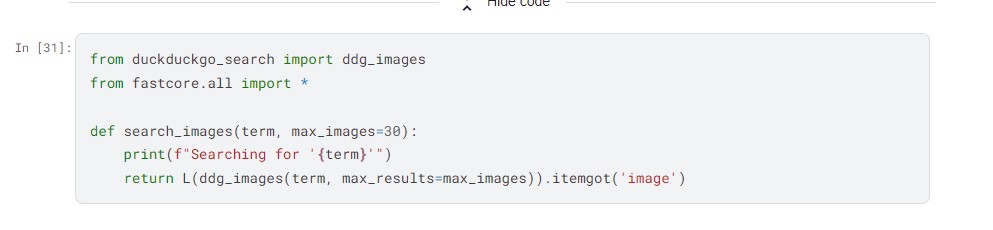
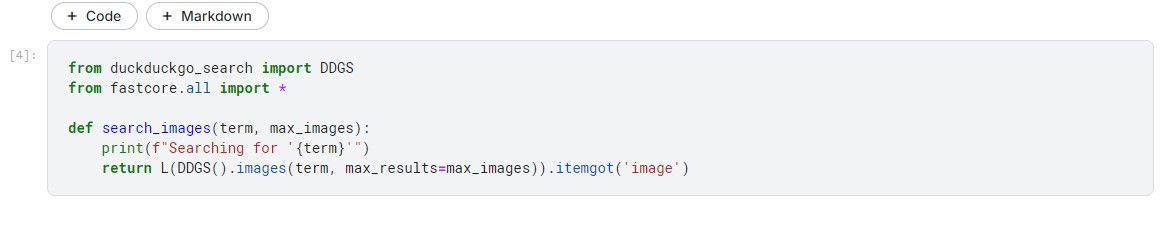
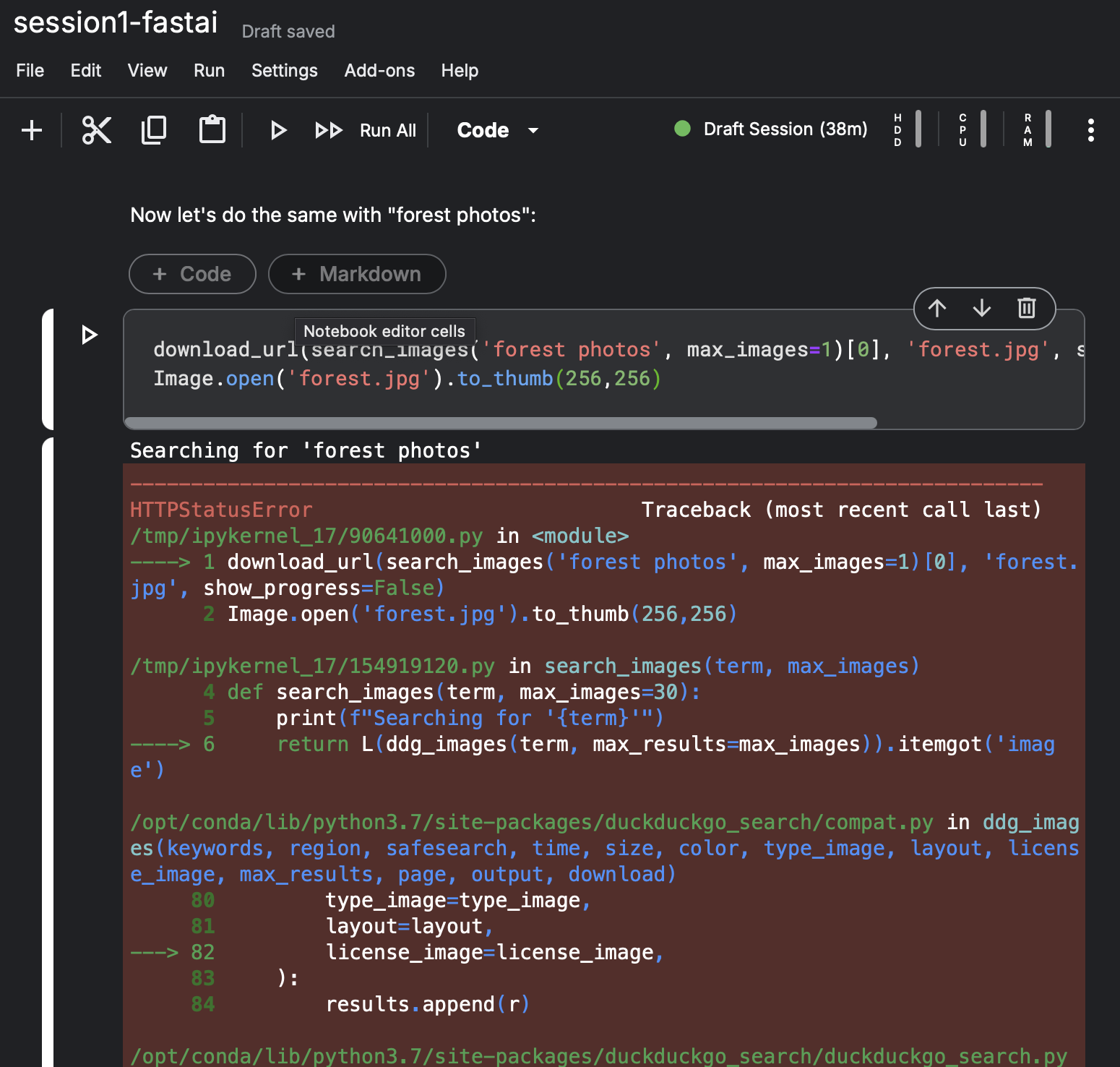
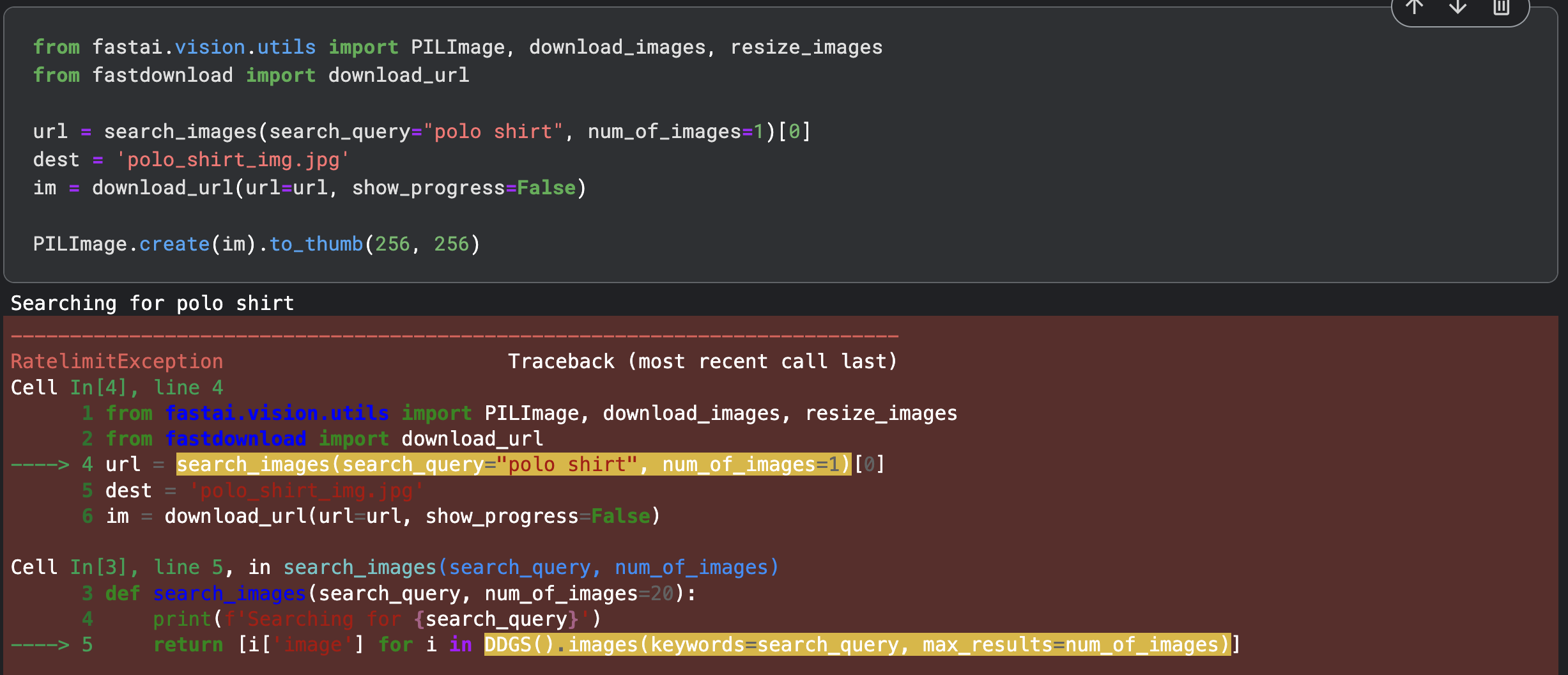
Hello all,
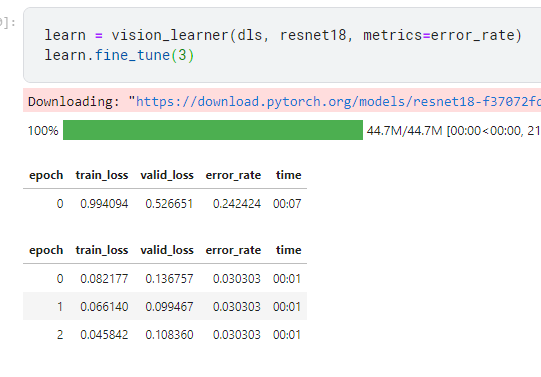
I ve made the cat vs dog model into model that distinguishes lemons from limes and it all works fine in a notebook.
I am now looking to transform this model into Core ML for my iOS app using TorchScript and Apple official guidelines for coremltools.
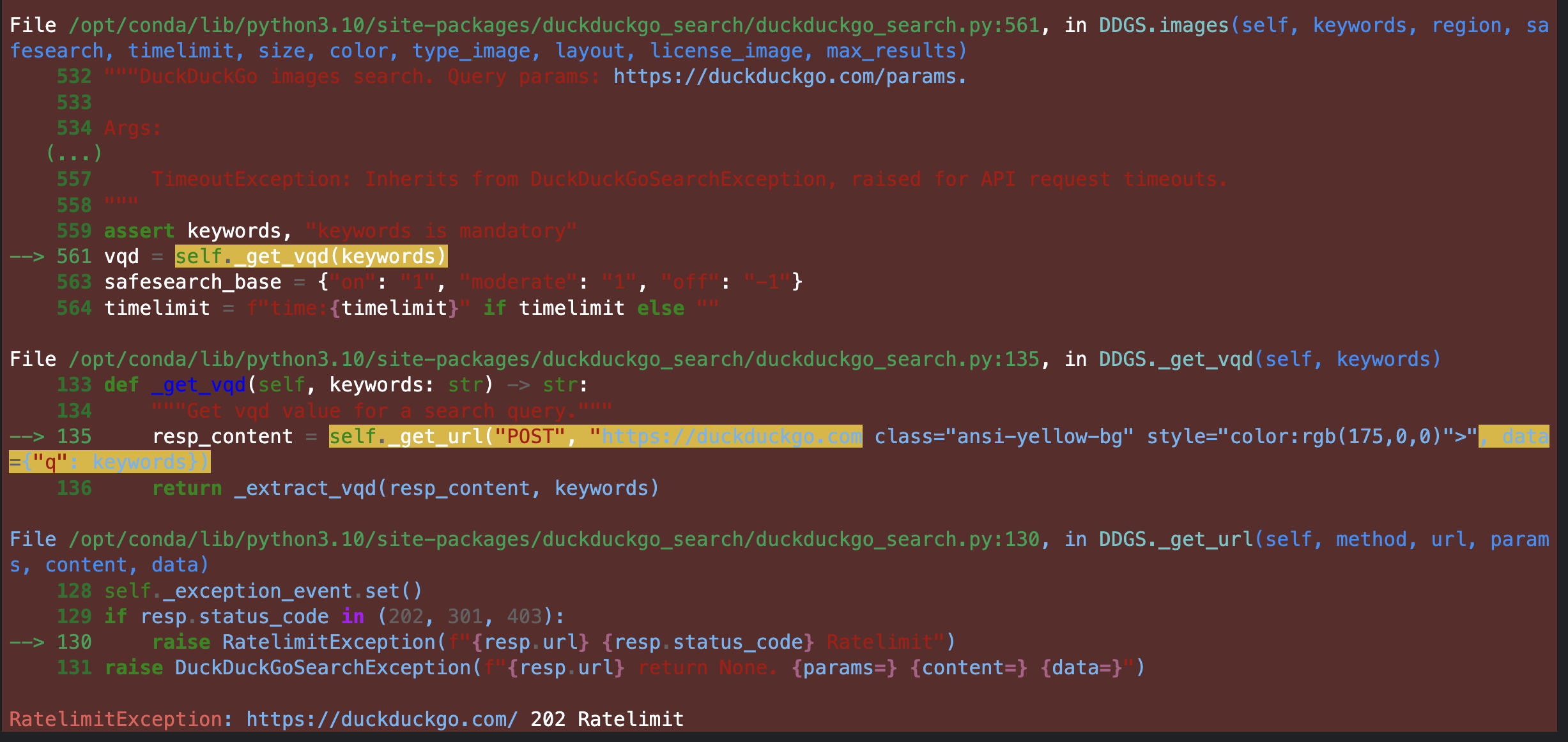
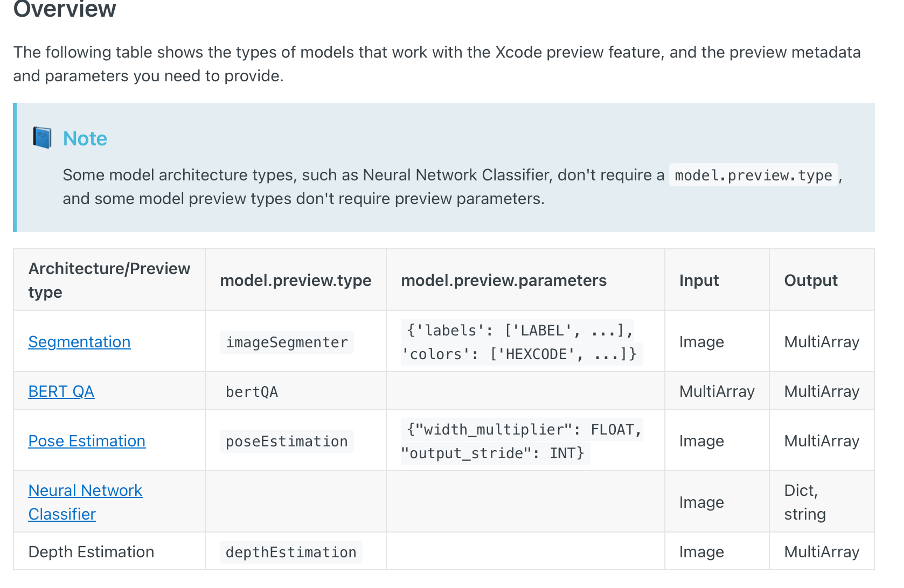
Model covers but I cannot see the Preview Tab in. Xcode. Have anyone of you tried to convert to Core ML? I guess my input types are not matching with coremltools expectations for preview but I am stuck . Here is my code.
import torch
import coremltools as ct
from fastai.vision.all import *
import json
from torchvision import transforms
# Load your Fastai model (replace with your actual path)
learn = load_learner('lemonmodel.pkl')
# Example input image (you can use any image from your dataset)
input_image = PILImage.create('example.jpg')
# Preprocess the image (assuming you used these transforms during training)
to_tensor = transforms.ToTensor()
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
input_tensor = to_tensor(input_image)
input_tensor = normalize(input_tensor) # Apply normalization
# Add a batch dimension
input_tensor = input_tensor.unsqueeze(0)
# Ensure float32 type
input_tensor = input_tensor.float()
# Trace the model
trace = torch.jit.trace(learn.model, input_tensor)
# Define the Core ML input type (considering your model's input shape)
_input = ct.ImageType(
name="input_1",
shape=input_tensor.shape,
bias=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
scale=1./(255*0.226)
)
# Convert the model to Core ML format
mlmodel = ct.convert(
trace,
inputs=[_input],
minimum_deployment_target=ct.target.iOS14 # Optional, set deployment target
)
# Set model type as 'imageClassifier' for the Preview tab
mlmodel.type = 'imageClassifier'
# Correct structure for preview parameters** (assuming two classes: 'lemon' and 'lime')
labels_json = {
"imageClassifier": {
"labels": ["lemon", "lime"],
"input": {
"shape": list(input_tensor.shape), # Provide the actual input shape
"mean": [0.485, 0.456, 0.406], # Match normalization mean
"std": [0.229, 0.224, 0.225] # Match normalization std
},
"output": {
"shape": [1, 2] # Output shape for your model (2 classes)
}
}
}
# Setting up the metadata with correct 'preview' params
mlmodel.user_defined_metadata['com.apple.coreml.model.preview.params'] = json.dumps(labels_json)
# Save the model as .mlmodel
mlmodel.save("LemonClassifierGemini.mlmodel")
mlmodel = ct.convert(
trace,
inputs=[_input],
minimum_deployment_target=ct.target.iOS14 # Optional, set deployment target
)
# Set model type as 'imageClassifier' for the Preview tab**
mlmodel.type = 'imageClassifier'
# Correct structure for preview parameters** (assuming two classes: 'lemon' and 'lime')
labels_json = {
"imageClassifier": {
"labels": ["lemon", "lime"],
"input": {
"shape": list(input_tensor.shape), # Provide the actual input shape
"mean": [0.485, 0.456, 0.406], # Match normalization mean
"std": [0.229, 0.224, 0.225] # Match normalization std
},
"output": {
"shape": [1, 2] # Output shape for your model (2 classes)
}
}
}
# Setting up the metadata with correct 'preview' params**
mlmodel.user_defined_metadata['com.apple.coreml.model.preview.params'] = json.dumps(labels_json)
# Save the model as .mlmodel
mlmodel.save("LemonClassifierGemini.mlmodel")