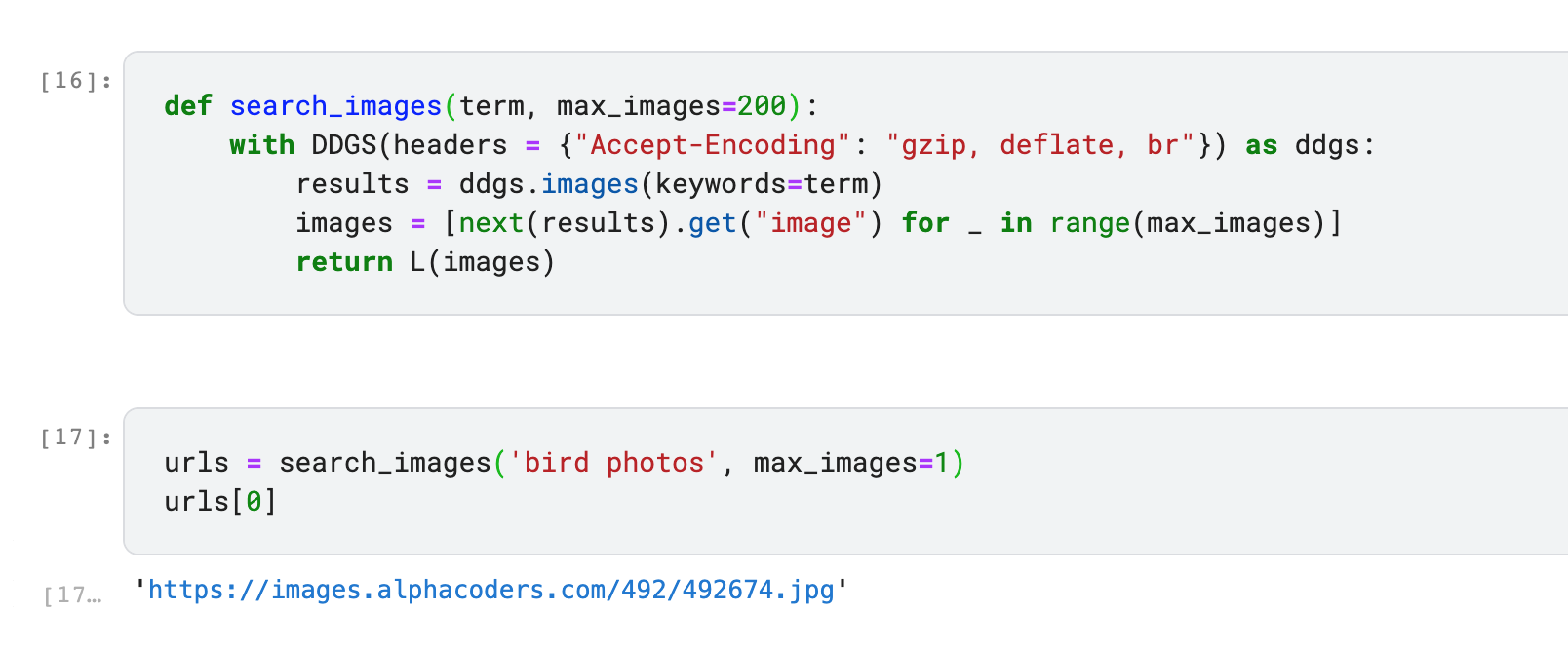
I found this GitHub issue which lists a solution to pass the dictionary {"Accept-Encoding": "gzip, deflate, br"} to the headers parameter of DDGS as follows:
def search_images(term, max_images=200):
with DDGS(headers = {"Accept-Encoding": "gzip, deflate, br"}) as ddgs:
results = ddgs.images(keywords=term)
images = [next(results).get("image") for _ in range(max_images)]
return L(images)
I tested this in a Kaggle notebook and it seems to work: