There is an even faster version. I posted about it here Lesson 10 official topic - #57
1 Like
@pcuenq your suggestion to use pipe.enable_attention_slicing() indeed did work! A mere 1650Ti seems able to run inference on the SD model. Super interesting. However, I ran into an interesting problem - I was getting only black images as outputs. I then played around with the inputs a little bit after reading this to try and get to understand why they were being marked as “NSFW”, but I’m unable to figure it out (please see screenshots below):
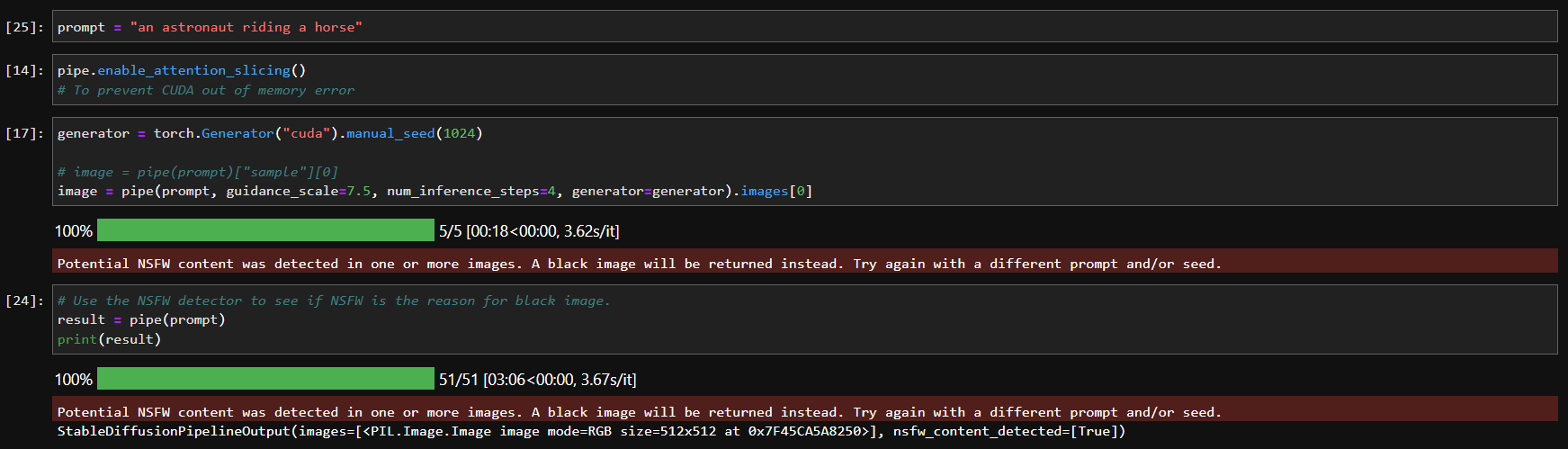
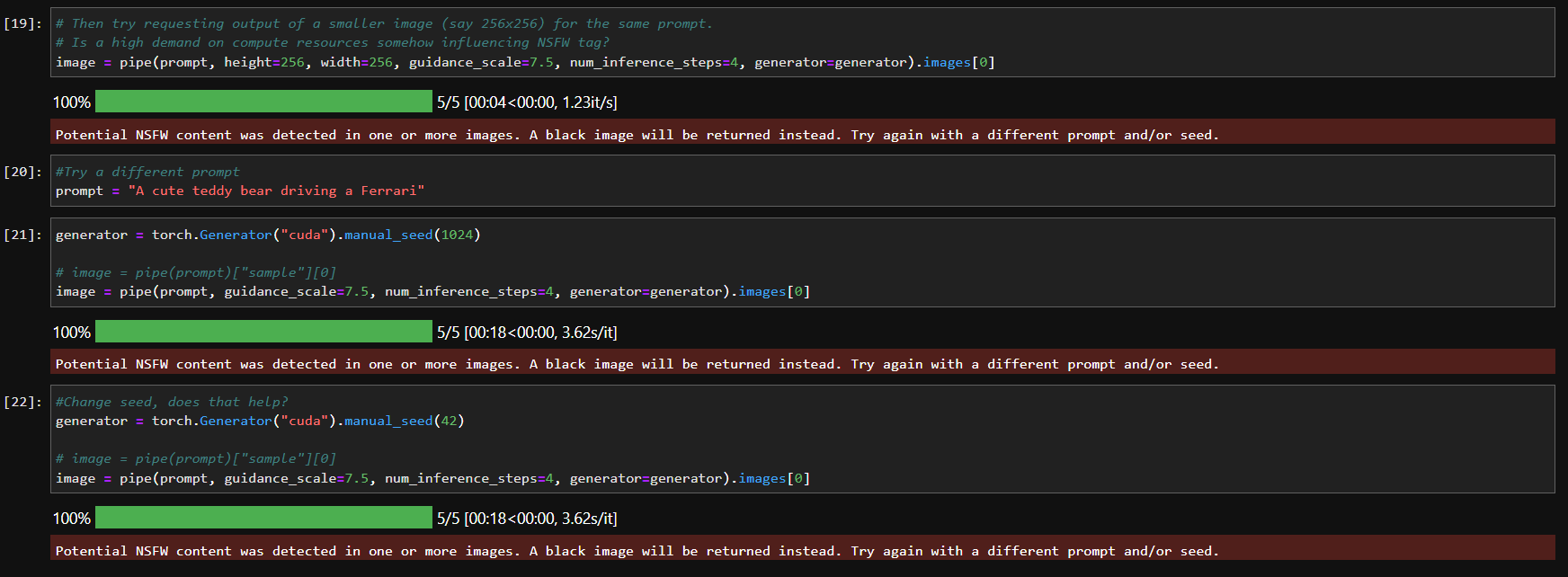
If anyone has any insights on this it’d be great! It seems to be a very curious situation.
PS: If this should’ve been a post on the Lesson 9 Official Topic, I’ll move it there. For now I’ll assume it’s appropriate to post here since the discussion began here.
3 Likes
Glad to hear you got it working!
The NSFW flagging is because of the safety checker which is by default on. You can turn it off like this:
3 Likes
Thanks for your reply, @ilovescience!
I tried to switch off the safety checker as shown:
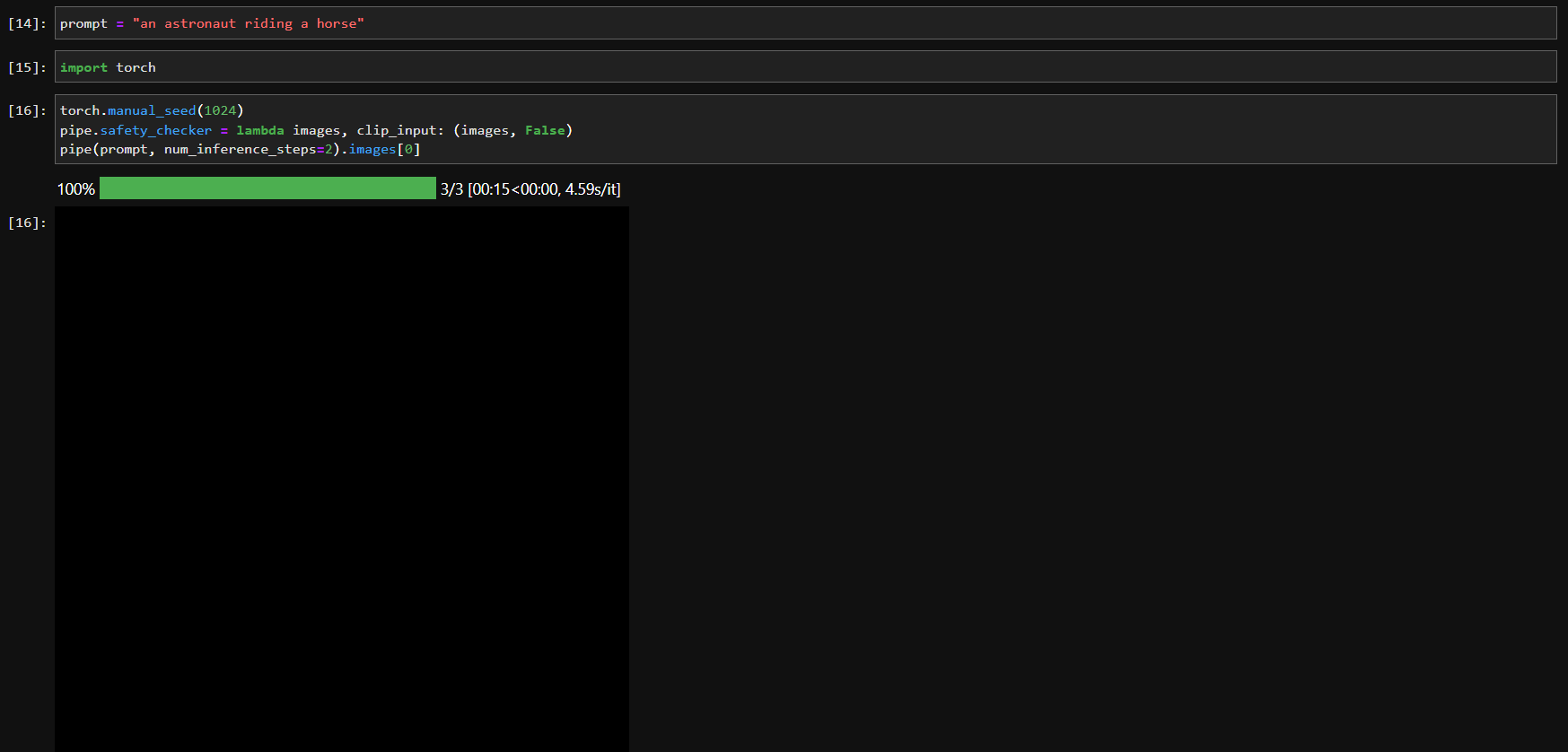
The output is still a black image, and printing the model output shows that NSFW tag is
False.
Then I tried this method from @pcuenq :

Here’s the result:
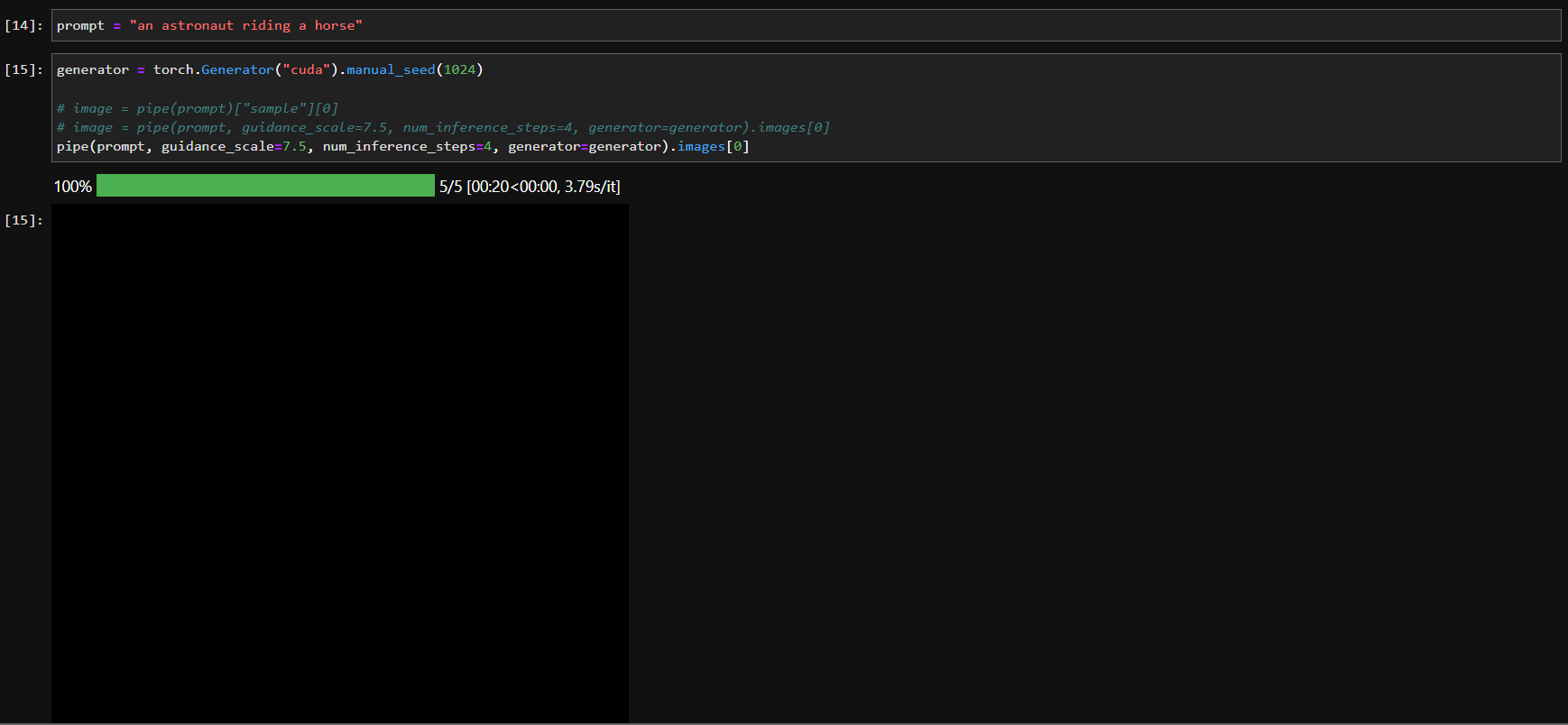
The model output, showing the
nsfw_content_detected values as None :
How am I seeing a black image despite the NSFW filter apparently being switched off? Am I making any mistakes here?
One that I use and have tested, is to uninstall HF diffusers and install a custom version of diffusers by using
pip install --user git+https://github.com/huggingface/diffusers.git@e895952816dc4a9a04d1d82fb5f8bdee59341c06
One more method which I have tested is to disable the code for safety check in installed packages manually show by @cjmills. More details here
1 Like
@vettukal thanks for your suggestions.
Tried the first - uninstalling the HF diffusers and installing a custom version, but that still yielded a black image.
Then I checked this post:
Since we have an updated diffusers library (0.6.0, as of today), the modification suggested by @cjmills is in essence the same as passing in safety_checker=None during pipeline creation, as suggested here:
Regardless, I did give it a go - manually switched off the safety checker in the pipeline_stable_diffusion.py script, imported StableDiffusionPipeline again and still saw a black image as output. As mentioned in my previous reply, the NSFW warning is gone, but the image output is the same! Suspecting that a low value of num_inference_steps might somehow be causing the problem, I tried bumping that up to 42, but that didn’t work either.
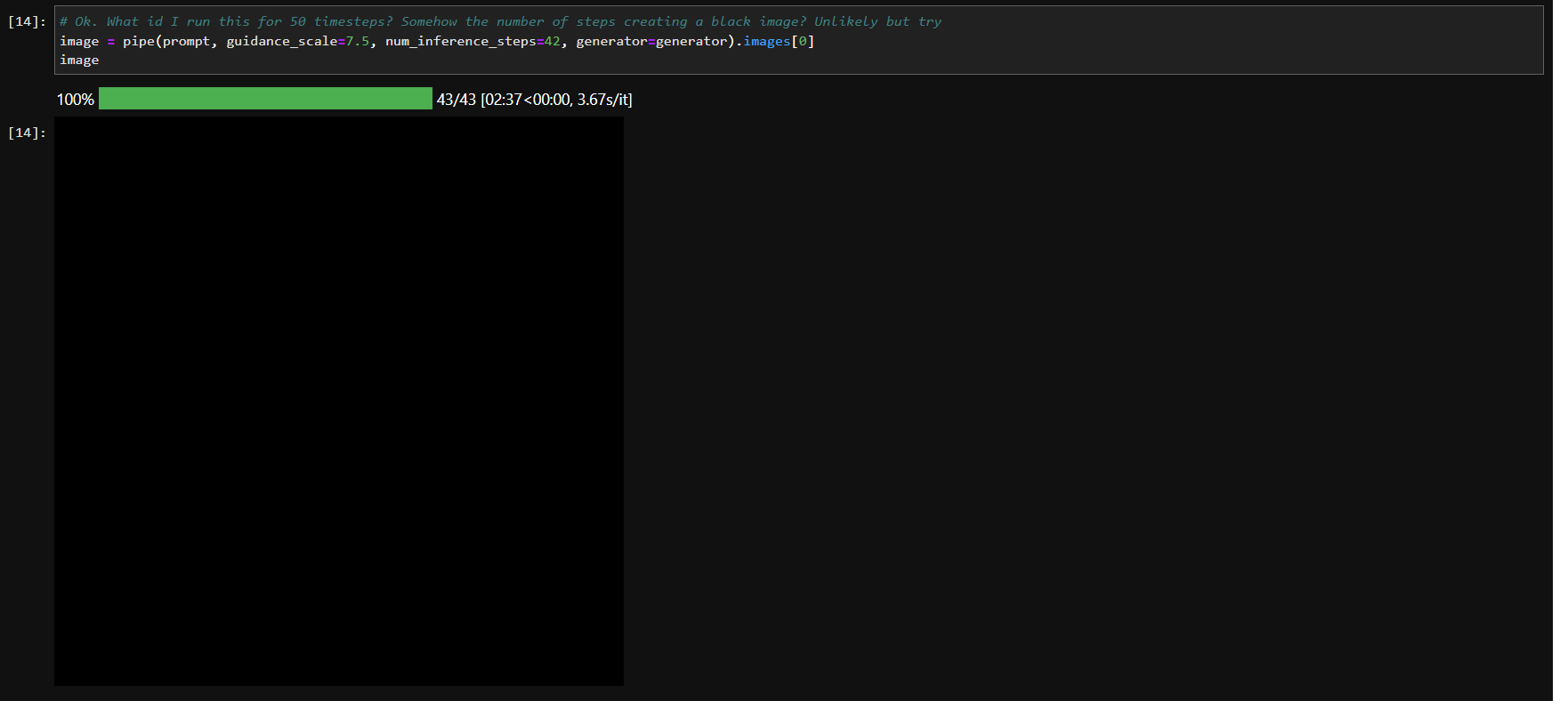
If anyone has any insights on this, please do let me know. Any other alternative directions to explore as to why the model keeps giving a black image output even with the safety checker turned off?
(Apologies for spamming the forum with questions about this one issue!)
Hi @james.em, I agree with you that it doesn’t look related to the safety checker. I’m thinking maybe there’s some sort of limitation in that card, beyond the RAM? My understanding is it’s the same architecture as, for example, the 1080 Ti, and I know people that successfully use this one with diffusers. If you don’t want to use the general forum for this one topic maybe you can start a new one, or you can send me a private message with the code you use and I’ll try to reproduce (although I don’t currently have any GPUs of that family).
3 Likes
The random generator bug seems to be a common issue among many libraries: Random fork-safety - OpenSSLWiki
2 Likes
I honestly don’t think it’s a bug. I think it’s the intended behaviour (otherwise reproducibility would not be possible in a parallel context). There are (complicated) ways around it like documented here for numpy, for example.
In fact this is documented in the python docs:
By re-using a seed value, the same sequence should be reproducible from run to run as long as multiple threads are not running
With python, seed does not give you reproducibility when multithreading. Useful for us, but a blocker in other contexts
Hey, did anyone try the new Stable diffusion model, v1-5.
@pcuenq thanks for the detailed reply. It’s interesting to think that the black image output could be because of some limitation in the card apart from the RAM. Sending you a private message now, and I’ll start a new topic for this issue if it’s worth investigating further. With Paperspace Pro and Lambda credits I suppose our time might be better spent elsewhere ![]() .
.
1 Like
Yes, I re-ran lesson 9 notebook with it. It looked no better for these examples.
3 Likes
In the lesson, @jeremy suggested trying out implementing tricks like negative prompts. So I attempted to implement the Img2Img pipeline. Here is the end result of the working implementation:
Original image

Generated image for prompt “A watercolor painting of an astronaut on a beach”

It did a good job of preserving the astronaut’s pose.
Trying to implement it I learned a lot more and gained a much better understanding of how the pipeline works =)
Here is the notebook link if anyone’s interested.
11 Likes
Yes, I’ve had some success with v1.5. Not drastically different from 1.4, but better in some regards (faces, lighting).
I made a FastAPI server to make it easy to change and pre-cache the models, and make more use of half precision. It can render 512x512 in about 5 seconds on an RTX 2080 via a simple REST call.
The safety filter is on by default but can be disabled with a parameter. Instead of black frames, it returns a random teddy bear running happily through a field. ![]()
1 Like
Might be a common issue. But I would not call expected behaviour, a bug.
Not handling the situation (or consequence) is the bug. ![]() A fork is expected to be the same initially. If you need a different seed or any other different setting, then the programmer is responsible for changing that.
A fork is expected to be the same initially. If you need a different seed or any other different setting, then the programmer is responsible for changing that.
Hey,
I’ll run this model over the weekend. Since this doesn’t look like a Stability AI model, do we still have the huggingface auth requirements.
Yes you do. And technically, it is a Stability.AI model. Although it’s not been released by CompVis. Let’s say that it has been… a troubled release
1 Like
But specifically for OpenSSL it is a bug. I mean since they were not handling this situation.
2 Likes
Was just watching the paper video for “Progressive Distillation for Fast Sampling of Diffusion Models” and it struck me that even though the number of inference steps required to get to a decent image are much reduced, the training time is more or less the same (or even actually longer?). Am I understanding this correctly? Are we displacing the inference time onto the training time (and resources?) somehow with this progressive distillation approach with student and teacher?
5 Likes
True, you do need to log into HuggingFace. I see they released the ckpt files for v1.5 as well, but this was easier to integrate.
It’s a uvicorn app, so to run it with sdd.py in the current directory: uvicorn sdd:app --port 9999. A pip install -r requirements.txt on this file should install everything you need.
Then connect to http://localhost:9999/docs/ to browse the API.