Option 1 works well. Very simple to address.
Can you share the notebook with the fix? I can’t seem to get it working
I implemented option 1 originally mentioned here: Lesson 1 official topic - #608 by SergeyF
However I have received the following error


After failing to implement Option 1, I implemented Option 2 and also received an error. Any ideas how this can be resolved?
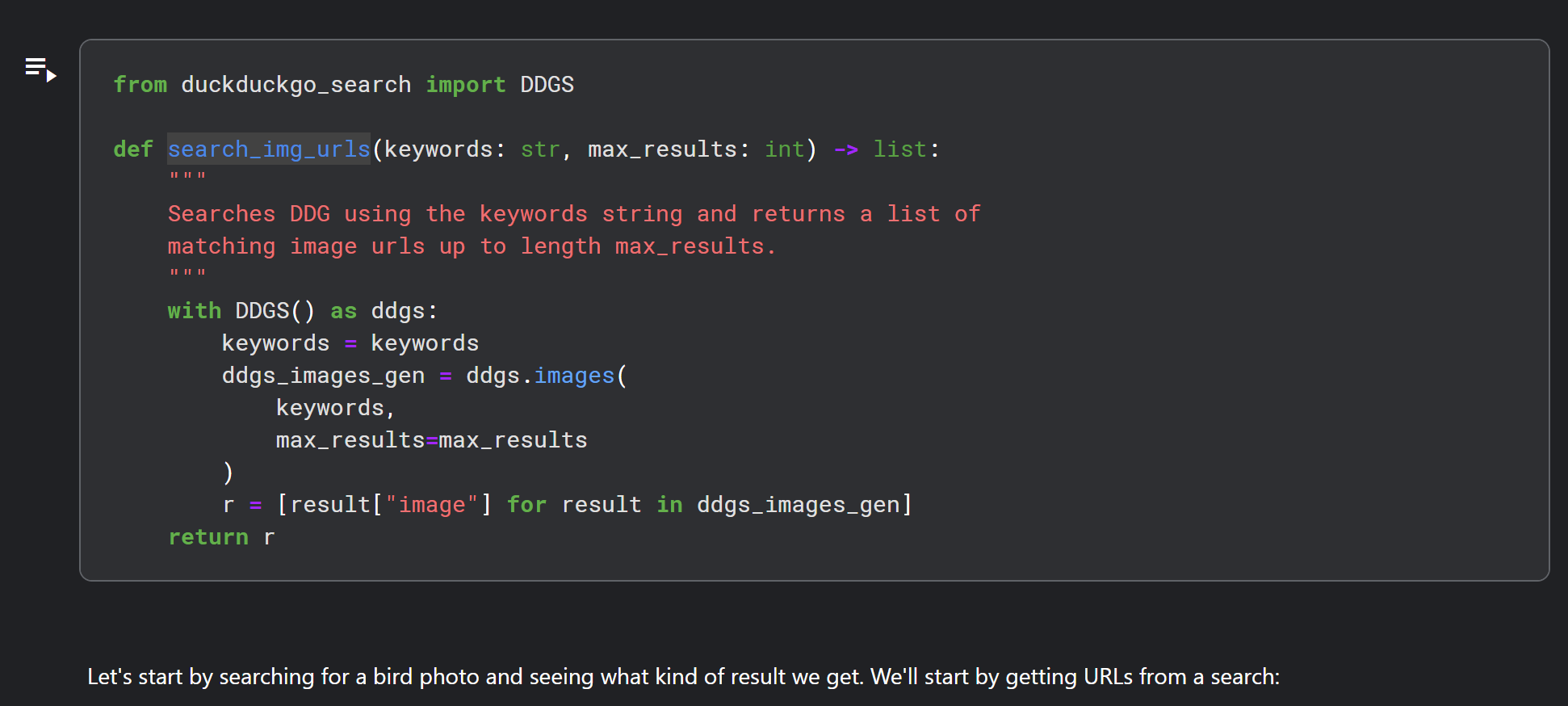
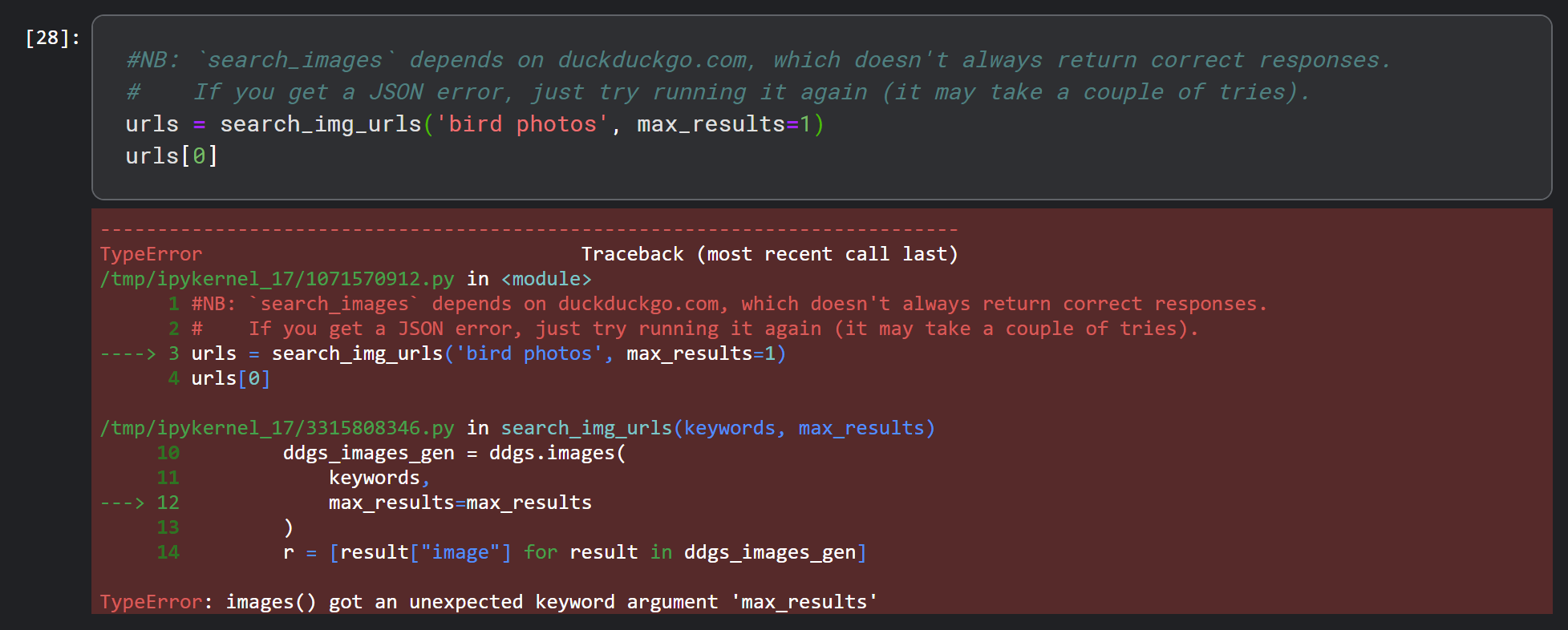
Hi Muhammad – did you also get this error from the very first piece of code?
Code snippet:
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
Error / warning:
/opt/conda/lib/python3.10/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
And it takes ages for the code to run.
Best,
BY
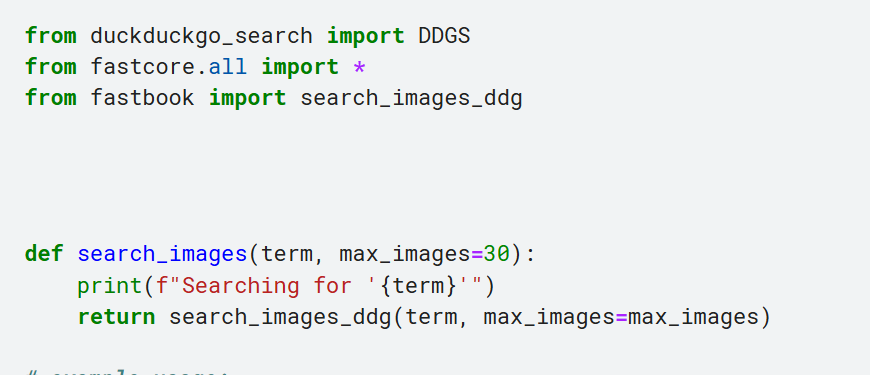
Here is corrected function
def search_img_urls(keywords, max_images=30):
print(f"Searching for '{keywords}'")
with DDGS() as ddgs:
search_results = ddgs.images(keywords=term, max_results=max_images)
image_urls = [result.get("image") for result in search_results]
return L(image_urls)
you wrote it slightly different:
keywords=keywords not in the list of parameteres of the function ddgs.images()
The algorithm uses name of folders in which photos are stored and use these names as a labels for prediction.
If you download cars photo in the folder bird then the algortihm will write bird in the prediction.
This is what fixed things for me, thanks!
[Question] The text justifies the use of the test data by stating that, “Just as the automatic training process is in danger of overfitting the training data, we are in danger of overfitting the validation data through human trial and error and exploration”.
While I understand how a human could overfit hyper parameters for the validation set, I don’t see how a test set solves this problem. If you train a model using the training data, validate it using the validation set, and then get poor test set results, wouldn’t you just go back and change up the model so that you get better test set results? And thereby re-introduce the problem of human overfitting?
Best advice. Thank you !
You are supposed to use the test set only once. If your model fails on the test set, you need to get a new test set. From what I know.
I’m facing similar issue too.
Hey all, I’m getting a RateLimitException when downloading the images from duck duck go (see screenshot). Do we need to increase the sleep time in the program so it doesn’t throttle the server?
Thanks in advance.

option 1 so good!! thanks a lot!!
Hi Aieh,
I’ve just started the course (absolute beginner) and ran into exactly the same problem. I see you posted this in March with no answer yet. Did you ever figure it out or are we just stopped dead in our tracks in cell 2 of lesson 1?
To answer my own question, I think that it is a good course, and worth doing. I love the ‘working code first, then explanation’ model. The dependency errors are due to pythons pathetic version management, which I guess isn’t the course creators fault. Until python library developers adopt, and stick to, some sort of semantic versioning they’re inevitable. Lately I’ve been just working through the book, handling the dependency problems as I strike them. They do seem to have reduced as I go through.
This is awesome Sergey! Thanks so much!
I have the same experience: ran the notebook as-is to train on bird and forest. The model seems to classify bird and forest photos really well. However, when asked to classify photos of something else (shark, ocean, sun, …), it seems to always label them as “bird”.
I can see the model not being able to classify things it was not trained for but it seems odd to be biased toward “bird” and not “forest”.
I want to implement a fastbook module function search_images_ddg directly on Kaggle without importing to understand how that function is exactly working. I found the code at GitHub - fastai/fastbook: The fastai book, published as Jupyter Notebooks in utils.py , but it gives error:
TypeError: search_images_ddg() got an unexpected keyword argument ‘max_images’
After changing the argument name in the defined function, it returns : Token Parsing Failed ! with error : ‘NoneType’ object is not subscriptable
Can anyone please help, What can I do to implement search_image_ddg directly from kaggle notebook?
Were you able to run the original fastai notebook from the book? Assuming that you copied-pasted the code from that link, it looks like your code errored out at this line (searchObj is null).
My guess is that the request to duckduckgo does not return the same content as it was, so searching for vqd ... does not work anymore.
I’ve switched to using
from duckduckgo_search import DDGS
foo = DDGS().images(keyword)