It means that the lengths/values aren’t equal. I’m not 100% sure that command matters,but don’t take my word for it. Try anyway and see if the rest of the code works.
As for the ‘interp.plot_top_losses(9, figsize=(15,11)),’ it may be because, if you are using a different dataset, there may not be enough images or are not fitted to that size. What I suggest you do is play around with those numbers until something works, like making the numbers smaller.
Ok, there’s nothing to worry about. I’d like to see it. And by the way, I just started a few weeks ago and am rerunning through lessons 1-4 again; I didn’t understand much. You’ll be great.
Your error rate isn’t 1% it’s 100%. Try to increase the learning rate as well as epoch. In the second epoch it goes to 84% which is 16% difference.
I can’t seem to find out what a foliar learner is, but if I were you, I’d try the CNN learner, because it looks like this learner isn’t the best for this situation.
For interp plot losses, I would change th 15,11 to smaller numbers, but first focus on making the basic model work before fine-tuning.
I know this doesn’t exactly math your questions you wrote in the code, but overall, I recommend playing with the model. And I’d definitely try the CNN instead of the foliar learner.
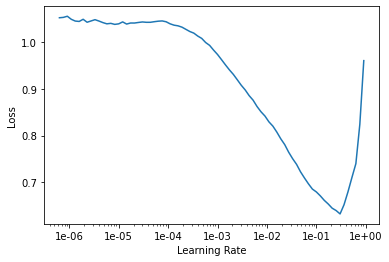
To add onto @DArXToRm24 (which btw, foliar_learner was simply his variable name for the Learner generated from cnn_learner), when you first began fitting you didn’t find a learning rate to use, and this would be the first step to start at. Begin by doing an lr_find() and then pick your learning rate based on those results. I’d imagine you’ll get a better accuracy with this
@muellerzr and @DarXtoRm24, thank you both. I took your advice by running the learning rate finder first, and then picking the biggest down-slope as my max_lr range when I started to train my model:
These results are better but still pretty bad. I started the model from scratch several times, and it seems like my model always settles to about 80% error. I even tried 10 epochs once.
I’m wondering if this dataset is too tough for what I know based on lessons 1 and 2? Or am I still doing something wrong?
Also, I noticed that there are at least a few mislabeled images. For example my top loss was this image:
Alright. At this point, I’m just going to shoot off suggestions that I don’t know will work, but they’re my best guesses. It’s good the we got those other things out of the way.
One thing you should do, for sure, is fix those mislabeled images. Go through the top losses and find those, because a model can’t run on ‘broken’ data. The loss is killing the model. Also, take out images that aren’t helpful.
My next suggestion is increase the learning rate, especially if fixing the data doesn’t work.
It’s good that you went through the data and found the issue. Good luck!