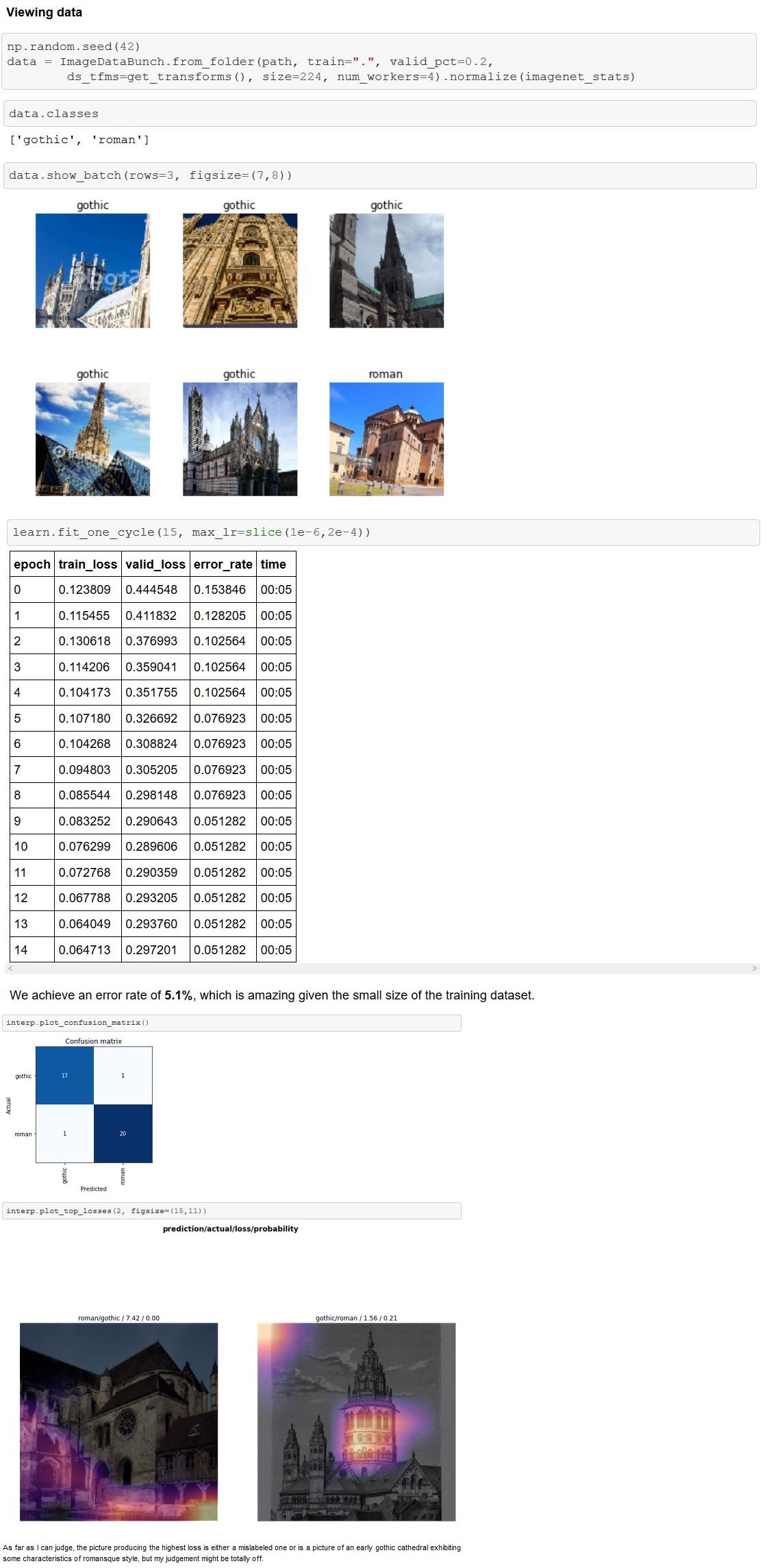
Based on what is taught in Lesson 1, I trained a resnet50 model to classify pictures of romanesque cathedrals vs. gothic cathedrals. I achieved an error rate of 5.1%. My notebook along with the textfiles containing the urls of the images I used for training and validation can be found here: https://github.com/g-vk/fastai-course-v3
Great job @gvolovskiy…I have a doubt…following the notebook lesson, I understood that the learning rate must be found before the unfreeze step. Something like that:
learn.load(‘stage-1’)
learn.lr_find()
learn.recorder.plot()
learn.unfreeze()
Pls let me know!
Before unfeezing, the set of trainable parameters is the same as when training the head of the model. Since after loading the stage-1 weights the weights of the head of the model are already trained, there is no need to train them again and hence also to look for a good learning rate. It is only after we enlarge the set of trainable parameters by invoking learn.unfreeze() that looking for a suitable learning rate becomes necessary.
I hope my explanaion was helpful for you.
For what it’s worth, you might consider switching from GCP to Salamander simply because Salamander appears to be operated by the same people who operate FastAI. Either that or it’s very closely integrated; point being that setting up FastAI with Salamander is quite easy.
Are you referring to the colored blobs that appear on each image? Those are called heatmaps and they are supposed to show you which portion of the image the neural net is “most interested” in, so to speak.
I just finished watching the Lesson 1 and I think I’ve understood the concepts well. Also, got the same working on my notebook. My question is - If I want to take one image specifically of my own and test what the output of the classifier would be, how do I go about it?
Hello @gluttony47 I’m late to your post. I just wanted to say that I also picked GCP and it is a difficult thing to get installed imo. You have to keep playing with it. It took me a few days to get it to work. I was all over the forums & the GCP help pages too.