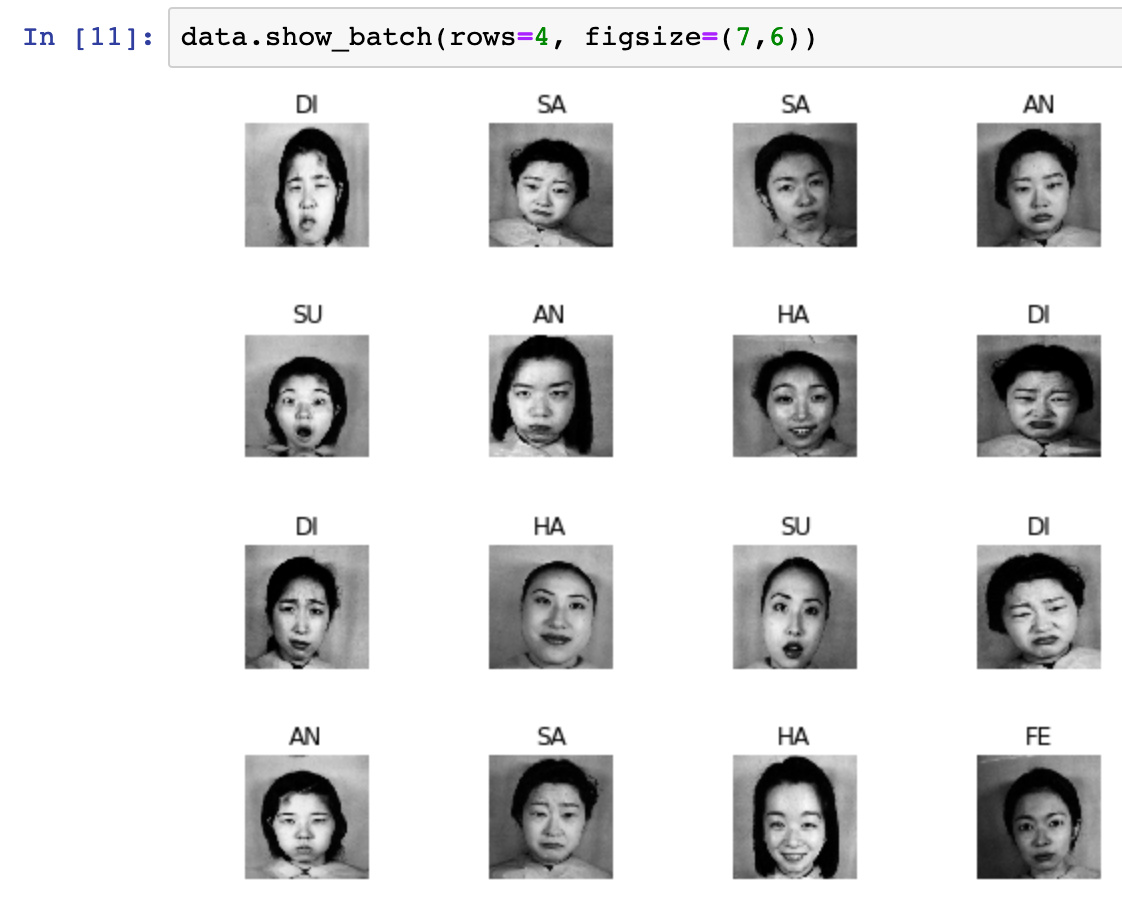
For lesson 1 homework, besides running a copy of the lesson notebook myself, I tried on my own dataset, largely mimicking the process in lesson2-download.ipynb, which was a lifesaver.
First, I downloaded three sets of images from google images for dog-like things: huskies, malamutes, and wolves.
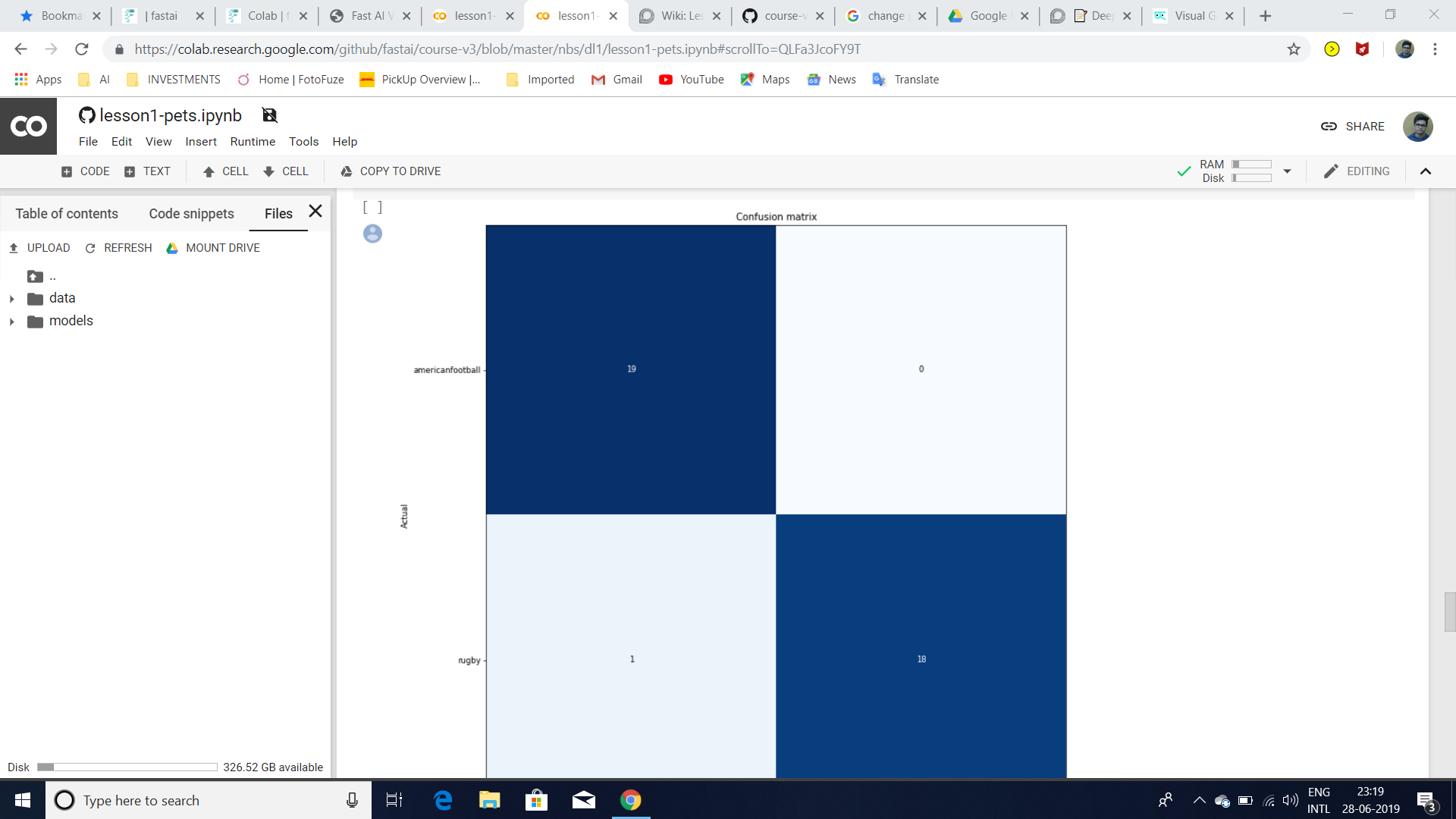
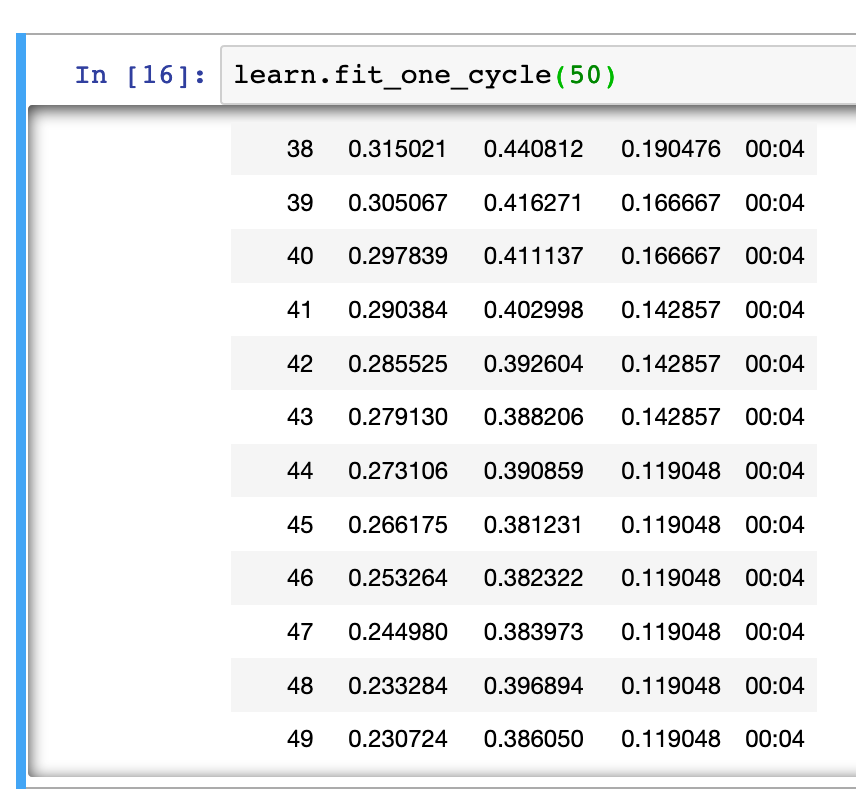
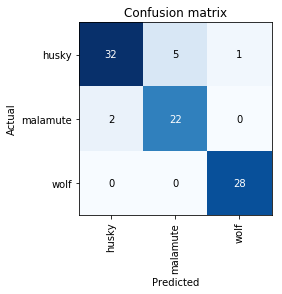
On initially creating a cnn_learner with a resnet34 based model, and using fit_one_cycle with 4 epochs, I got to a validation error rate of 8.9% (8 out of 90 in a validation set), with the below confusion matrix, which made sense to me since to my eyes wolves look pretty distinct but malamutes seem like slightly poofier versions of huskies (and i wouldn’t be surprised if there was miscategorization in my google image search).
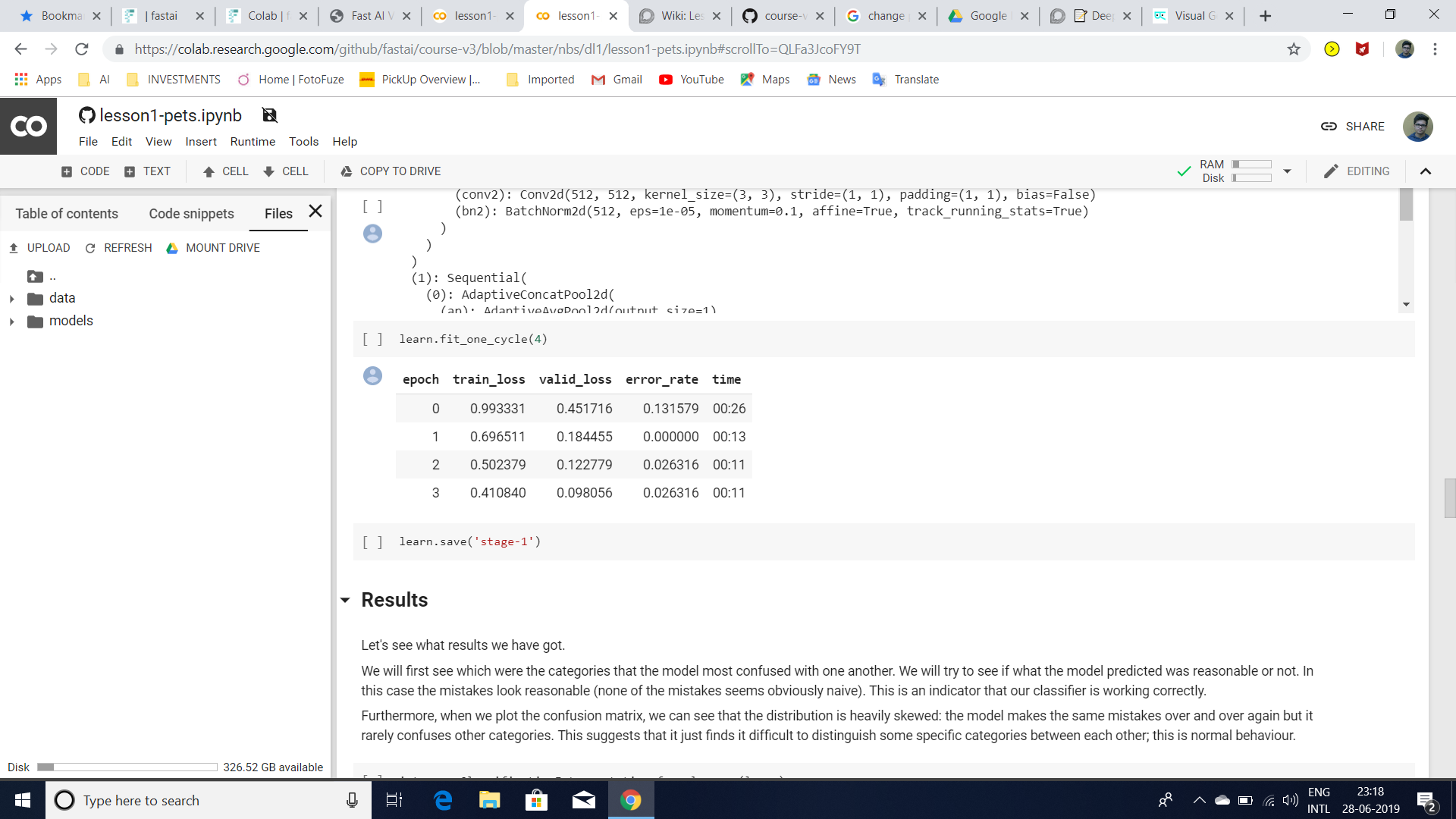
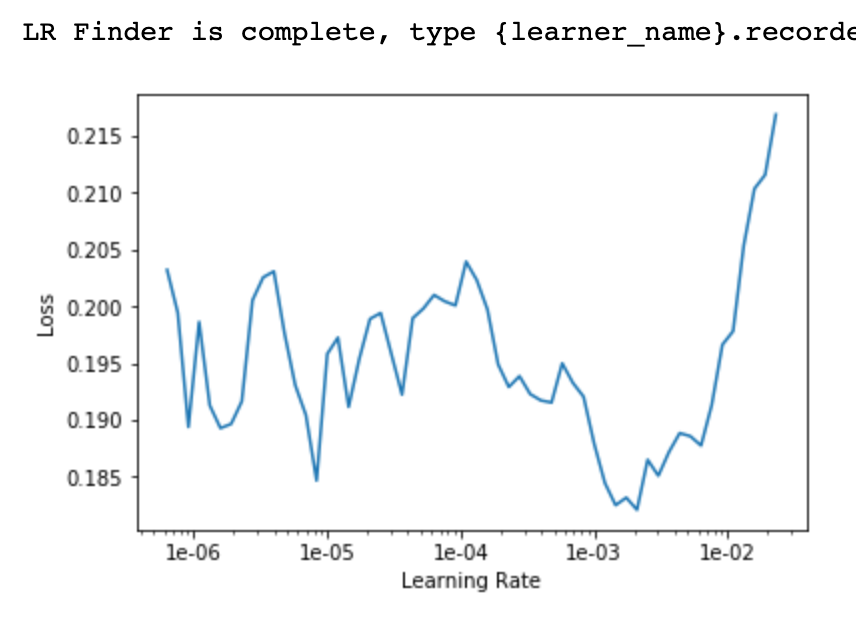
When i went to unfreeze and re-applied fit_one_cycle over 4 epochs with a learning rate from the lr plot before the loss started to skyrocket, the error rate got a bit worse (12%), but the confusion matrix was qualitatively similar.

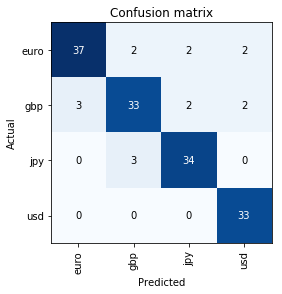
This seemed pretty good, so I tried another hack using images from google images of paper currency from: (1) Euro, (2) USD, (3) Japanese Yen and (4) UK pound. Google image search produced a few dozen “good” images of the paper currency and then below the fold started showing less ideal results with things like coins a few clip art, etc. Applying the same general process, learning 4 epochs, initially produced a 14% error rate. Then unfreezing, and doing 3 more epochs got me to this confusion matrix (10.5% error rate).
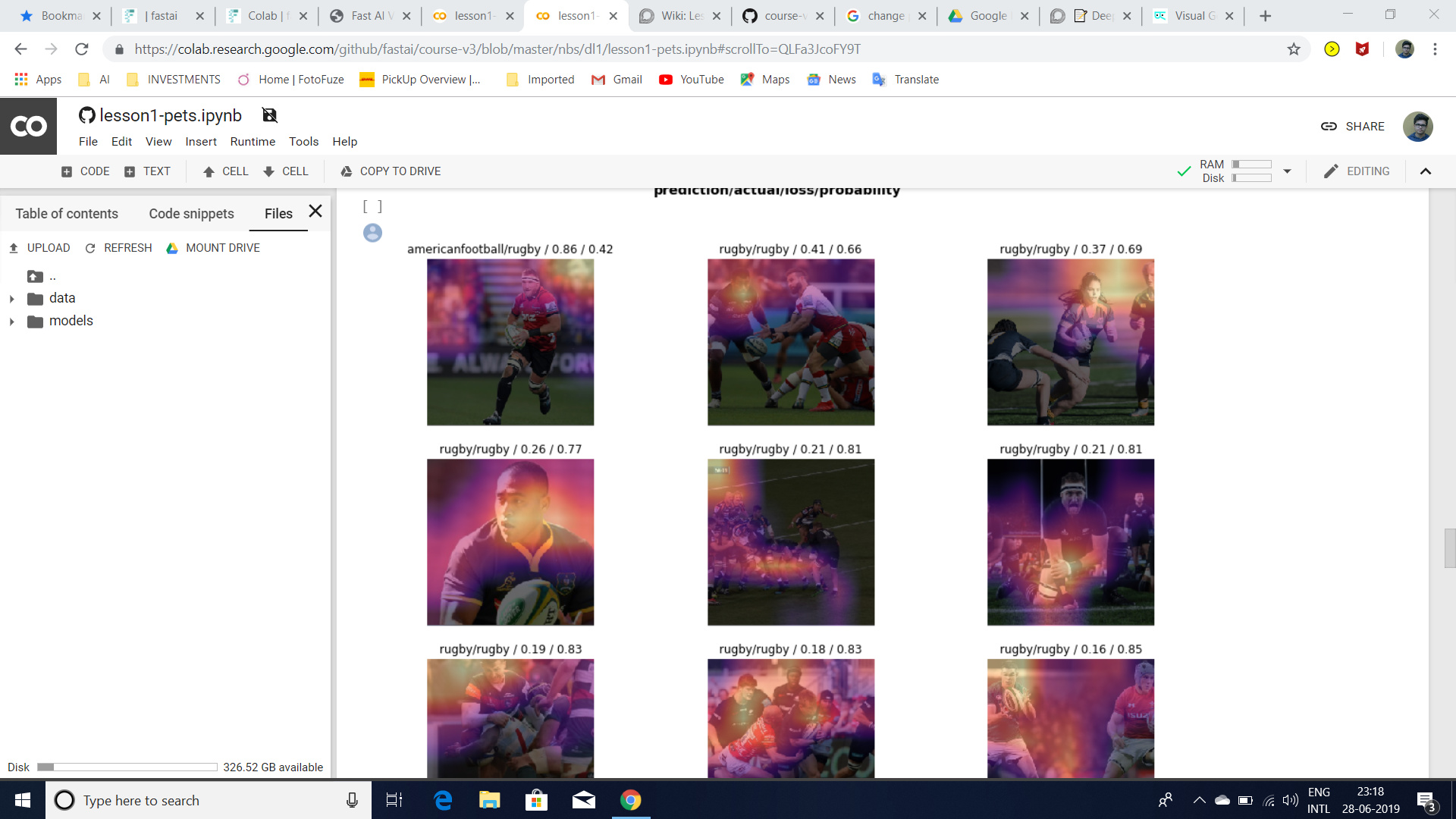
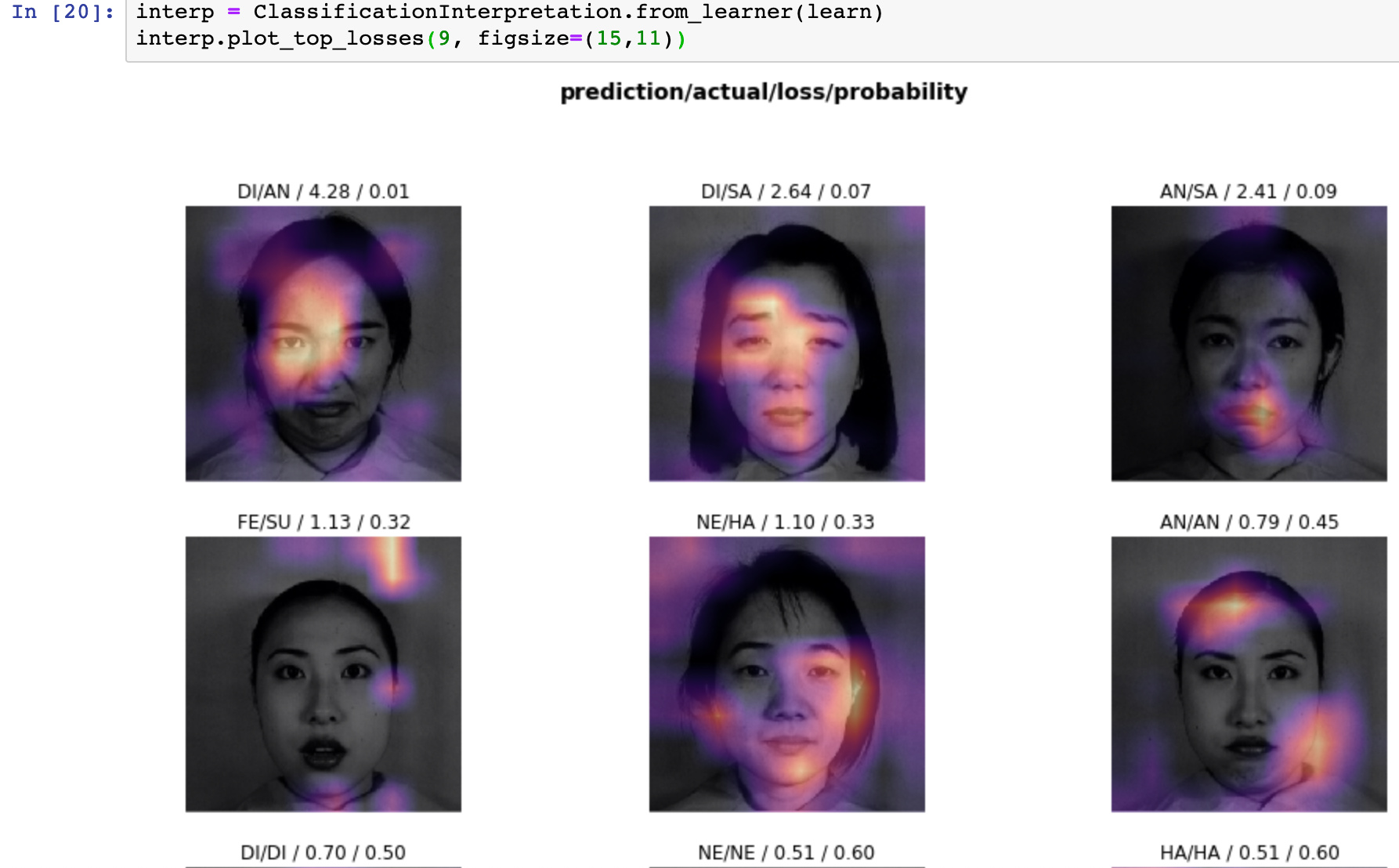
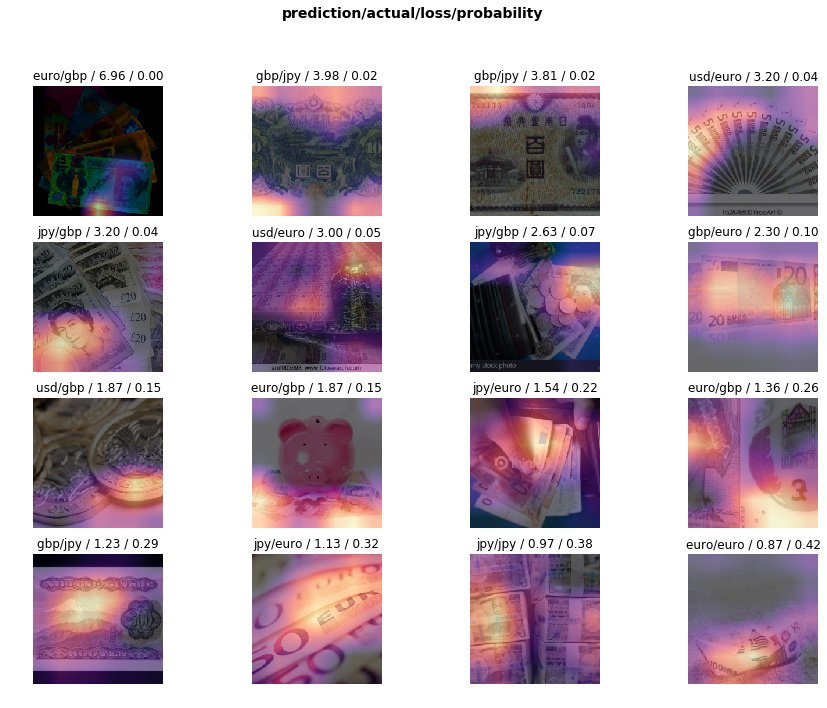
Looking at top losses, a few of them were perhaps explainable as being the wrong type of pictures (only coins for instance), although a few of these misclassifications are a bit disappointing. Its hard to tell visually what features the model is focusing on but is tripping over…perhaps there were patterns in the way the bills were arrange in the pictures, which overshadowed the features of the notes themselves in a dataset of 600 images.
Anyway, this seems to be pretty good for a first hack at things. Do others think it makes sense to move on to Lesson 2 at this point?
Thanks


 Deep Learning Lesson 1 Notes
Deep Learning Lesson 1 Notes