I’m a bit confused about the noise_pred, whether it is the seed noise at t0 or the noise at current step. I’m trying to reason through this myself, but am still fuzzy.
As far as I understood, the unet model predicts the noise present in a latent. Since we have a latent for text as well as an unconditional prompt(empty string), the noise_pred variable will contain the noise for both these latents as two separate tensors(i.e, one tensor containing the noise of text latent and the other for the noise in unconditional latent).
I’m not too sure what you mean by seed noise. But let’s look at pseudo-code for training:
x0 = batch # sample from data
noise = torch.randn(size) # Noise from a gaussian distribution
sigma = scheduler.sigmas[random timestep] # Some sigma value
noisy_x = x0 + sigma*noise # Combine x0 with scaled noise
model_input = scale_model_input(noisy_x) # Scale for model input
model_pred = unet(model_input, t, ...) # Model output
loss = mse_loss(model_pred, noise) # Model output should match (unscaled) noise
pred_x0 = noisy_x - sigma*model_pred
So the model output tries to match the noise (which was drawn from a normal distribution). I think this is what you mean by ‘seed noise’. The ‘noise at current step’ is just that scaled by sigma.
This is just a design choice of the people training this model. You could also have the model output try to match x0, or the current noise (i.e. noise*sigma), or some other funkier objective. They choose to do it this way so that the model output can always be roughly the same scale (approx unit variance) despite the fact that the ‘current noise’ is going to have wildly different variance depending on the noise level sigma. Whether this is the best way is up for debate - I’m not convinced myself
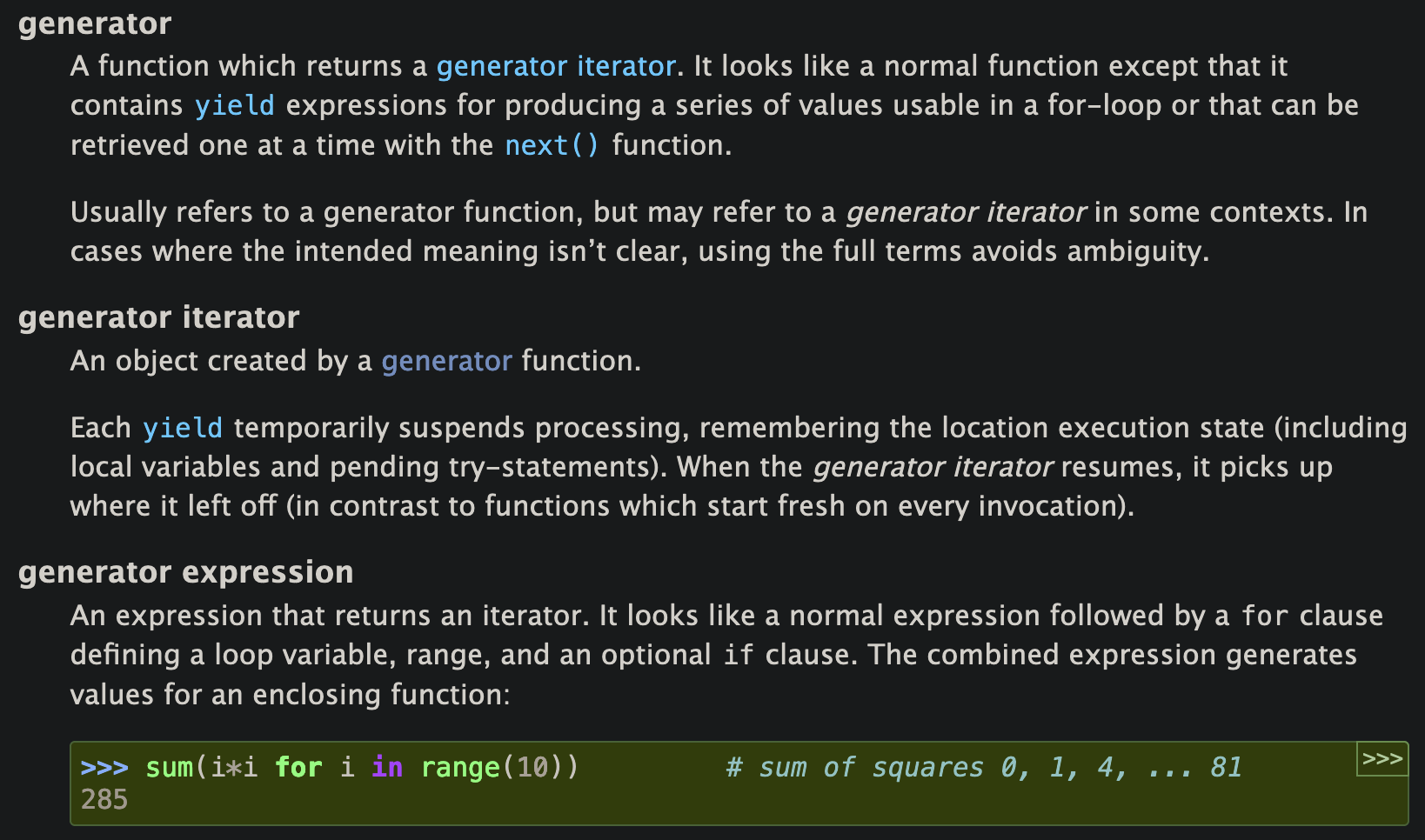
reading python docs on generators and iterators and i am a bit confused what’s the difference between the two. will sleep on it. maybe will be more clear tomorrow
I think I got a working version of negative prompts implemented. I feel like the way I implemented the subtraction of the negative prompt is wonky though, any way I could approach it better?
Here’s your equation, replacing the vars with single letters:
u + (g*(t-u)) + (g*(u-n))
We could distribute g over both bits:
u + g*(t-u+u-n)
…then cancel the u’s:
u + g*(t-n)
Not sure if I’ve messed up any of the algebra there, but it if not, sounds like you can simplify the equation a bit. It makes sense to me intuitively that the “direction” you want to head is the difference between the prompt and the negative.
The example in the video showed 4 very dissimilar pairs of matched pictures and captions. But what if some of the pics/captions were very similar? Say there were 3 different pictures all containing swans with captions like “a graceful swan”, “a lovely swan”, and “a swan on a lake in a park”. These should all be much more similar to each other than they are to “fast.ai logo”.
Is there some mechanism to allow for similarity for off-diagonal pairs? So the loss would be small for any of the swan related captions paired with any swan related pics? Or does penalizing everything except the diagonal work well enough?
Yes, TV-grained type of noise works on pixels. Latent noise works on latent space and when vae.decoded()/‘enlarged’ back into pixels it looks what Jeremy showed.
Does anybody know a resource to get some intuition on how outpainting works? It’s something I’d like to try, but I cannot really think of how to make it work.
I had implemented the negative prompts simply using it instead of the empty string for the unconditioned predictions. It seems to be working for me, but put it in this way (i.e. start with the unconditioned and move in the direction of prompt - negative prompt) it makes no sense. I am effectively starting from where I do not want to be and heading in the direction I want to be. I will try to see if I can test the two side to side
Edit: Sorry Jeremy: I replied to the wrong post, I meant to reply to Philip’s
Thanks. I had seen that, I was wondering whether anybody has seen a blog post or a paper or an article. I am looking for some intuition rather than the actual implementation at the moment
You can also just replace the unconditional prompt (blank string) with the negative prompt since we move ‘away’ from that already. But your way is nice since it generalizes - you could do several positive prompts and several negative ones with a separate weight (guidance scale) for each.
So I have run some quick experiments with negative prompts to understand a bit better what was going on. Essentially I tried the following
Using the negative prompt instead of the blank string (as @johnowhitaker suggests). That is pred = g * (t - n) + n
Using @Turkey / Jeremy approach, which makes more intuitive sense (why start from the point you want to move away?) so pred = g * (t - n) + u
Using a somewhat hybrid approach: pred = g * (t -n) + g * (t - u) + u. Apart from empirical consideration, my gut feel about this is that I want to first move away from the unconditioned image in the direction of the prompt, and then move in the direction of the negative prompt.
Same as 3, but with halved g, since I am otherwise moving away too much from u
these are some results. The original image, with the prompt “A busy street in Paris on a summer day”.
These are approaches 1-4 with the negative prompt “trees”. You can see they are all different looking at the bottom right corner. Interestingly enough approach 3 is the one that removes more completely the trees, followed by 4 (which I prefer, since too high of a g tends to oversaturate). Also approach 3 feels way less summery.
Same exercise, but this time the negative prompt is “eiffel tower”. Approaches 1 and 2 modify the trees in a way that makes them more tree-like, but further away from the original one. Approach 2 introduces some weird artifacts at the end of the street, though. 3 and 4 are very similar, but I do prefer 4 as it is more natural (and more similar to 1 and 2).
All in all I think I would stick either to 1 for simplicity/performance reason, although it makes less intuitive sense to me, or possibly modify approach 4 as to be able to weight the secondary prompt and distribute the g among them (with the possibility of adding both positive and negative weights).