I want to respectfully give the feedback that I don’t like the initial “bird detector” example in the 2022 part 1 course.
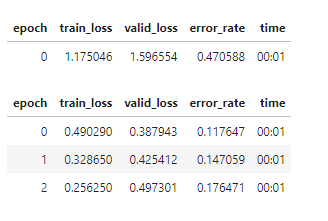
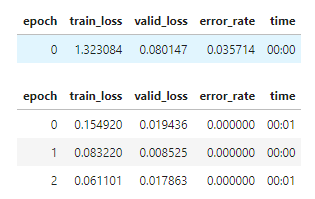
The XKCD cartoon asks us to “check whether the photo is of a bird”. The notebook says that “today, we can do exactly that, in just a few minutes”, but the model we train doesn’t come anywhere close to meeting that goal.
For example, I tested it on an image of a cow, and it told me it was likely a bird. This makes sense, as a cow is more similar to a bird than to a forest, but that’s not a very reliable bird detector! I certainly wouldn’t trust any similar model to detect potentially dangerous creatures such as bears.
I spent a few hours trying to train a more reliable “bird vs anything else” detector, and it wasn’t trivially easy, and I didn’t succeed to my satisfaction. My last attempt gave 60% false positives when I tested it against a collection of 100 random animals, so I think it has a ways to go yet. I don’t think it would take five years and a research team, but I don’t think we can do it in just a few minutes either, at least not using this method.
I did like the initial examples from previous versions of the course, especially the breeds of cats and dogs example, as it was very impressive and I can’t distinguish all those breeds myself. Those classification examples had a limited domain of acceptable input photos, and they worked well.