Thanks @barnacl the learning rate is indeed the problem. After training it over and over again a few times I found out that I should decrease the learning rate as I run to the higher epoch. A learning rate too high was causing the problem of the error rate to fluctuate up and down.
Fluctuating error-rate is caused by the learning rate being too high. I had the same problem. My key finding is that when you run learn.fit_one_cycle(), it uses a constant default learning rate throughout the 4 epochs. We may NOT want this, especially when your dataset is small. Generally, you want to decrease your learning rate as you go to the higher epoch, i.e., using a big learning rate for the 1st epoch, a smaller learning rate for the 2nd epoch, then so on. I did this and it worked perfectly.
2 Likes
I’m working through the oxford flowers 102 dataset as homework and I’m trying to map the numeric labels provided in train.txt (ie 0, 12, etc.) to indexes in an array I found online that has the text values of the labels (ie ‘hard-leaved pocket orchid’, ‘sweet pea’, etc), but I really have no idea how to do that. Any clues?
I’m creating my dataBunch as follows:
data = ImageDataBunch.from_csv(path, csv_labels='train.txt', delimiter=' ',header=None, size=299, bs=bs//2, ds_tfms=get_transforms(),
).normalize(imagenet_stats)
I’d modify the csv itself. So read it into pandas as a dataframe then replace via dict and now do a databunch from df
1 Like
I’ll give that a shot!
Or replace the labels in the text document! So long as it’s the same order I believe it should be okay 
Why does the frozen model output fluctuating and high error rate?
I tried different number of cycles, it still get similar outputs. Did I choose wrong max_lr parameter?
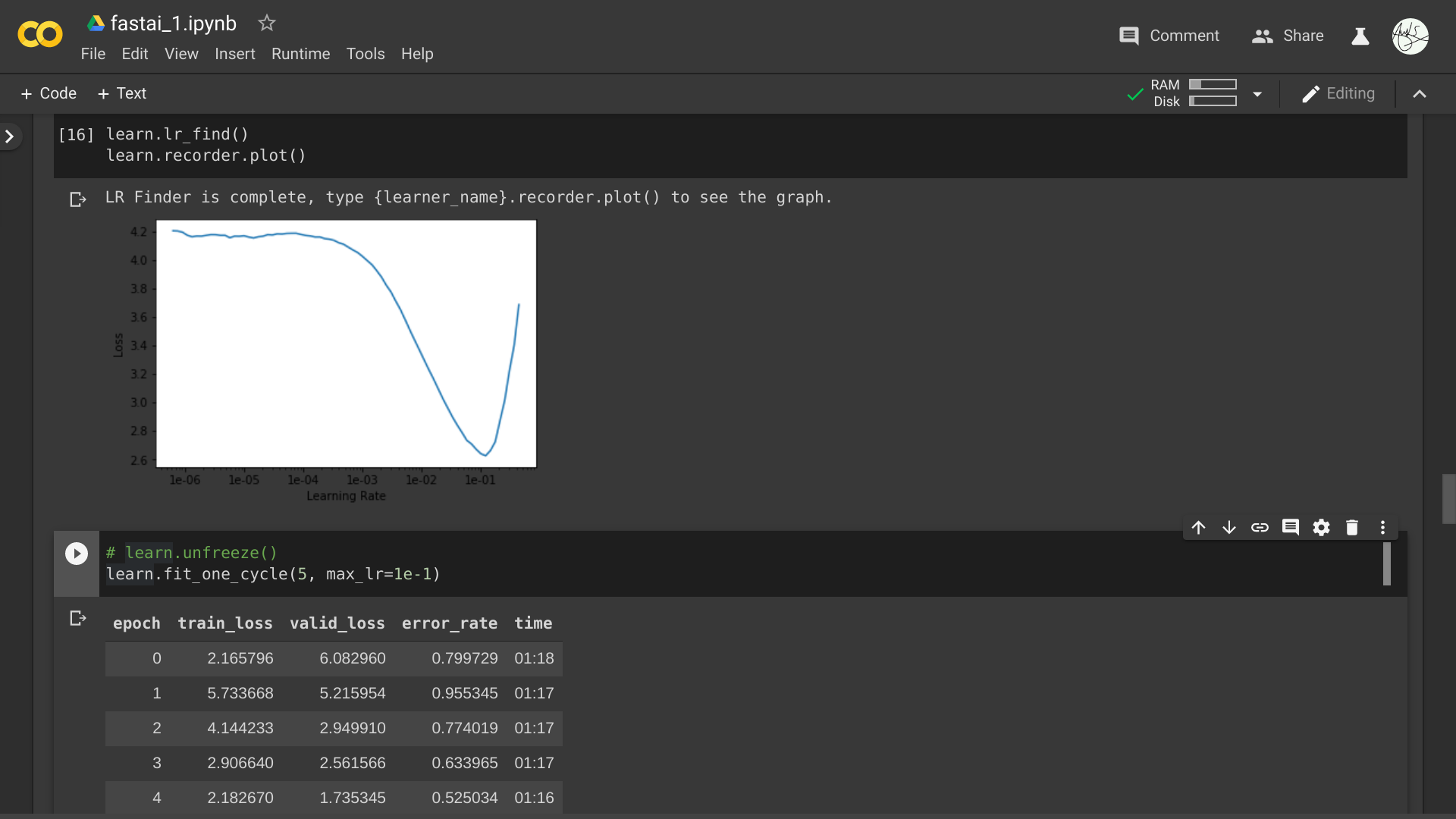
Hey @AnkS,
So for this type of clean LR curve, you’d want to pick the LR with the biggest downward slope. The reasoning is the following:
- Using the one-cycle scheduler, the LR is going to evolve with the number of steps. Thus you want to pay attention to the sensitivity of loss (and accuracy) to LR. And the closest candidate for this would be the gradient of the loss relatively to LR.
- In your example, picking the LR with the lowest loss value, since it’s a local (and here apparently global) minimum, the above-mentioned gradient will be zero.
- The LR finder only evaluates the changes in LR for a few iterations. But after several epochs, the curve will significantly change.
For a good analogy, I always picture climbing down a mountain 
Loss would be the altitude, your weights would be your GPS coordinates (latitude & longitude only), LR your speed (or step size if you consider a constant duration for each step), and iterations/epochs would be a measure of the number of steps you take. Your directions are estimated by the variations of the altitude (meaning it won’t adapt later to your speed but only to your location)
In this context,
- one-cycle policy: you will progressively accelerate to a top speed of your choice (that you will reach in a given number of steps), then decelerate.
- what you selected: picking the LR with lowest loss is equivalent to picking your maximum speed/step size based on the fact that there is a point very close to you with lower altitude.
- what is suggested: picking the LR range with biggest downward slope is equivalent to picking your maximum speed/step size on the fact that for neighbouring step sizes, you are still on the biggest slope around.
And global minimum being the bottom of the mountain, you’d want to follow downward-oriented path rather than close puddles
For wider range selection and finetuning, the general rule of thumb is mentioned by Jeremy during the lesson, I can only suggest to watch it a couple of times, you always get more out of it!
Obviously, for more details, you can refer to Leslie Smith paper.
Hope this helps, cheers!
1 Like
I have started lesson 1 and I have already downloaded the pets dataset , but how to initialize the path variable so that I can do further task,
I am doing like this
path=PosixPath(‘D:\datasets\oxford-iiit-pet’)
but getting the error??
Hi, Sorry if this is the wrong place to ask this question!
So I am currently trying to get through the very first lesson. Things are working fine except I have difficulty downloading the MNIST_SAMPLE data set.
For the below command
path = untar_data(URLs.MNIST_SAMPLE); path
I am getting a timeout error.
However I can see the file in the browser and download them manually using wget.
Please correct me if I am doing something wrong !
Hi avrachan,
Where are you running this code/notebook?
Thanks
Mainak
Hi!
I have done lesson 1. Then tried out with CIFAR-10 and FLOWERS dataset. I am getting high error rates in both these cases with both resnet34 and resnet50. What I am missing / doing wrong?
Thanks
Mainak
Issue solved I used
from pathlib import Path
p=Path(‘D:\datasets\oxford-iiit-pet’)
p
WindowsPath('D:/datasets/oxford-iiit-pet')
Hi mainak,
Thanks for replying. I’m running these on a workstation which I access remotely, may I know how this matters? I can download MNIST_TINY and it works fine ( I can continue the lesson).
-avrachan
Thank you! That helped fixed my problem as well.
I am doing on windows 10 64 bit 8gb ram
pytorch 1.0.0
fastai ‘1.0.34’
from fastai import *
from fastai.vision import *
from pathlib import Path
p=Path('D:\datasets\oxford-iiit-pet')
p_anno=p/'annotations'
p_image=p/'images'
fnames=get_image_files(p_image)
np.random.seed(2)
pat = re.compile(r'([^\\]+)_\d+.jpg$')
data=ImageDataBunch.from_name_re(p_image,fnames,pat=pat,ds_tfms=get_transforms(),size=224)
data.normalize(imagenet_stats)
data.show_batch(rows=3, figsize=(7,6))
getting the error
PicklingError Traceback (most recent call last)
<ipython-input-9-66824b983385> in <module>
----> 1 data.show_batch(rows=3, figsize=(7,6))
.
.
.
PicklingError: Can't pickle <function crop_pad at 0x000002006872B840>: it's not the same object as fastai.vision.transform.crop_pad
There are two ways in which losses can be calculated as per lesson 1 of deep learning.
First way:
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
Second way:
preds,y,losses = learn.get_preds(with_loss=True)
interp = ClassificationInterpretation(learn, preds, y, losses)
What is the difference between the two?
Although the regular expresssion used in the course video works to serve our purpose, I beleive techinically it should have been ‘/([^/]+)_\d+.jpg’
Hi there, 1st time to be here.
I just wonder how to post a question on this forum?
Thanks
My first try with RestNet-34 and ResNet-50 - classifying surfboards from skateboards (with 95% accuracy). Please take a look and feel free to leave a comment.
1 Like