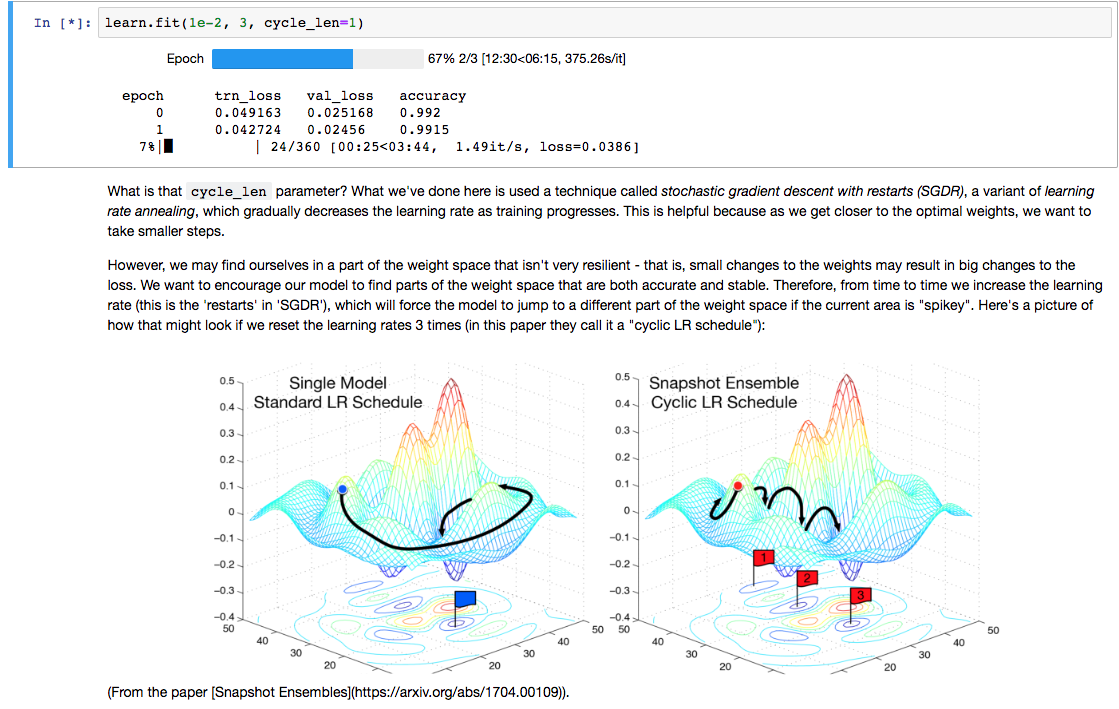
I just started with lesson 1 on my workstation with a threadripper 1950X and a 1080 TI and the first time where you train something properly after data augmentation and setting precompute to false my performance tanks. Feels a bit off. But I am lacking something to compare it to.
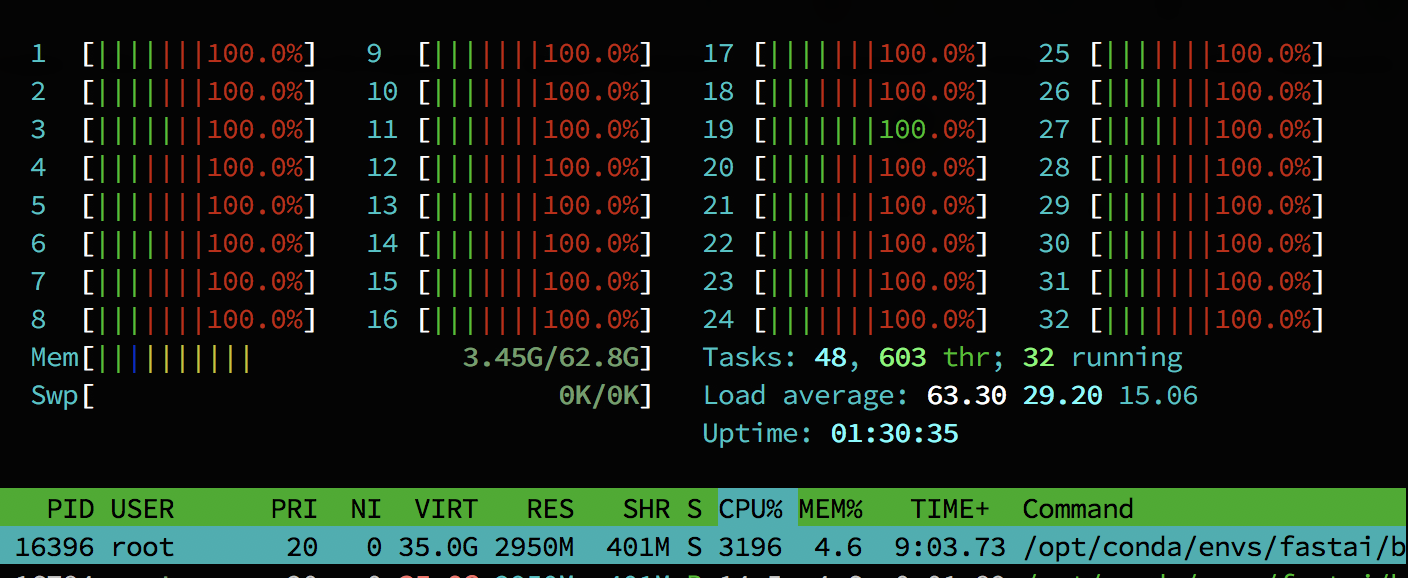
The gpu is utilized every 10th second to about 20%. All 32 cpu threads are at 100%. I assume this is mostly the augmentation but it seems way too slow, right?
Any words of advice, is that normal? Is that due to unoptimized AMD cpu support?
and Nvidia Titan XP
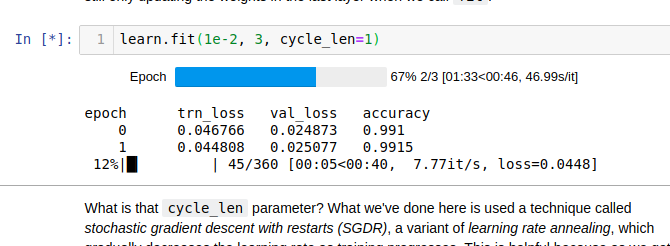
I tried to take a snapshot at the same point as yours above so you can compare
The 3 cycles ran in 2’20’’
When looking at nvidia-smi results in terminal while it’s running, i see % utilisation going up to 60%-70% often. So 20% seems a bit low on yours it seems.
These 2 lines at the top of your notebook return True I suppose ?
torch.cuda.is_available()
torch.backends.cudnn.enabled
I’m running all this on windows with Ubuntu 16.04 partition
I was able to debug this further and it seems to be due to the use of MKL in the docker build i took from herewith this dockerfile
What I found is that just having MKL installed will use 32 “threads”. I air quote that because a single MKL thread will somehow use 8 threadripper cores. So the default of 32 threads is causing that congestion.
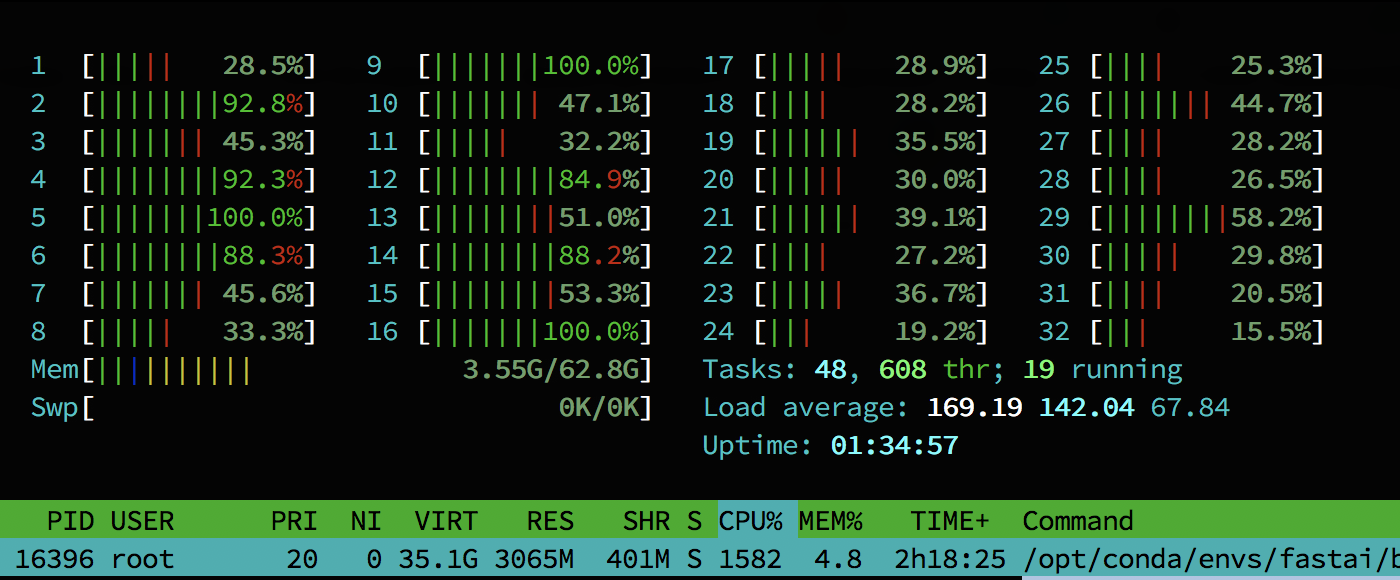
At least that’s the behavior I observed because if I set it manually to 1 thread via mkl.set_num_threads(1) (from https://docs.anaconda.com/mkl-service/) it uses 8 logical threadripper cores which also brings it down to your 47 seconds per epoch. 2 threads => 16 cores is slowing it down slightly as well
Confusing. The performance with MKL is still better than without. But I have no idea where that 1 thread => 8 core thing comes from or even better, how to predict this. Do you have MKL enabled? I guess I could remove it completely. But it does bring a small speed gain
Suspect something is wrong with your CUDA install. I would confirm the gfx card is being used as per hugues’ suggestion. I do not see all 32 threads at 100% on my 1950x for lesson 1.
I tried hard to make the whole thing work under Docker but did not manage, all sorts of issues. Don’t think it was the Docker file you are pointing to though.
its seems very much MKL related. And I can’t seem to remove it from fast ai. Just removing mkl itself from the environments.yml is not enough, guess its somewhere in the fast.ai lib
writing this now in case someone has a similar problem:
this is how it looks like without changing anything. mkl reports the use of 32 threads (via mkl.get_max_threads()) but as soon as i run it starts 256 new threads, 8 for each mkl one and a single epoch takes more than 5 minutes to train