The model has already seen the data a several number of time (8 epochs).
The high learning rate causes even a minute error to be punished heavily leading to strong impacts on weight that inturn causes the model to loose all its stability and hence the high error value.
In case you have resolved the issue by the time you are seeing this, please let me know the reason for the same.
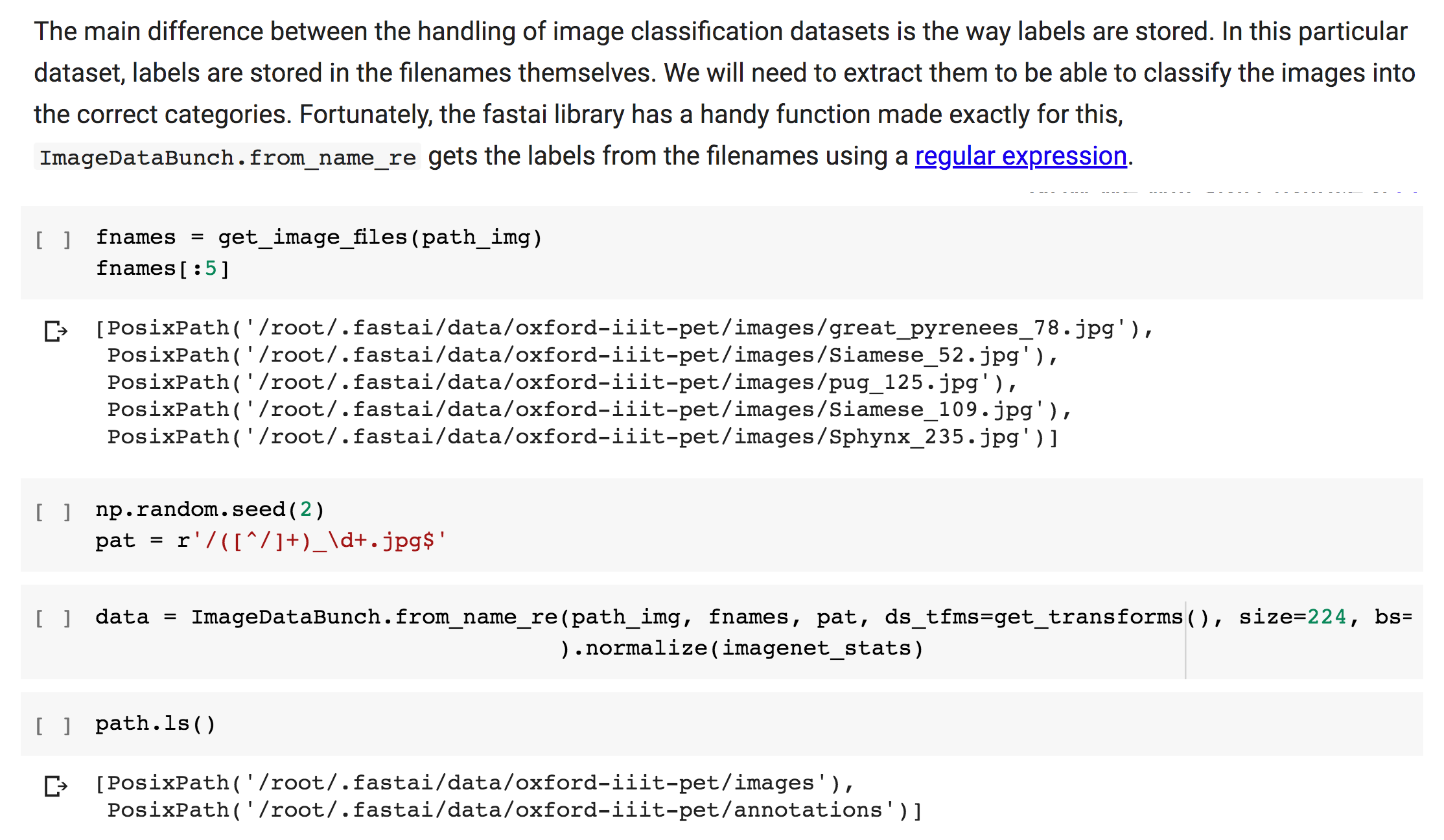
In lesson1-pets ipynb, we use two lines to import the modules/libraries:
from fastai.vision import *
from fastai.metrics import error_rate
and for the dataset we use the URLs class, and pass URLs.pets to untar_data.
Now URLs and untar_data() is defined under fastai.datasets. But we didn’t import anything from the datasets module. Then how come we are able to access the untar function and URLs class?
Why is the documentation of ClassificationInterpretation Class spread over two pages - https://docs.fast.ai/train and https://docs.fast.ai/vision.learner. When I use doc(ClassificationInterpretation), it directs me to the former link. However, I found some methods such as plot_top_losses() in the later link. Is there any specific reason for this segragation?
Hey All!
I’m getting ‘IndexError: no such group’ error when trying to use ‘ImageDataBunch.from_name_re’
My code is path_img = Path('/myDatasetNew/images'); path_img fnames = get_image_files(myDatasetNew); fnames[-5:] pat = re.compile(r'[^/myDatasetNew/images][a-zA-Z]+'); pat tfms = get_transforms(do_flip=False) data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=tfms, bs=bs ).normalize(imagenet_stats)
My file names are like
PosixPath(’/myDatasetNew/images/ valueiWant _ rose-165819__340.jpg’),
P.s. All the images have extension ‘.jpg’ I’ve made sure of it.
Hi, anyway to load image from CSV, I have a dataframe of shape 3000 x 784, where each rows of data is an image and the last column of dataframe is the label. Thank You
@sfsfsf, I suppose 3000 is the number of rows (images) and each image is 28x28 pixels encoded as 0 or 1, correct? There must be 785 columns then, one for label.
Yes Sir , you are right, the dimension suppose to be 3000 x 785.
I did read about the documentation and the only way I can think of is to convert the data frame into image in jpg format So that I can make the databunch object.
Just wondering if there any any ways to convert my data frame into databunch
Thank you very much, regarding the part of converting tensor into image, basically you will produce a bunch of images and store them in a folder ? May I know which function/library you are using?
Hi everyone, I’m really new to coding and am having a bit of a problem with my data for the first homework assignment of lesson 1. I’m trying to build a CNN that tells trees appart using images on google images. However, tree pictures have a lot of variance even with precise google searches, you get a lot of unwanted pictures such as distribution maps and essential oils that I would like to remove completely, but you can also get pictures of branches, leaves, bark or the full tree. From my understanding of CNN, putting birch leaves and bark in the same category will mislead the neural net during training and gives me an accuracy of about 50% over 30 classes. Like the neural networks but it’s not nearly accurate enough.
I was thinking of building an initial CNN for preprocessing the images into three to four categories while removing the “junk” and build a CNN for each category. I think I could get a higher accuracy while doing that.
First question: is it common practise in ML to build multiple neural nets on top of each other that will feed to another neural net depending on its result or should I do it with only a single neural net?
Second question: how do I use a neural net to partition a databunch into different databunch elements I can use to train their respective models for?
Third question: my first neural net will have to split the data into 4 classes W,X,Y,Z and detect those that are not(W,X,Y,Z), what kind of training set do i need for the “not” class?