I fork codes from https://www.kaggle.com/hortonhearsafoo/fast-ai-v3-lesson-1. I run the codes in kaggle kernel, then i get the following error. How can i fix it?

Works fine for me. Your internet should be turned on for this. Check that in the “Settings” of the Kernel
After I turn on the internet, and restart kernel, it works well. Thanks
Hi, i just completed the first lesson and created my image classification model. It consists of 4 classes, which are German auto brands (vw, bmw, mercedes, audi). Every of them has about 500 images. I followed the instruction from course. It was a great start. But the accuracy of the classifier seems a little bit lower. (about 75%). And it was kind of overfitting. I share the Colab Notebook (https://colab.research.google.com/drive/1OLfyLBRPU44SwYhkP7JX3YQ0S1TXCm5U)
if anyone of you is interested to give some advice to improve performance. I will be very appreciated that.
2 Likes
how to delete a class of data if it is redundant
1 Like
Hi guys how to delete a class of data in our model
Hello,
I am beginning to create my model and ran into an issue in the first line:
When running:
%reload_ext autoreloadEn
%autoreload 2
%matplotlib inline
I get the error:
ModuleNotFoundError Traceback (most recent call last)
in
----> 1 get_ipython().run_line_magic(‘reload_ext’, ‘autoreloadEn’)
2 get_ipython().run_line_magic(‘autoreload’, ‘2’)
3 get_ipython().run_line_magic(‘matplotlib’, ‘inline’)
…
When going back to lesson1, the same code throws the same error. I do not understand why it was working yesterday but not today. Can someone please offer any advice?
Thanks!
1 Like
Hey, so the most important step for creating a new image dataset is consistency. You should “clean” your dataset by deleting images like this one that I just randomly found while clicking through your images.

This isn’t the only bad picture; I see dozens of photos that do not belong.
This particular image, as well as many others in your image set, should be deleted since it’s sort of one-of-a-kind: this image shares very few features to other images in your data set.
The algorithm needs many examples of each class, where each example has something in common with other images in that class’s dataset. There are two ways to do this: train using thousands of images per class, or train using hundreds of images where each image is somewhat similar to the rest of the images.
So, how do you fix your dataset? Start by deleting:
- close-up images where the whole car is not visible
- pictures of the interior of cars
- images that contain people in the foreground
- (people will “distract” the algorithm from the actual car!)
- images that contain only a logo, symbol, or drawing
- images that contain multiple cars, especially if there are multiple types of cars!
- images of cars that are unique from any other in the world, like this one, which is being disguised with a one-of-a-kind paint job specifically designed to make it difficult to tell what kind of car it is:

In the end, you could get away with using about 200 images in each class as long as the images are somewhat similar, which you can do accomplish by removing the outliers that I mentioned above.
Finally, here is what I believe is an example of a perfect training image that you have in your data set:

- Notice that the entire vehicle is visible, there are no objects in the foreground that distract from the subject, and the car is not a one-of-a-kind prototype.
Source: I achieved 88% accuracy using ResNet50, 12 classes of car brands, and 200 images per class.
1 Like
Hi, thank you for your concrete explanation. I will clean up my dataste and give another try. I will share my updated result with you.
Many thanks.
Hello everyone, I am doing the homework for lesson 1. I collect the images of three classes: tennis, golf, and table tennis. I currently have some problems that I wish someone could help.
- Looking at the confusion matrix, I don’t know why there is a confusion as in the red box indicated below. It is a correct prediction. Do you why a correct prediction is in the confusion matrix?

- In the fine-tuning step of training Resnet34, I see that the training loss and validation loss are monotonically decreasing. However, why is the error rate go down and then up again?

- Same question with 2. but now both the validation loss and the error rate fluctuate when I train Resnet50. Do you know why it happens?
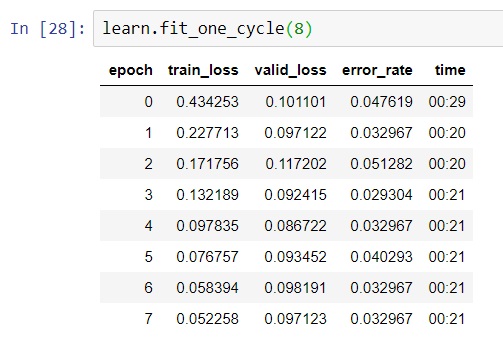
Thank you guys very much.
Hi @minh, for (Q.1.) i remember @Jeremy said in the lectures that if your error rates go up and down too often, that could be a sign of over-fitting.
Also provided your validation loss is always lower than your training loss… you’re fine.
1 Like
1)From interp.plot it looks like your predictions and actuals don’t match up. At the top of each image you have the “predicted label/actual label/loss/probability” . So for image 1 the model is predicting golf but the actual label is tennis. I think you are mistaking the heat maps with predictions.
While reading a confusion matrix what you want is the diagonal values to be large.
For 2 & 3 try reducing your learning rate and training it again and let us know if that helps.
Key thing to remember is that if your model goes of the rails at any point you want to recreate your learner and start training don’t continue training with that learner.
In the function open_image we call pil2tensor which is defined as:
def pil2tensor(image:Union[NPImage,NPArray],dtype:np.dtype)->TensorImage:
"Convert PIL style `image` array to torch style image tensor."
a = np.asarray(image)
if a.ndim==2 : a = np.expand_dims(a,2)
a = np.transpose(a, (1, 0, 2))
a = np.transpose(a, (2, 1, 0))
return torch.from_numpy(a.astype(dtype, copy=False) )
is there a reason why these lines:
a = np.transpose(a, (1, 0, 2))
a = np.transpose(a, (2, 1, 0))
can’t be combined as:
a = np.transpose(a, (2, 0, 1)).
Is this some optimization?
Hi.
I’m running the sample code on a Linux server via Jupyter notebook.
On running this line path = untar_data(URLs.PETS); path, I get the following error:
ConnectTimeout: HTTPSConnectionPool(host=‘s3.amazonaws.com’, port=443): Max retries exceeded with url: /fast-ai-imageclas/oxford-iiit-pet.tgz (Caused by ConnectTimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at 0x7ff18a83eed0>, ‘Connection to s3.amazonaws.com timed out. (connect timeout=4)’))
However, when I run this code, everything is fine
from urllib.request import urlopen
url = ‘https://www.google.com/’
resp = urlopen(url)
code = resp.getcode()
print(‘the result is :’, code)
the output is 200.
Can anyone help me to solve this problem? Thank you.
Hi, first post here hope not to mess it up.
After doing the class I tried remaking that cricket or baseball guesser. It works but decently but the outputs of the training functions are not being that helpful because they seem to be missing values:

The plot to find the learning rate was a bit crazy too but at least I could point to 1e-02

And then again retraining:

Is this because of not using many images? I used 25 images for training and 5 for validation. Batch-size was set to 16 but I still have to see how that affects stuff.
Without getting the error-rate can I actually make anything work besides blindly trusting the “system”?
Not sure if there’s more stuff I can post to give more context if so tell me!
Thank you very much in advance for any answer, hope to be able to contribute to this community in the near future!
Thanks @hammao and @barnacl for your help. One strange thing I notice is that each time I recreate the learner and run fit_one_cycle() again, I got different error_rate every time. Do you know why is it happen? If the data is the same and we recreate the learner, shouldn’t we get the same training error, the same validation error, and the same error rate every time?
did you try reducing your lr and running it?
how many images do you have? may be try reducing your bs (batch size). Something seems unstable to me, not sure may be i’m wrong. But please do report back after trying these two things if you can 
With bs=16 and a total of 25 images gives you less than two batches. Try reducing your batch size
1 Like
Thanks for the answer. I tried reducing to 8,4 and 2 and still get the same #na#.
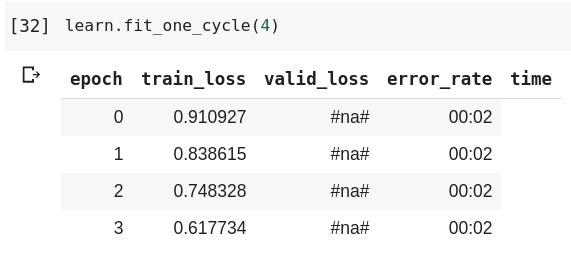
I made a little tool to build datasets I will see if the works with around 100 pics.
EDIT: It wasn’t working either with sets of around 70-80imgs / category so I checked the data.

I guessed my validation set was not being recognized, went to check the documentation for ImageDataBunch.from_folder , turns out I had a typo in the “valid” folder.
Thank you for your help! I’ll pay more attention next time. Here’s the working one!

Thanks again!
In another question.
Are the values of error-rate supposed to fluctuate when you run the learn.fit_one_cycle(4) without changing anything else? Or is this a sign of something not so right?
Everytime I rerun the notebook I get different error_rate and lr plots. Sometimes the error_rate even repeat themselves between epochs.