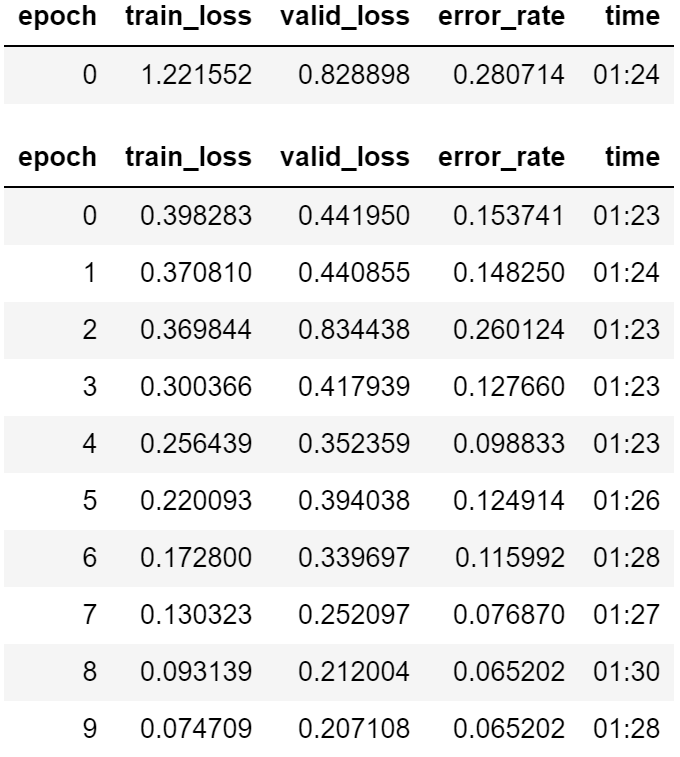
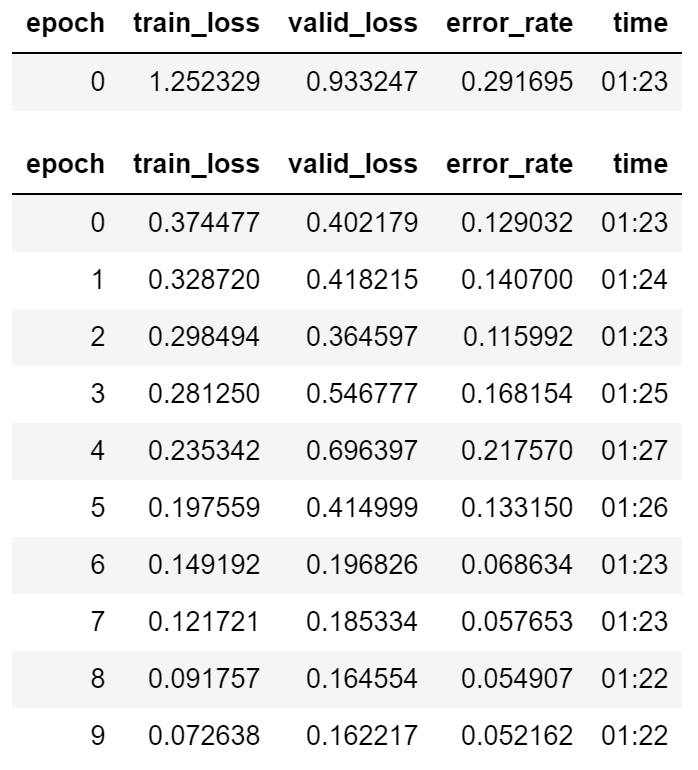
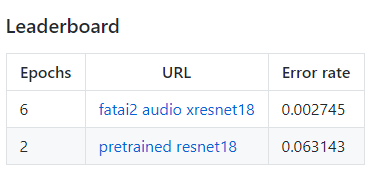
Just thought I’d throw in a little quick example of xresnet etc. Note this is not pretrained model and what I found is that epoch for epoch it’s fairly similar minus a few training bits that you’ll notice. My current setup is:
- Mish activation
- Self-Attention
- Label Smoothing Cross Entropy
- Ranger optimizer
- Cosine Annealing fit function
I also normalized our data by taking in the first batch of data’s stats.
For architecture it was a xresnet18 where I modified the first input layer like so (we don’t have pretrained weights so it’s just converting the conv2d):
l = nn.Conv2d(1,32, kernel_size=(3,3), stride=(2,2),
padding=(1,1), bias=False)
l.weight = nn.Parameter(l.weight.sum(dim=1, keepdim=True))
net[0][0] = l
In the first epoch alone I was able to get 7% error, with a finish of 2.8% however if you notice I wasn’t quite training properly or something because epoch 3 spiked to 18% error. Running another test now 
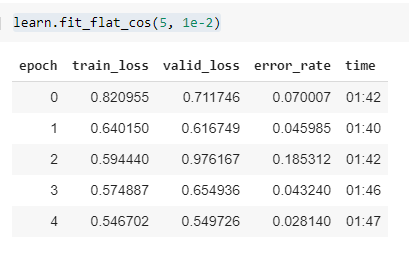
 I renamed
I renamed