Does any of you have tips on how to further reduce my training loss & Accuracy?
I’m currently creating a language model based on the sentiment140 twitter dataset. I already tried varying vocabulary sizes (50k, 25k) Adam optim with low lr, SGD with momentum and high lr, different embedding sizes, hidden layer sizes, batch sizes, different loss multiplication ratios, but no matter what I try I can’t seem to get it below a value of 0.417, but this took 30 epochs. While I see you guys easily getting below 0.4 in just 2 epochs.
My dataset has these properties:
trainingset length: 1.440.000
validation length: 160.000
unique words: 321.439
max vocab used: 50.000/25.000 (min freq. of 4 returns 52k~)
len(np.concatenate(trn_lm)): 22.498.795
settings:
chunksize: 50.000
em_sz,nh,nl: 400,1100,3 (Would smaller sizes be better for smaller datasets?)
bptt: 70
bs: 50
opt_fn: optim.SGD, momentum=0.9
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15], dtype=“f”)*0.5
use_clr_beta=(10,20,0.95,0.85)

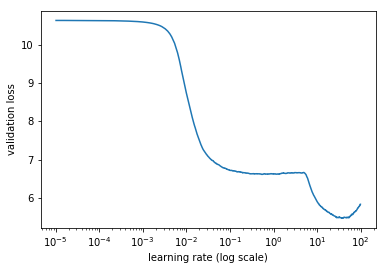
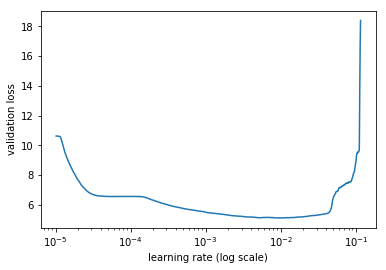
Following these I decided to use an lr around 18, but the accuracy seems to fall with rising lr, so should I stick to something between 0 and 2.5 then?
the resulting training looks like this:
epoch trn_loss val_loss accuracy
0 4.885424 4.765574 0.204343
1 4.68609 4.581247 0.219108
2 4.588282 4.500839 0.226138
3 4.54668 4.470822 0.227034
4 4.514667 4.445856 0.229765
5 4.476595 4.433705 0.23107
6 4.479217 4.425251 0.231592
7 4.452099 4.431449 0.230048
8 4.44206 4.419237 0.232063
9 4.436647 4.417188 0.232431
10 4.43317 4.412861 0.232667
11 4.422395 4.413309 0.232941
12 4.414105 4.402681 0.234613
13 4.425107 4.39716 0.234751
14 4.387628 4.395168 0.235595
15 4.402883 4.386707 0.235551
16 4.363533 4.378289 0.238221
17 4.357185 4.37697 0.237533
18 4.367101 4.368633 0.237971
19 4.313777 4.360797 0.240501
20 4.291882 4.358919 0.239816
21 4.281025 4.346954 0.242128
22 4.27367 4.337309 0.243213
23 4.240626 4.327436 0.244454
24 4.203354 4.322042 0.245484
25 4.24484 4.316995 0.245593
26 4.242165 4.313355 0.246129
27 4.175661 4.311628 0.246528
28 4.162489 4.308656 0.247344
29 4.17869 4.30674 0.247567
It seems to keep improving the longer I learn, but I can’t let it learn for too long, because I still need to use this computer to work, which I can’t while it’s doing the learning…