In the spirit of making these things more like Optimizers, it seems there could be an interesting relationship between CFG and the variance. Similar to Learning Rate and Momentum, and the way they are increased/decreased in tandem as we move through the schedule.
Also messing a bit with SLERP interpolation of the conditioned and un-conditioned latents. It starts getting a bit messy here with so many relationships and schedules, but at least from initial experiments it seems to really help with the syntax and details in an image!
That looks very interesting Do post your notebook changes so that others might help learn from it. I bet you somebody (or lot of people) will find it interesting even if you think that the changes are nothing much.
A quick story. @radek has a very interesting newsletter where he mentions how he got his first ML job. And he says: tell people about what you’ve done. I took this to heart and decided to publish a notebook I did a few days ago. The notebook did nothing major — it simply took a PDF paper from arXiv and summarized it either as a whole or page by page. This just helped me understand papers easier since all the jargon on the papers sometimes makes my head spin
I really didn’t think that the notebook was anything great since anybody could have done it. But somebody saw it and asked me if it was possible to summarize all the new papers on arXiv since they are trying to keep up with NeurIPS and there are a lot of papers. So I came up with a second version which did that. But then I realized that that could actually be useful to others. So I’m looking at making an app out of it that let’s you do a bit more than the notebook does.
So moral: do talk about what you’ve done and there’s always somebody who might find your work useful
Will do! I’ll ping back over the next few days with the fresh notebook!
Wanted to make sure I setup a fair comparison and all =)
Thank you for the kind words and write up!
Excited to open up and share with others, for all the reasons you list and more. Finally got my blog up and running proper to this end.
A small preview of an image I was able to get.
The prompt was: "a close-up portrait of a Siamese cat"
Here is the baseline, with no scaling or scheduling, just g = 7.5
Been having too much fun, here’s some more examples. Now the notebook is incoming soon =)
It seems we hit a sweet spot with the “T” scaling and Cosine schedules.
Here’s an example with using the VAE-ema from stability.ai, as well as using the Stable Diffusion 1.5 from RunwayML. The prompt was: "a portrait of a great Incan Warlord wearing his ornate ceremonial armor"
With a combination of Full-Scale guidance and a Cosine schedule, we go from the top to the bottom:
Just finished the notebook! I made it a Quarto blog post to get more practice with this new tool.
Here is the post:
The highlights:
Created a GuidanceTfm class to easily import these ideas and plug them in to any generate() loop.
Put some examples at the end using a different Diffusion model and VAE, showing that the gains hold across pipelines.
The blog also has an api/ section for short code snippets. I put the minimal GuidanceTfm there in case it’s easier for folks to use. The only dependency is pytorch to compute norms: GuidanceTfm python file
Huge shoutout to everyone in this thread! I put some acknowledgements up front in the blog post, please let me know if I missed anyone!
Nice write up I did a quick glance through but am looking forward to going through more and checking out the various comparisons of the generated images … I have this everything-but-the-kitchen-sink sort of script that I use to generate all my images and I think I’ll probably borrow some of your code to add to it and try out a few variations …
Thank you! And please do, I’d love to see the code be helpful.
I also have a parallel notebook trying SLERP interpolations of u and t, also scheduled. It seems to add a good bit of “real-life” details to the generations.
It’s very nice to see these gains for “free”, without needing more data or fine-tuning
Would love to see the SLERP interpolations when you are ready
Basically, I’m one of those people who can’t tell how good or bad an image is by just looking at it. Which is why I created the notebook comparing the various guidance variations — so that I can compare the images visually, see what looks best and then use that in production.
So your notebook with the new images is very, very helpful for me
I think I’m going to modify my code to take a parameter specifying which guidance calculation mechanism to use and then put variations in there so that I can try them out on particular images that I like and see how the output looks like. Might be helpful, at least for me, to settle on an approach (or have the ability to switch between several candidates) as I generate images through the day.
Still working on the SLERP examples, but initial results look good.
In the meantime I put together this pytorch-friendly version of SLERP that combines the best of the other numpy and torch implementations.
As for the Normalizing and Scheduling notebook, I added a helper class that removes the timm dependency and makes it a good bit easier to create CFG schedules.
The python standalone file is here: guidance_tfm.py
And I added some examples of how to use everything in the matching notebook.
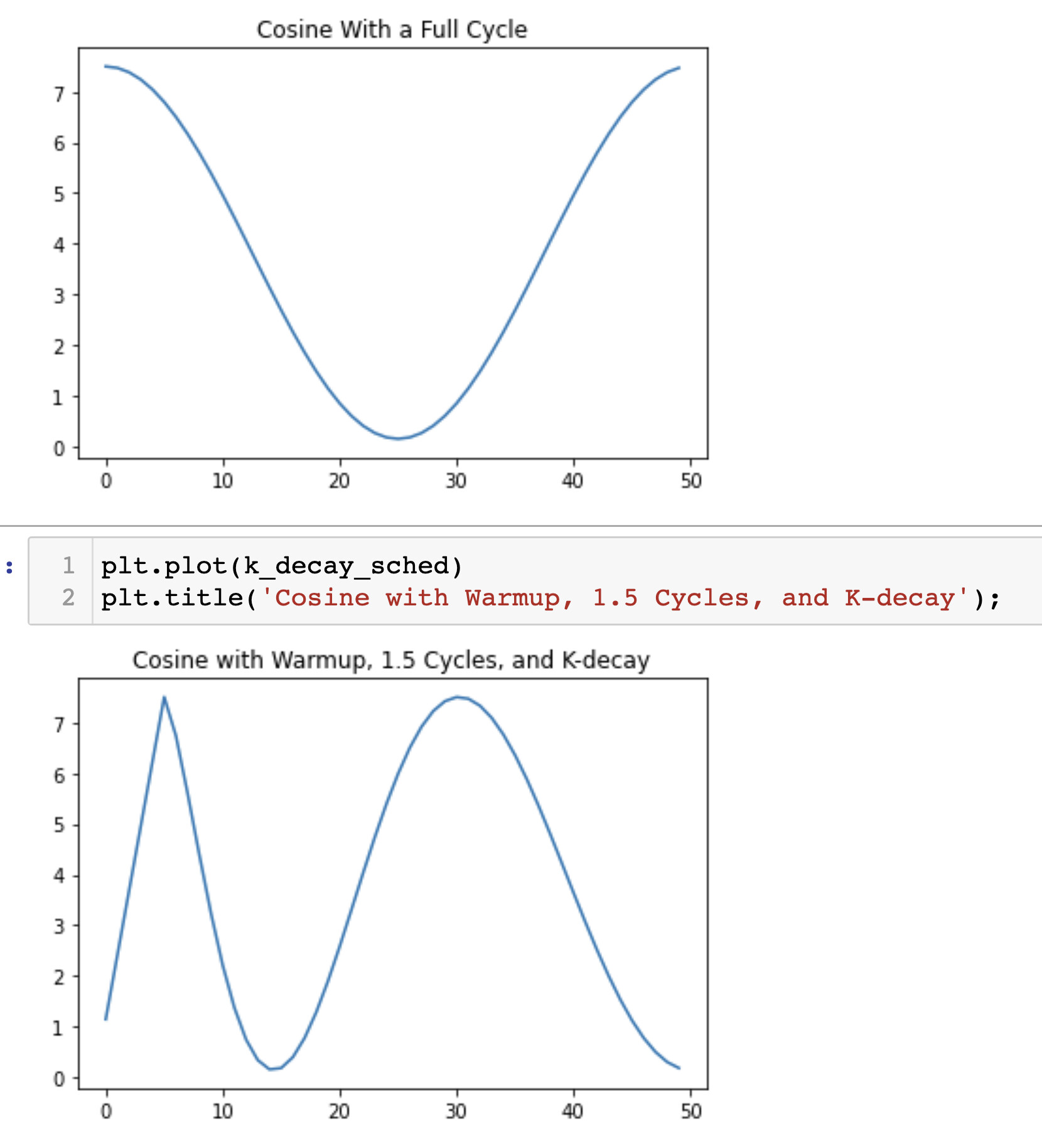
The schedule helper basically mixes the Cosine schedulers from HuggingFace and timm. It makes it possible to create some really gnarly schedules that I’m excited to explore:
Oh, this looks lovely Thanks for putting these together! I’m looking forward to reading through all of these over the weekend and figuring some stuff out … I really wanted to add the new scheduler parameters yesterday but unfortunately, it appears that I just don’t have the time for that any longer So the weekend it will have to be! But really looking forward to trying out the new variations for day-to-day image generation!
@clck10 Just got into reading your blog posts now. Really love the explanations! I completely forgot about the soap bubble blog post - having read that a few years back, but you did a great job of explaining it all with relevance to SLERP Will have fun playing with some of the results this weekend!
Been chipping at the normalization and schedule stuff in a series.
Pretty happy with the results so far. think they’re at a good spot.
Here’s some comparisons against a static, constant baseline of G = 7.5. There definitely seems to be a sweet spot in parameters.
So a mixed bag of updates with Stable Diffusion v2.
It seems the new v-objective totally breaks the normalizations we’ve been testing. We likely need to normalize the v-update itself now, or check if something else makes sense.
On the plus side! It seems that schedules still help, especially for the fp16 models! Using an inverse k-Decay as warmup has been getting me a lot more details.
The notebook also has an example of hooking in the k_diffusion library into diffusers for SD v2. There was a community example for SD v1.x, but it’s not working at the moment. Hoping to get around to a pull with the needed updates.
Belated answer about the GTX 16xx GPU family. This issue keeps coming up, and we were finally able to verify that those cards still have issues with float16, despite supposedly sharing the same compute architecture as the 1080 Ti or the 20xx family. More details here: Error running `float16` in GTX 1660 · Issue #2153 · huggingface/diffusers · GitHub (TL;DR: using “cpu offloading” and “attention slicing” might be enough to reduce memory and run inference in float32).
following jeremys advice i implemented negative prompt option in the stable diffusion notebook.
this was what i got from the prompt 'an oil painting of an astronaut riding a horse in the style of grant wood'
after implementing negative prompting and giving the negative prompt 'blue sky, clouds'
if anyone wondered why it’s possible to call
m[20,15] after creating the matrix object instead of m[(20,15)].
turns out python converts the 20,15 to the tuple object (20,15) by default
In this lesson, this is the loop in which we denoise the latents.
for i, t in enumerate(tqdm(sched.timesteps)):
# For CFG
inp = torch.cat([lats] * 2)
inp = sched.scale_model_input(inp, t)
# Predict noise residual.
with torch.no_grad(): pred = unet(inp, t, encoder_hidden_states=txt_embs).sample
# Perform guidance.
pred_uncond, pred_txt = pred.chunk(2)
pred = pred_uncond + g_scale * (pred_txt - pred_uncond)
# Compute the "previous" noisy sample.
# Not quite sure what's happening here.
lats = sched.step(pred, t, lats).prev_sample
I’m not quite understanding what the following two lines are doing.
inp = sched.scale_model_input(inp, t)
lats = sched.step(pred, t, lats).prev_sample
I think I vaguely understand the first line — it scales the denoising model input to match the scheduler, but didn’t we do something of the sort earlier with lats = lats * sched.init_noise_sigma? Or is that just scaling the initial noise?
I would appreciate clarification regarding those two lines.