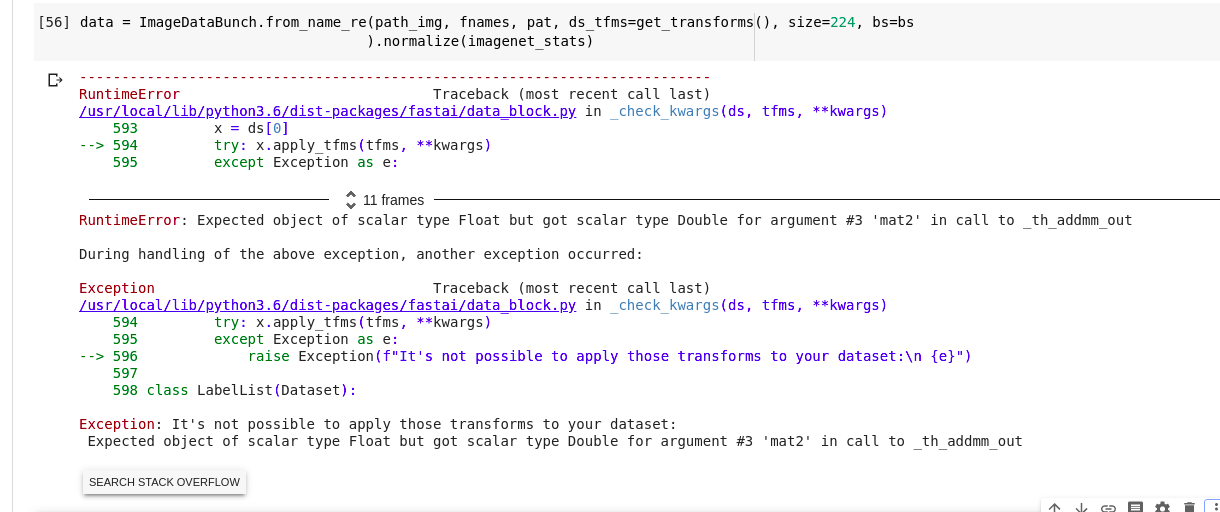
In first I’ve tried copy-paste approach. It wasn’t good enough, so I make bigger classes based on general birds titles and use stratification (so every class is presented either in train and validation dataset with given proportion), maybe ImageDataBunch do it itself, I don’t know. I’ve used my script for it.
Now I want to explore bounding_boxes.txt annotations for better classification. I cropped images with another script
I works perfect on my local tests.
But when I try look on my dataset with show_batch() I get this:
EDIT
The environment I was having these issues on was Gradient, still not sure why but tested out the notebook on kaggle and did not encounter any errors.
Original Post
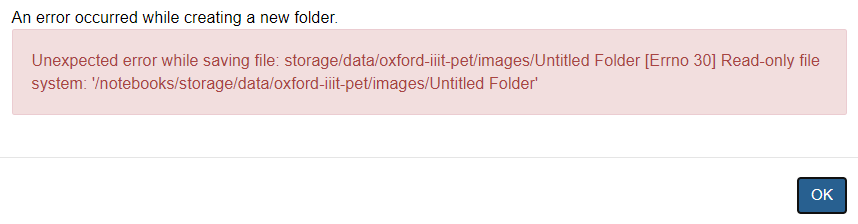
Can anyone guide me here, working my way through lesson one and have hit a road block at The Other Data Formats section.
Specifically getting this error message when I run the Image Data From Bunch command:
tfms = get_transforms(do_flip=False)
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=26)
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/data_block.py:537: UserWarning: You are labelling your items with CategoryList.
Your valid set contained the following unknown labels, the corresponding items have been discarded.
7
if getattr(ds, 'warn', False): warn(ds.warn)
Which leads (I think) to a whole bunch of errors later:
/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/basic_data.py:262:
UserWarning: There seems to be something wrong with your dataset, for example, in the first batch can't access these elements in self.train_ds: 9023,4005,7043,7988,5679...
warn(warn_msg)
How to check what features are the intermediate layers learning in a particular model? And how can we display it in the notebook by highligthing those features in the image?
Can anyone clear this doubt please?
When we downloaded the pets dataset, we had a separate folder for annotations. Then why did we use regex to get label names when instead, we could have got the names from the annotations folder? Please help me with this question.
Hi, I am new to fastai and deep learning. Can someone please help me understand the problem with using a different RegEx in ImageDataBunch.from_name_re.
I have set pat = r’(?:.)/(.).(?:.*)’
But using this re, I am getting the image annotations right. But data.classes is returning incorrect classes - e.g. Abyssinian_1, Abyssinian_2 are being returned as different classes
Please help me understand why pat = r’(?:.)/(.).(?:.)’ works but pat = r’(?:.)/(.).(?:.)’ doesn’t
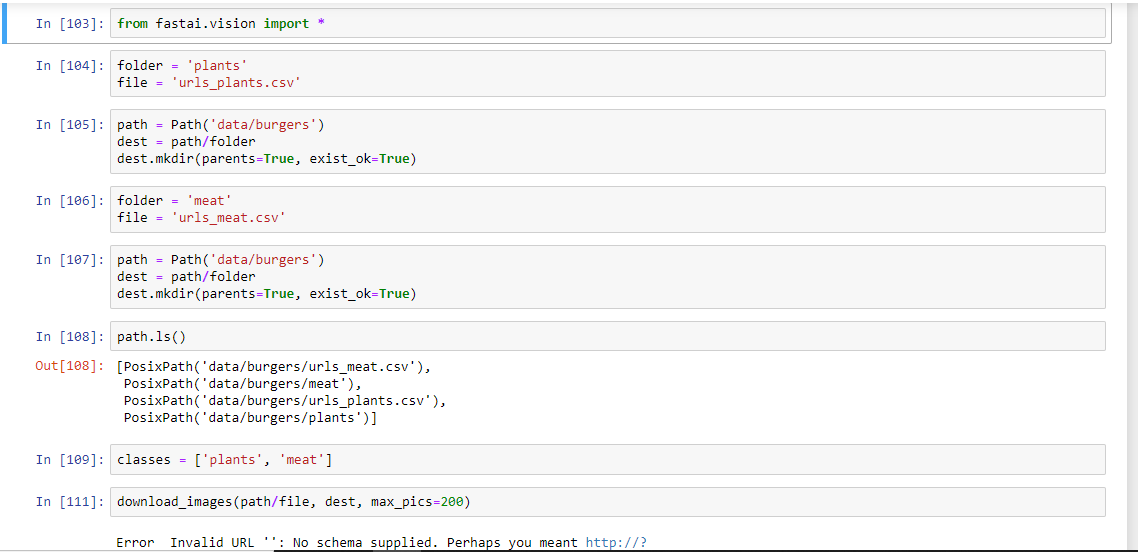
Hello everyone. I’ve just started trying to learn deep learning here on fast.ai and have been stuck at the very beginning (trying to create an image data set from google) for the past week now. This is my code, with the error I am receiving at the bottom ( and the error is repeated multiple times going further down the notebook).
I was told that my urls are google cache images for deleted websites, but I am using the same code to download the images (
urls=Array.from(document.querySelectorAll(’.rg_i’)).map(el=> el.hasAttribute(‘data-src’)?el.getAttribute(‘data-src’):el.getAttribute(‘data-iurl’));
window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(’\n’)));
) as shown in the official walkthrough. Even when filtering my search results to only show images from the last 24 hours, I get all urls with the same encryption. I am completely lost and stuck. Any help would be greatly appreciated. Thank you.
Actually, I think I may have figured out what my problem was. My max_pics was equal to 200 and I only have 80 images. Once I changed it to 80 I stopped receiving the error. I am posting this in case anybody runs into the same problem because I couldn’t find this solution anywhere.
In lesson2-download.ipynb it is said that you should not run the imageCleaner method in colab. I would like to let anyone who just started on lesson one that whatever issue was there when the notebook was made, it is no longer there. I run the imageCleaner on colab without any problem. you just need to remember to open another cell and run it maybe every 5 min so that your session does not timeout. for me I had a cell where I kept running a=5 at least every 5 min to keep the session a live.
For image classification of dogs and cats in Lesson 1, The filenames present in path_img folder is used to get the labels of the pictures. Then, that is the use of the path_anno folder? What type of annotation information is stored and used? Is it fine to ignore the path_anno folder if the labels are present in the path_img filenames?
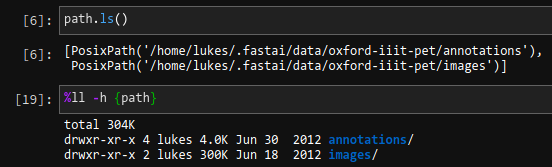
@jeremypath.ls() is convenient (as you point out) and discoverable, since it’s simply a method and comes up in tab completion. On the flip side, it builds muscle memory which will fail people whenever they encounter standard path objects or paths represented as strings.
In Jupyter/IPython, there’s an alternative which works with plain paths and strings alike: %ll {path}. It’s also fairly succinct IMHO, though definitely less discoverable, but it’s a good way to get used to variable interpolation in magics (or shell commands, !ls -l {path} works too of course)
I just started this course and just finished lesson 1. Then I wanted to do some practice using lesson 1’s code, but I encountered a little problem and hope I can get an answer here.
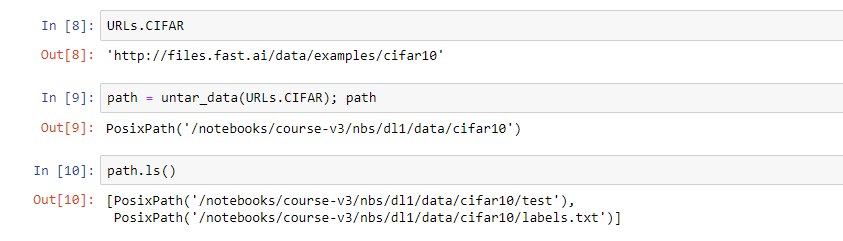
So basically I want to what Jeremy did in lesson 1 all over again, but on CIFAR 10 dataset. However, after I downloaded the CIFAR 10 dataset, it only has a test set and a label.txt. There is no training or validation set. I did some search in the forum and found that other people has a training set for CIFAR 10. I just want to know if this is by design and I need to partition the training set and validation set by myself, or there are some errors.