I am in mobile right now, but I guess it is https://github.com/sgugger/Deep-Learning/blob/master/Understanding%20the%20new%20fastai%20API%20for%20scheduling%20training.ipynb
2 Likes
I’m trying to build a model for the stanford cars dataset. This dataset has 196 classes
I have used both resnet34 and resnet50 but the lowest error rate i could get was 0.2.
I am now using resnet101. Before unfreezing, the error rate was 0.166 after initially starting off at 0.7. This was the plot for lr_find()
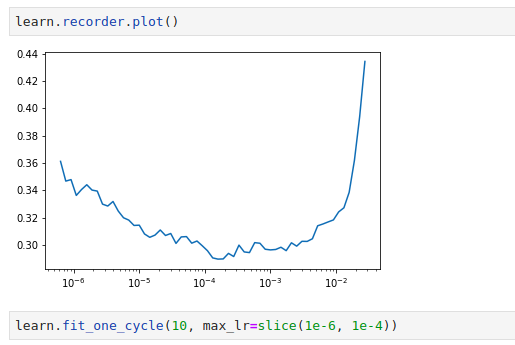
I choose the range of 1e-6 to 1e-4 for the fine tuning but the error rate is not reducing as i expect. After 10 epochs the error rate is 0.147.
Is it because I didn’t choose the right learning rate or because the problem is just difficult considering that it has 196 classes
1 Like
I am getting error message “ImportError: No module named ‘fastai’” when run through jupyter notebook
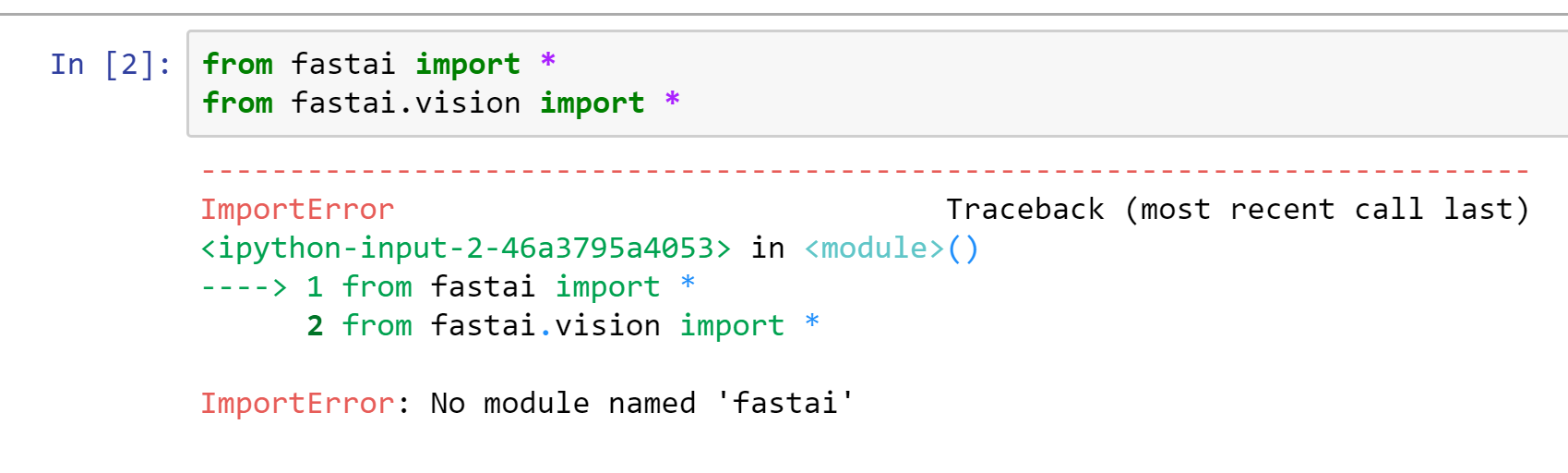
When run in command line - it works fine
Performed following steps
conda install -c pytorch pytorch-nightly cuda92
conda install -c fastai torchvision-nightly
conda install -c fastai fastai
conda uninstall fastai
git clone https://github.com/fastai/fastai
cd fastai
tools/run-after-git-clone
pip install -e .[dev]
jupyter notebook
took me awhile to find them too! I am using GCP (just for reference).
$ find . -name *.pth -print
./.fastai/data/oxford-iiit-pet/images/models/tmp.pth
./.fastai/data/oxford-iiit-pet/images/models/stage-2.pth
./.fastai/data/oxford-iiit-pet/images/models/stage-1.pth
Perhaps your notebook is not run on the same kernel as the one you ran in the CLI?
You are right. Same kernel is not available in jupyter notebook. (python default env is missing in jupyter notebook)
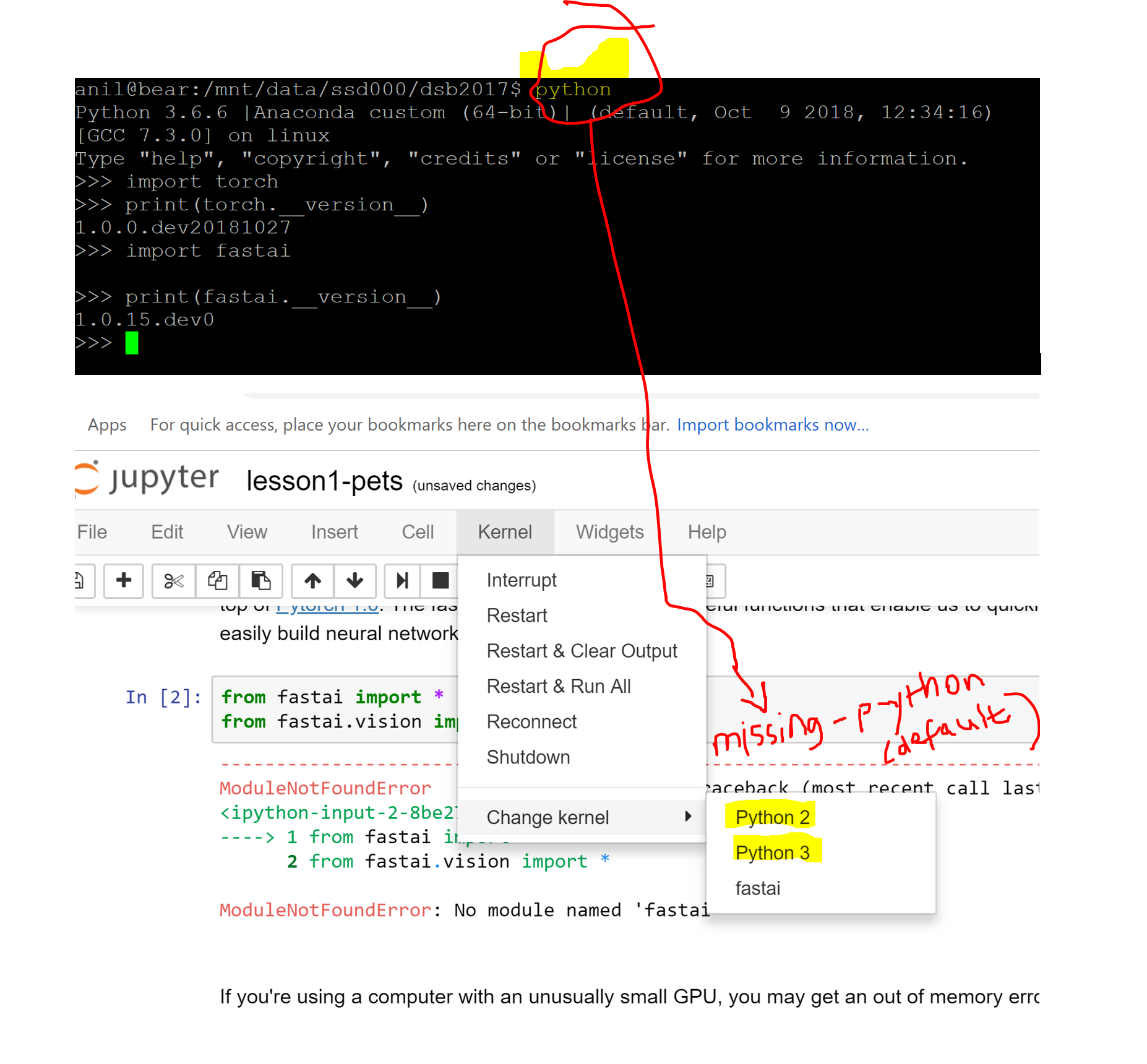
Thanks, that worked. There was only images folder in the oxford-iiit-pets folder so I deleted it & downloaded again. I found that downloading dataset multiple times doesn’t effect older downloaded version.So, there might be some other issue due to which this happened. Also storage folder could have been easily found in the root folder if I would have scrolled down
Guys,
I’m trying to build a classifier on government issued id cards like driving licence, PAN Card(Income tax related). Currently I’ve two classes
- Driving Licence - 70 images that I was able to get from Google
- PAN Card - 25 images from Google
I used google_images_download to download the images to my local machine and properly label them. Once done, I’ve created a git repo on bitbucket and cloned the data into Paperspace storage using git.
I was able to properly set the path for the images which I’ve downloaded into the /storage folder on Paperspace Gradient using below pieces of code and the fnames are properly giving the filenames
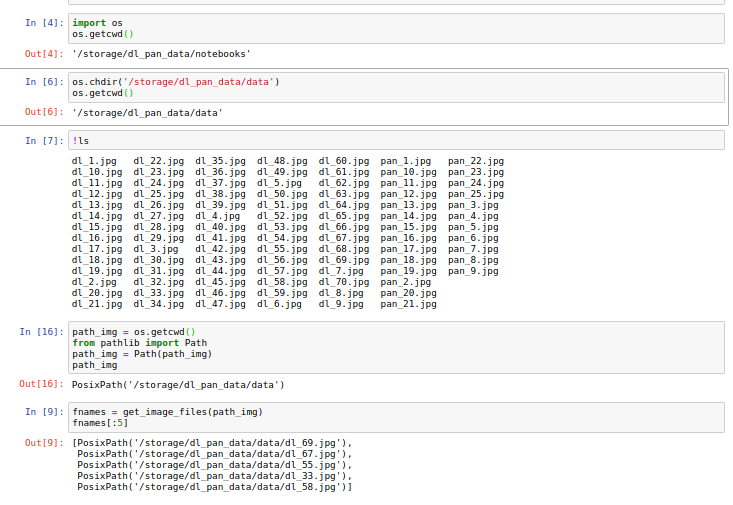
The regex was also working fine and was able to find out the two classes like below
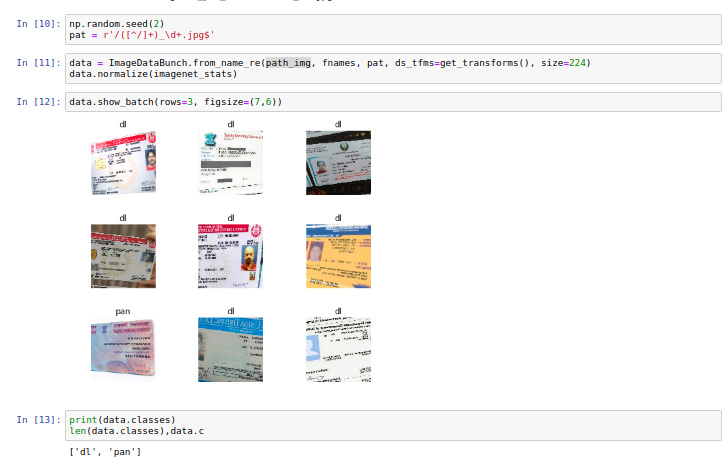
Now when I try to fit the model with the resnet34, I receive the ZeroDivisionError like below
learn = ConvLearner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(1)
ZeroDivisionError
ZeroDivisionError Traceback (most recent call last)
in
----> 1 learn.fit_one_cycle(1)/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, wd, callbacks, **kwargs)
17 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor,
18 pct_start=pct_start, **kwargs))
—> 19 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
20
21 def lr_find(learn:Learner, start_lr:Floats=1e-7, end_lr:Floats=10, num_it:int=100, stop_div:bool=True, **kwargs:Any):/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
135 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
136 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
→ 137 callbacks=self.callbacks+callbacks)
138
139 def create_opt(self, lr:Floats, wd:Floats=0.)->None:/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
87 except Exception as e:
88 exception = e
—> 89 raise e
90 finally: cb_handler.on_train_end(exception)
91/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
78 xb, yb = cb_handler.on_batch_begin(xb, yb)
79 loss = loss_batch(model, xb, yb, loss_func, opt, cb_handler)[0]
—> 80 if cb_handler.on_batch_end(loss): break
81
82 if hasattr(data,‘valid_dl’) and data.valid_dl is not None:/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/callback.py in on_batch_end(self, loss)
236 “Handle end of processing one batch withloss.”
237 self.state_dict[‘last_loss’] = loss
→ 238 stop = np.any(self(‘batch_end’, not self.state_dict[‘train’]))
239 if self.state_dict[‘train’]:
240 self.state_dict[‘iteration’] += 1/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/callback.py in call(self, cb_name, call_mets, **kwargs)
185 “Call through to all of theCallbakHandlerfunctions.”
186 if call_mets: [getattr(met, f’on_{cb_name}‘)(**self.state_dict, **kwargs) for met in self.metrics]
→ 187 return [getattr(cb, f’on_{cb_name}’)(**self.state_dict, **kwargs) for cb in self.callbacks]
188
189 def on_train_begin(self, epochs:int, pbar:PBar, metrics:MetricFuncList)->None:/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/callback.py in (.0)
185 “Call through to all of theCallbakHandlerfunctions.”
186 if call_mets: [getattr(met, f’on_{cb_name}‘)(**self.state_dict, **kwargs) for met in self.metrics]
→ 187 return [getattr(cb, f’on_{cb_name}’)(**self.state_dict, **kwargs) for cb in self.callbacks]
188
189 def on_train_begin(self, epochs:int, pbar:PBar, metrics:MetricFuncList)->None:/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/callbacks/one_cycle.py in on_batch_end(self, train, **kwargs)
41 if train:
42 if self.idx_s >= len(self.lr_scheds): return True
—> 43 self.opt.lr = self.lr_scheds[self.idx_s].step()
44 self.opt.mom = self.mom_scheds[self.idx_s].step()
45 # when the current schedule is complete we move onto the next/opt/conda/envs/fastai/lib/python3.6/site-packages/fastai/callback.py in step(self)
304 “Return next value along annealed schedule.”
305 self.n += 1
→ 306 return self.func(self.start, self.end, self.n/self.n_iter)
307
308 @propertyZeroDivisionError: division by zero
I was searching in the forum and saw that this might be caused due to the low number of images in the data set. Other post suggested the path to the ImageDataBunch might be incorrect and this is not my case.
Did anyone face a similar issue while training with less number of images ? If number of images is not the issue, can someone help me out. I’ll keep looking and come back if I find a solution.
1 - As long as the classifier can get a sufficient number of distinct images per class to work upon, it should usually work fine. In general, more the images, better the accuracy of the results.
2 - Depends on the image classifier. Some can work with multiple types of images. The classifier software ultimately works with arrays of pixels irrespective of the image type. For the current FastAI version, the code will need to be deep dived into to check the same as regards it’s ability to handle multiple image types.
Hope this helps. My 2 p only.
1 Like
@kofi… Did you observe any increase in error_rate. I am also trying out the same dataset. But havent executed any fit on dataset.
Hi! I have been trying the fastai library on a dataset from kaggle competition named Plant Seedlings Classification. I able to train the model using fastai library using resnet34 as shown by Jeremy. My question is how do I get the prediction for test data?
@_Ali, I think you can use learn.predict_array(), Now seems like we also have batch predictions (learn.pred_batch()). just check the documents for the arguments.
I faced same issue while I was working on my dataset of sitar and guitar classification. I just had 100 images per class. This problem occurs due to small number of images per class. I don’t know the exact reason of this problem. But increasing the cycles i.e. learn.fit_one_cycle(1) changing the value from 1 to greater than 2 might help you to solve this problem.
@sgugger has already answered the same here -
The above error is obviously being caused by denominator value of 0 in one of the metrics calculation code. This could happen when the number of images are too small in a particular class and the classifier may not be able to get a value for one of the categories that it is expecting - e.g. the number of predictions that it has made for a class.
As you and others have rightly inferred, increase the number of images ensuring that each class of images is represented in the training data.
Hope this helps.
2 Likes
I too got into same error while testing on a custom dataset with about 30 images per class. When I had increased the epochs to 4, it worked.
2 Likes
thank you for the reply. I tried and it is throwing an error, which i shared below.
The Test data is in folder named as “test” and I have specified test data set using the code below. Any help is appreciated.
ImageDataBunch.from_folder(path=path ,test="test", ds_tfms=get_transforms(), size=224, bs=bs )
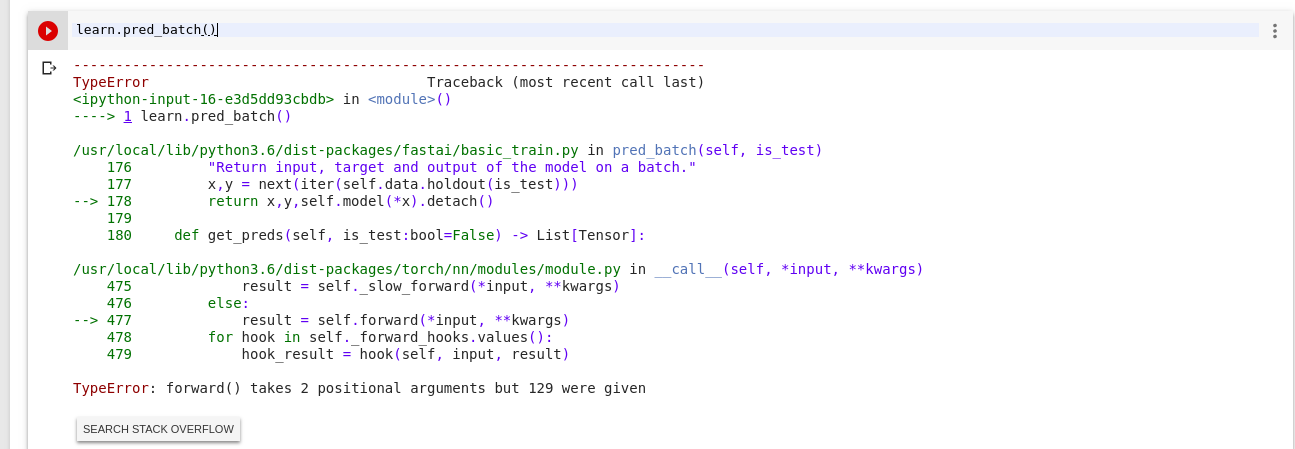
And we added a safeguard to make sure there is no division by zero now. That’ll be in the next version of the library.
1 Like
Ah my bad, I broke this when fixing a bug. Can you use learner.get_preds for now?
Thanks. Great.
I am facing the same issue. Is there anything concerned with me running it on google colab.?