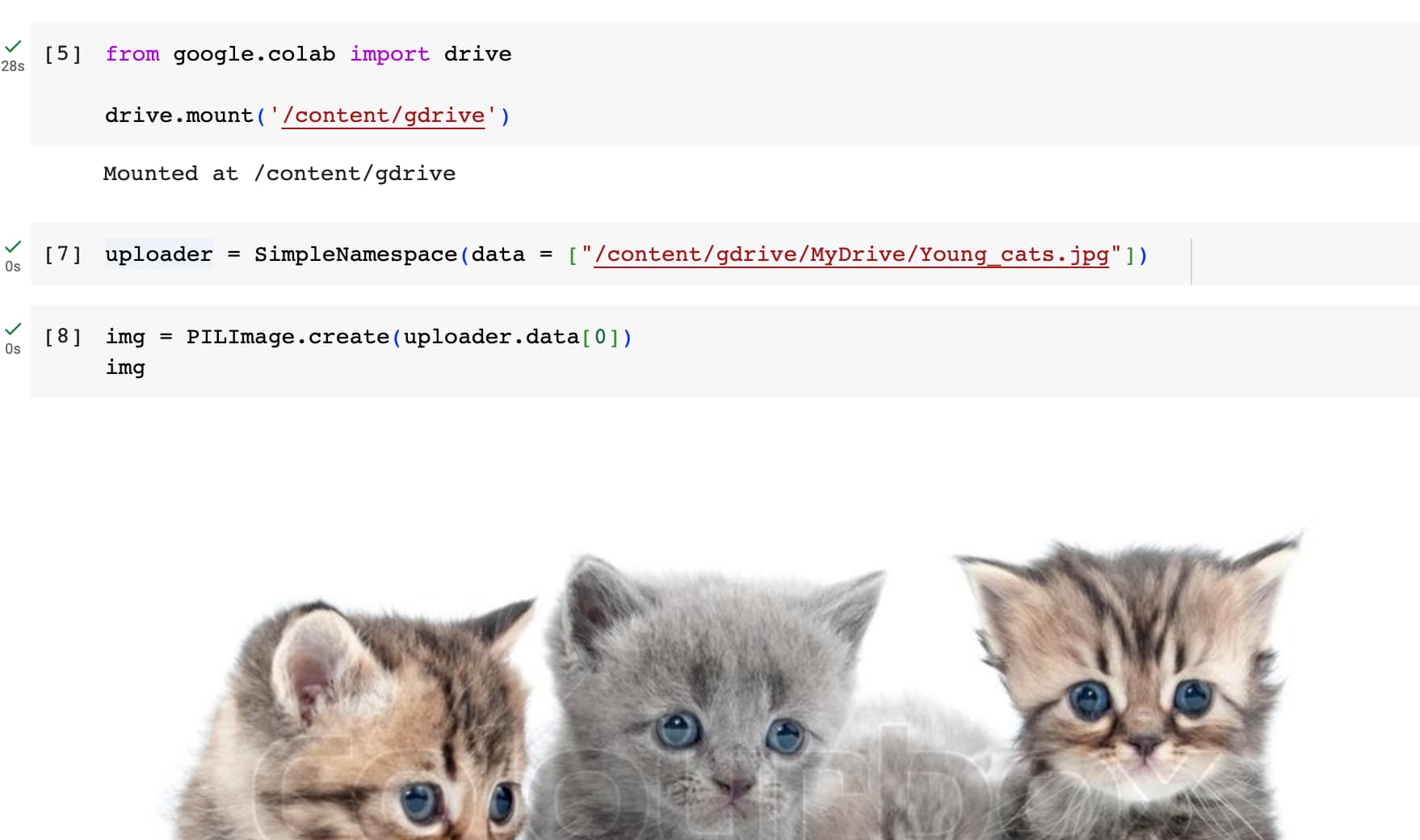
Here’s a couple of ways to resolve this error:
You can “Upload to session storage” an image that’s titled “Young_cats.jpg” which will then make the rest of the code work. The only downside to this approach is that once you disconnect from your Google Colab runtime, it will delete the uploaded image and the next time you start a new session you will have to upload the image again.
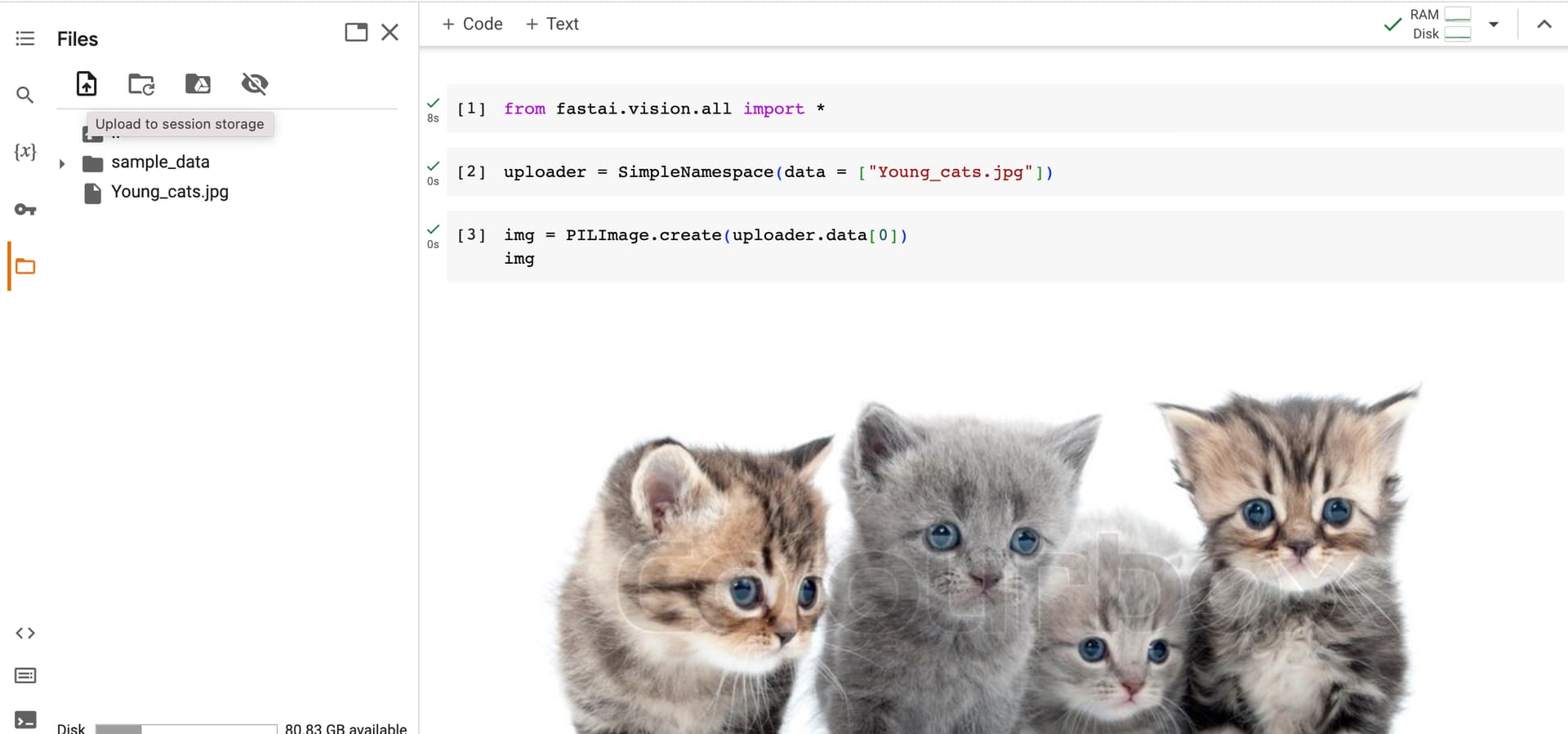
Alternatively, you can run the following code to connect to your Google Drive (it’ll ask you to sign-in to Google Drive):
from google.colab import drive
drive.mount('/content/gdrive')
And then you can access Google Drive files with the base path of "/content/gdrive/MyDrive":