Thanks Aaron!
A community makes everything better!
In regards to changes to the git repo, I believe that’s managed by Jeremy and Rachel.
For me, I had to make a manual edits to resolve a couple of errors I encountered running my Lesson 1 notebook on my AWS instance. Here is a summary of the edits I made:
2nd Code Cell:
from fastai import *
from fastai.vision import *
#from fastai.metrics import error_rate
9th Code Cell:
np.random.seed(2)
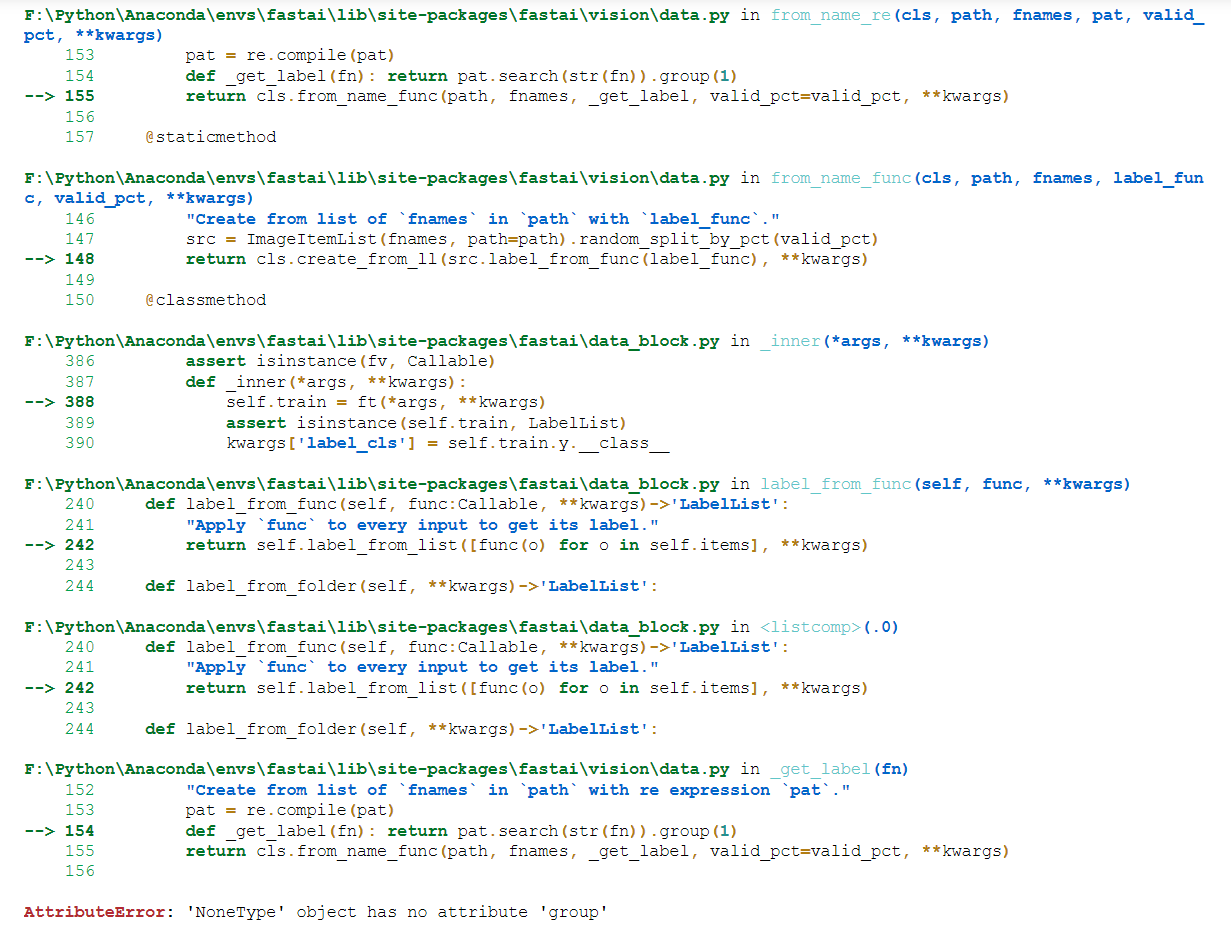
#pat = re.compile(r’/([^/]+)\d+.jpg$’)
pat = r’/([^/]+)\d+.jpg$’
10th Code Cell:
#data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs
).normalize(imagenet_stats)
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs, padding_mode=‘zeros’)
data.normalize(imagenet_stats)
C?? - Resnet50 Code Cell:
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(),
size=299, bs=bs//2, padding_mode=‘zeros’).normalize(imagenet_stats)
I figure with so many different platforms, OS versions, library versions, etc. there is always going to be the odd tweak required here or there. I’ve found most of the errors are easily resolved by Googling the error message and/or searching this forum.
Happy coding!
 Notebook on kyso ->
Notebook on kyso -> 