Finished the assignment building my own dataset. In fact I used one of the resources from:
It really helps.
Finished the assignment building my own dataset. In fact I used one of the resources from:
It really helps.
Does anyone know how can I modify this regular expression to match the following format?
path_lbl = path/'labels'
path_img = path/'images'
get_y_fn = lambda x: path_lbl/f'{x.stem}_P{x.suffix}'
Example
images
case_00004_imaging_127.tif
case_00004_imaging_128.tif
case_00004_imaging_1290.tif
labels
case_00004_segmentation_127.tif
case_00004_segmentation_128.tif
case_00004_segmentation_1290.tif
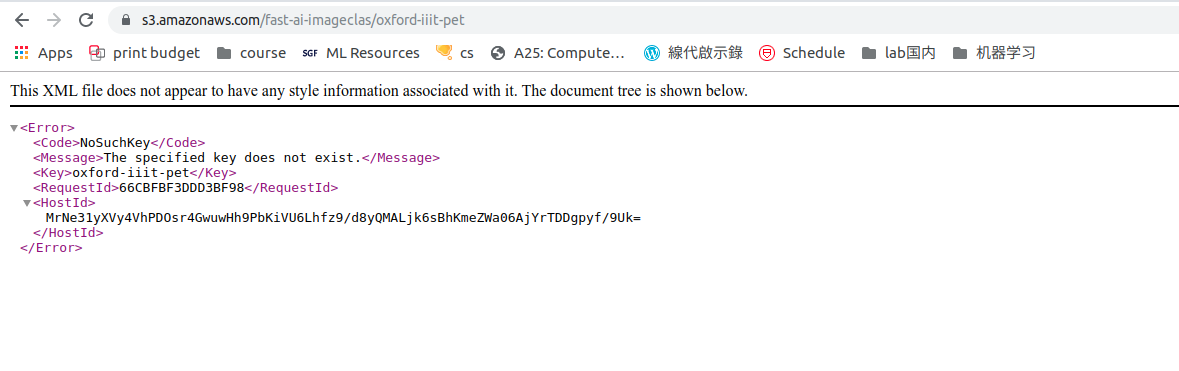
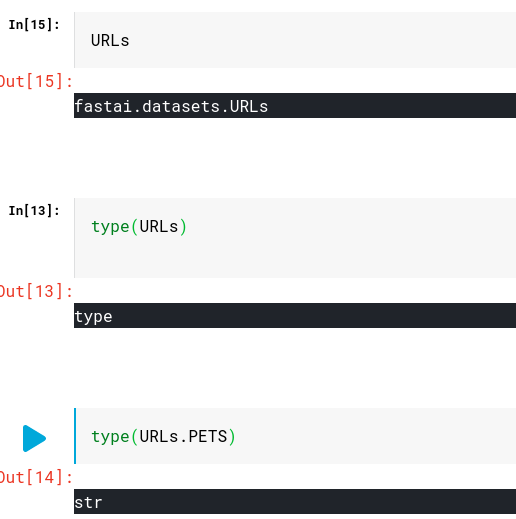
For the URLs.PETS, when I input the url to the chrome, this come out. Why not I download the data when I copy the URLs.PETS to the chrome? THANK YOU! I use linux system
Could you post the error message you get? And what’s the output of path?
The actual link you’re looking for needs to have the .tgz extension in order to download the data. This is the url you’re looking for https://s3.amazonaws.com/fast-ai-imageclas/oxford-iiit-pet.tgz
To see all the datasets that fastai uses, I found this handy: https://course.fast.ai/datasets
Thanks for your help!
I was able to figure it out. It was the path. Thank you.
Near the end of the lesson1, @jeremy you suggested that “we dont need to train all the layers at the same rate, since the later layers were working fine before at higher learning rate” Can you please be a little bit more elaborate about it and explain exactly what you mean?
Sorry if this seems silly, but i couldnt get that point
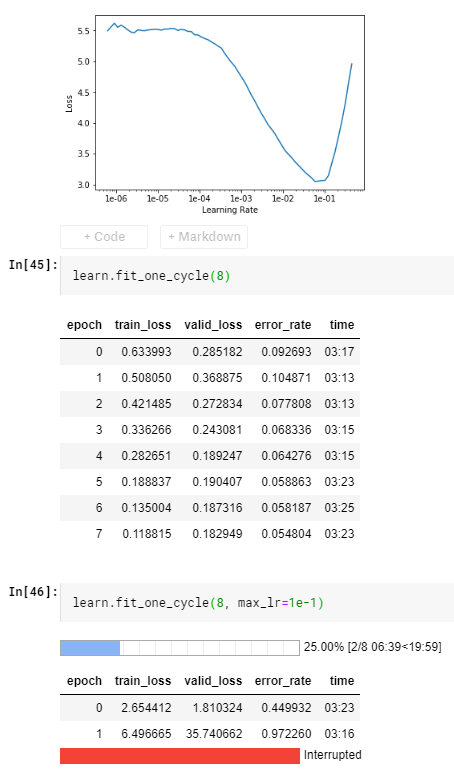
learning_rate = 1e-1 will give the min loss. Why I get such high error_rate training the model with max_lr = 1e-1, but a much better result with the default max_lr.
Simple question but it’s been driving me insane to try and figure it out.
How can I run the model on 1 specific image? Using colab, would like to be able to upload an image and see the results of the model.
This is actually covered in lesson 2. If you want to take a peek at the code, look at lesson 2 ‘Putting your model in Production’
While trying to interpret the losses in the lesson 1 notebook the following condition was checked:
len(data.valid_ds)==len(losses)==len(idxs)
Can someone explain what exactly the above code is trying to compare and why
Thanks 
hello!
I managed to train a few different models.
Some difficulties.
Some of the data sets seem to contain multiple versions of the labels.
This is really confusing. Sometimes there are 3 different files. do i combine all three into a single list for the ImageDataBunch?
Sometimes the imageDataBunch claims that it has train and validation images, but no testing images. you can see this if you just print the ImageDataBunch object to the terminal. The learner STILL RUNS.
Is this supposed to happen??
Sometimes the labels come in a .mat. I have learned this is a matlab file, that essentially can be unpacked into a python object in a few ways. But the noniterable arrays contained in that object are pretty confusing to extract the labels from. Personally i now hate the .mat files the most. XD
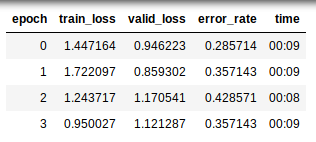
my error rate is increasing and decreasing.
can anyone tell me what is happening while training?
So, completely new to the course, so please make sure you independently verify if you can.
The values you are looking at are returned from the call to top_losses(). If you look at the documentation for that function (https://docs.fast.ai/train.html#Interpretation.top_losses), you see that it returns a tuple, in which the first element contains all losses (unless overridden), and the second element contains all indices. Put differently, if we look back at the code:
losses,idxs = interp.top_losses()
len(data.valid_ds)==len(losses)==len(idxs)
I think the only thing going on here is effectively an assertion that the lengths of the dataset, the corresponding losses, and indices thereof are all the same (which is why you hopefully see True).
Does that make sense and/or is at all helpful?
More than happy to chat further if the above is in any way unclear.
-Matt
I don’t quite understand why we make that assertion though.
How is the number of losses equal to the length of the validation data set?
Because, I think, there is a loss calculation associated with each element of the dataset. So, given that for each image, the network is “guessing” as to the outcome, there is a loss metric associated with each guess. If there were somehow images for which no loss was being calculated, I suspect that would be an anomaly.
But again, still very much a beginner, so please solicit a second opinion on all this.
-Matthew
Yes, it’s more or less to show (and check) that everything worked out as expected. We should get a loss for every item in our validation set, and each loss should also contain an index
can we change the URLs to something of our own dataset URL. I am getting error when i try to a different URL.