Hello Everyone,
I am working on a project and I want to bring it to production through an android app for it. I am thinking of deploying it through a app that would take a video from the camera and send real time data to a server. The server the would send back the output from machine learning model.
I don’t have any experience in app development and backend programming. I know a bit of java but it feels like I’ll have to learn whole android development for it.
It would be great if someone could share with me the resources where I could learn app development and sending and recieving data to server which would help me do just the task
I want to focus more on deep learning instead of app develoment
PS - This is my first post, so tell me if I have missed out on some detail or I should ask it on some other forum
Hi @shengrenhou,
I guess the problem here is path should be ‘/content/drive/…’ instead of ‘content/drive’.
I had the same problem one time, and this resolved the issue.
Also try check path.ls() to know if the directory is there and its sub-directories.
Hey I am just a beginner to this course and completed lesson 1. I completed my homework of MNIST_SAMPLE of 3 and 7with resnet34 and with freezing the existing layers I had accuracy of 90% and after unfreezing I got accuracy of 100% with just one wrong prediction . Just sharing my work with others. If anybody had better accuracy with freezing please share.
When I run, learn.fit_one_cycle(4) I get FileNotFoundError: [Errno 2] No such file or directory: '/notebooks/course-v3/nbs/dl1/data/oxford-102-flowers/jpg/image_06513.jpg'
Hi all, just went through the first lesson and I think I understand most of it but I’m a bit confused about why the learning rates were tweaked differently for the different layers. When Jeremy said something like “there’s no point training all the layers at that rate, because we know that the later layers worked just fine before when we were training much more quickly” - how do we know that they later layers worked fine and that the earlier layers needed a higher learning rate? Is it because the trained model ended up with a pretty small error rate or it that just a general rule of thumb?
It is called discriminative learning rates. You will know more about it after you finish all the 7 videos.
As you know, if you use a pre-trained model, the later layers recognize larger patterns or larger objects, such as eye balls or face. However, the earlier layers recognize simple patterns, such as edges or lines. Thus, the earlier layers are very useful for any tasks. On the other hand, the later layers are not that useful for all the tasks. For example, you don’t want to use layers that recognizes eye balls or human to recognize car shape. But we still want the earlier layers that detects cat edges to learn to detect car edges for a car identifier. Thus, we don’t want those earlier layers to have a higher learning rate. That is why you freeze the model with 1e-3 to train with higher learning in the later layers. After that you will unfreeze the model to train it with lower learning rate in the all model to avoid totally washing those earlier layers.
A higher learning rate means that the layer will change more. That is why you use a higher learning rate for later layers and lower learning rates for earlier layers. Again, you want to keep the earlier layers little bit and change the later layers a lot.
@bonnici
A higher learning rate means the weights for that layer are updated faster. A lower learning rate means the opposite.
So when we have a higher learning rate for the later layers we are training those layers faster as compared to the initial layers. This also means that the weights of the later layers are updated much faster and the weights of the initial layers are updated more slowly. As @JonathanSum mentioned, if the weights do not change much, the features (like lines, edges etc) detected by the earlier layers also do not change.
On the contrary, we want the later layers to learn at a faster rate (learn means to update the weights) so that instead of recognizing cars, it can recognize cats and dogs.
Therefore, Jeremy suggests that use the portion where the LR curve has the steepest descent (I think he mentions this in lesson 2). This way you start off by training the initial layers at a slower rate and then the learning rate becomes higher as we move to the later layers. It will become clearer as you watch more videos so don’t panic if you don’t understand it all now
This is just my option . Maybe swastik is right and I am wrong on “the features (like lines, edges etc) detected by the earlier layers also do not change.” You should come back here after finishing all the videos and answer this question.
**I think at the end you still need to use lower learning rate to update or train your earlier layers if “some tasks that you want to do”.**
Let me show you one thing and you will do the same thing in part 2.
The following 2 models are trained by Resnet50 with the same data, but they are not totally the same.
This is not improved version:
You can think of this Resnet50 has 4 blocks,except the first pooling block and the last linear block for finial classifier decision. Thus, we have 16 layers in 4 blocks.
You can see improved version can detect sky and even more small object or almost all the object. However, the not improved version can not really do that.
Block one: Layer 1 Layer 1-3, Block2: Layer 4-7, Block 3: Layer 8-13, and Block 4: Layer 14-16
@shengrenhou I would suggest to use kaggle to run your notebooks. It can get a bit overwhelming when - changing paths etc when used in gdrive. I faced the same issue and spent hours trying multiple things
running Learn.fit() on gdrive colab for 1 epoch takes 45 mins - this can be done on kaggle in 2-3 mins and it’s also free like colab. Must check out - kaggle in course.fast.ai links.
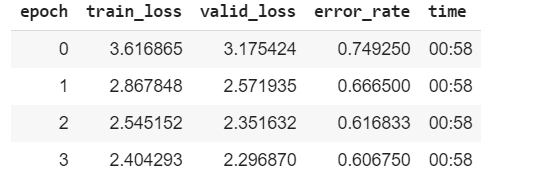
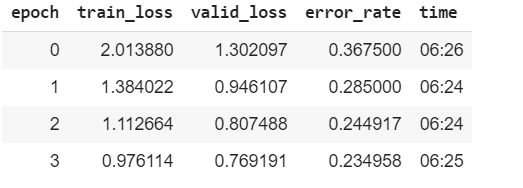
I am experimenting with the lesson 1 notebook using cifar100 dataset. But, I get very high error rate. I haven’t made any changes to the model code (using resnet34). Tried with 10 epochs as well but I still same result. Is this because this dataset is complex compared to the one used in class (100 classes) ?
In the first class, Howard says the following sentence: “In 2018, the best way to fit models is to use something called ‘fit_one_cycle’”. Is it still true now, in 2020?
Update: I identified some mistakes in creating data and fixed them. I wasn’t sending image size and batch size. I added those and the error rate now reduced to 0.23.



 ,
,