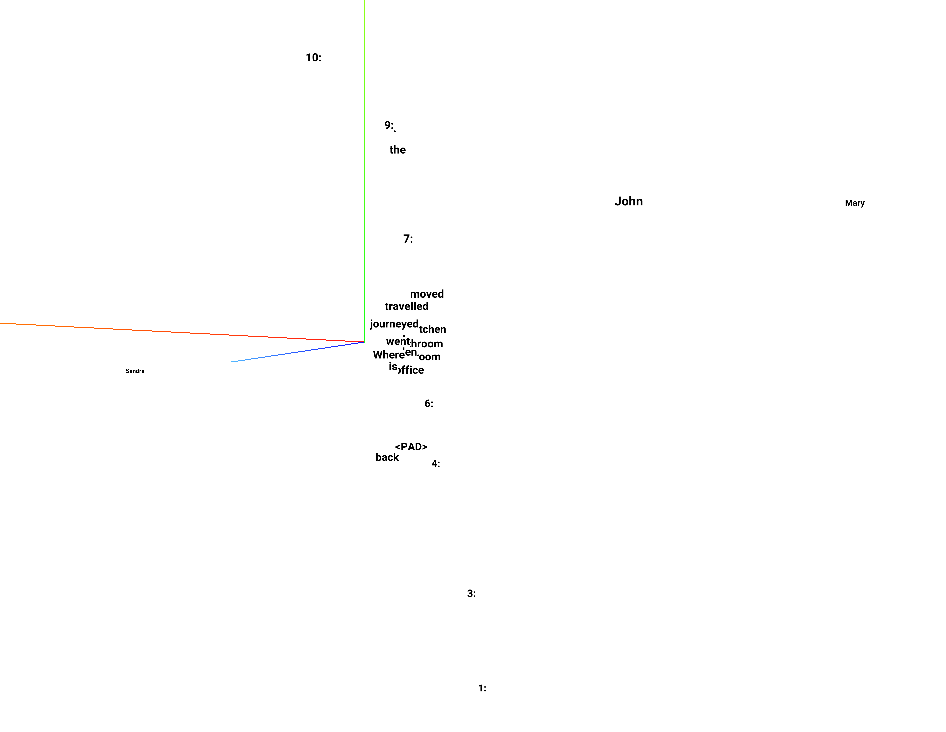
Embedding #1
Embedding
#2
Embedding
#3
I used tensorboard to visualize the embeddings using PCA for the babi-memnn notebook. I could not get this to work with t-SNE and can’t understand why.
As you can see from the pictures, you can clearly see that for embedding #1, the names are far apart, but everything else clustered close to each other with numbers being spread out.
For the question embedding, you can see that “where is ?” is clustered together and far from others and the names are as far apart as possible. You can see the reverse in the question #3 where bathroom, bedroom, etc are far apart.
The code export the embedding to tensorboard is simple, but took me a few tries.
import tensorflow as tf
saver = tf.train.Saver()
LOG_DIR = ‘/home/surya/tensorboard_log’
os.makedirs(LOG_DIR, exist_ok=True)
saver.save(keras.backend.get_session(), os.path.join(LOG_DIR, “model.ckpt”))
metadata_file = open(os.path.join(LOG_DIR, ‘metadata.tsv’), ‘w’)
metadata_file.write(‘Name\tClass\n’)
for key, value in word_idx.items():
metadata_file.write(‘%06d\t%s\n’ % (value, key))
metadata_file.close()
In your log directory, create a file called projector_config.pbtxt with the following content.
embeddings {
tensor_name: “embedding_1_W”
metadata_path: “/home/surya/tensorboard_log/metadata.tsv”
}
embeddings {
tensor_name: “embedding_2_W”
metadata_path: “/home/surya/tensorboard_log/metadata.tsv”
}
embeddings {
tensor_name: “embedding_3_W”
metadata_path: “/home/surya/tensorboard_log/metadata.tsv”
}
start the tensorboard with tensorboard --logdir=~/tensorboard_log and explore the embedding tab (look for embedding_*)
Question: If someone can play with this, can you please help me understand why the t-SNE is not as stable/reliable for this short data (32 words, size-20 embedding) when PCA does just fine?
 I think it will take me the rest of the year to catch up.
I think it will take me the rest of the year to catch up.