Hello, everyone,
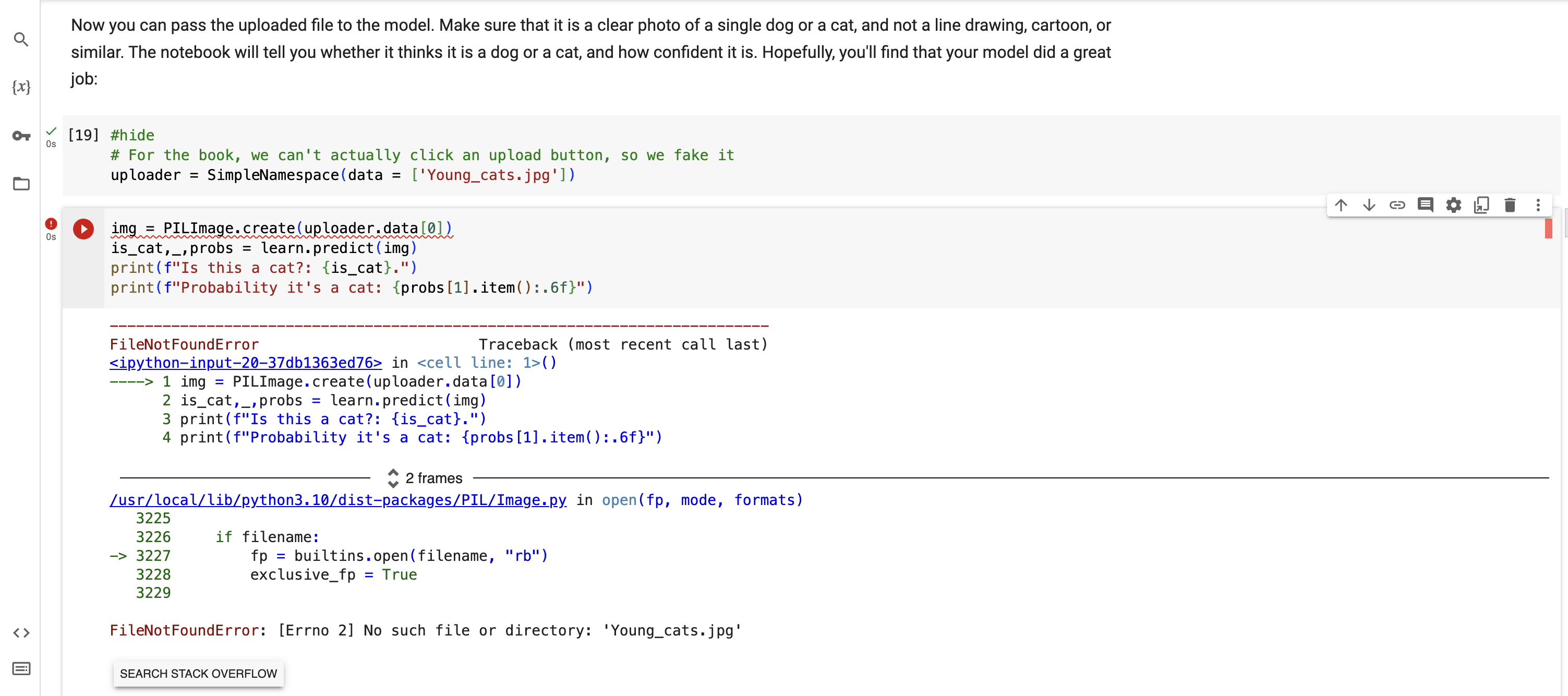
I’m studying lesson 1 and I got stuck while executing the search_images() block in kaggle. I made sure I had the network turned on but I still got an HTTPError. Any help would be appreciated.
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
/tmp/ipykernel_17/3262053840.py in <module>
1 #NB: `search_images` depends on duckduckgo.com, which doesn't always return correct responses.
2 # If you get a JSON error, just try running it again (it may take a couple of tries).
----> 3 urls = search_images('bird photos', max_images=1)
4 urls[0]
5 print(urls[0])
/tmp/ipykernel_17/1717929076.py in search_images(term, max_images)
4 def search_images(term, max_images=30):
5 print(f"Searching for '{term}'")
----> 6 return L(ddg_images(term, max_results=max_images)).itemgot('image')
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/compat.py in ddg_images(keywords, region, safesearch, time, size, color, type_image, layout, license_image, max_results, page, output, download)
80 type_image=type_image,
81 layout=layout,
---> 82 license_image=license_image,
83 ):
84 results.append(r)
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in images(self, keywords, region, safesearch, timelimit, size, color, type_image, layout, license_image)
403 assert keywords, "keywords is mandatory"
404
--> 405 vqd = self._get_vqd(keywords)
406 assert vqd, "error in getting vqd"
407
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in _get_vqd(self, keywords)
93 def _get_vqd(self, keywords: str) -> Optional[str]:
94 """Get vqd value for a search query."""
---> 95 resp = self._get_url("POST", "https://duckduckgo.com", data={"q": keywords})
96 if resp:
97 for c1, c2 in (
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in _get_url(self, method, url, **kwargs)
87 logger.warning(f"_get_url() {url} {type(ex).__name__} {ex}")
88 if i >= 2 or "418" in str(ex):
---> 89 raise ex
90 sleep(3)
91 return None
/opt/conda/lib/python3.7/site-packages/duckduckgo_search/duckduckgo_search.py in _get_url(self, method, url, **kwargs)
80 )
81 if self._is_500_in_url(str(resp.url)) or resp.status_code == 202:
---> 82 raise httpx._exceptions.HTTPError("")
83 resp.raise_for_status()
84 if resp.status_code == 200:
HTTPError: