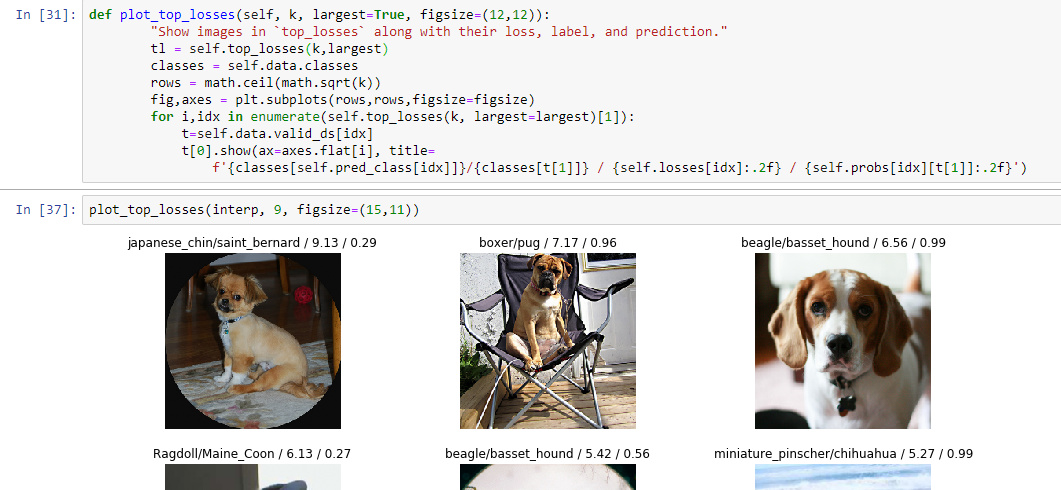
So here is the source code:
def plot_top_losses(self, k, largest=True, figsize=(12,12)):
"Show images in `top_losses` along with their loss, label, and prediction."
tl = self.top_losses(k,largest)
classes = self.data.classes
rows = math.ceil(math.sqrt(k))
fig,axes = plt.subplots(rows,rows,figsize=figsize)
for i,idx in enumerate(self.top_losses(k, largest=largest)[1]):
t=self.data.valid_ds[idx]
t[0].show(ax=axes.flat[i], title=
f'{classes[self.pred_class[idx]]}/{classes[t[1]]} / {self.losses[idx]:.2f} / {self.probs[idx][t[1]]:.2f}')
The first thing I do with this is look at what is generating this. So I ran the notebook up to the point where it runs the interp.plot_top_losses and I copy and pasted that code into the notebook so I could mess around with it.
So this is what that looks like for me:
You’ll notice I had to feed interp to it instead of doing interp. (there is probably a way to change that, but this works)
So now, I start looking at the individual lines so the first line for me now looks like this:
interp.top_losses(9,True)
So basically that is taking the 9 largest losses and it looks like you could pretty easily take the smallest losses by changing that to false.
Onto the actual answer to your initial question:
Here are the four things:
f'{classes[self.pred_class[idx]]}/{classes[t[1]]} / {self.losses[idx]:.2f} / {self.probs[idx][t[1]]:.2f}'
The first is the prediction of each image: classes[self.pred_class[idx]]
The second is the true value: classes[t[1]] (t is pulled earlier and has the image in t[0] and the true value in t[1])
The third is the loss of that specific image
The fourth is the prediction percentage of the true value.
I verified that with the following image:

#predicted value
print("Predicted value: "+str(interp.pred_class[tl[1][0]].item()))
#Actual value
print("Actual value: " + str(t[1]))
#Prediction is 99.95%
print("Prediction Percentage: " + str(interp.probs[tl[1][0]][32].item()))
#Prediction of actual value is 28.51%
print("Prediction of Actual Percentage: " + str(interp.probs[tl[1][0]][13].item()))
Predicted value: 32
Actual value: 13
Prediction Percentage: 0.999451220035553
Prediction of Actual Percentage: 0.2851499915122986