I have been posting about new papers which are interesting under the Deep Learning category for a while now. But I since most of the stuff I post about is either directly connected to Stable Diffusion or Stable Diffusion adjacent, I thought maybe having a single thread where others can post papers that they find too might be useful?
Perhaps this thread can lead to new research/experiment opportunities for those who are interested or we can pick a paper from here to work on together?
Anyway, that’s my hope/rationale
I’ll post the first paper that I found interesting as a separate post below …
Stable Diffusion for text? The paper on Self-conditioned Embedding Diffusion for Text Generation, or (SED) says that might be a possibility …
This could lead to some interesting things (but also possibly an outcry from writers similar to what happened with artists with regard to SD?) if it works well. Especially if it can be trained on the work by a particular writer to create new text in their style?
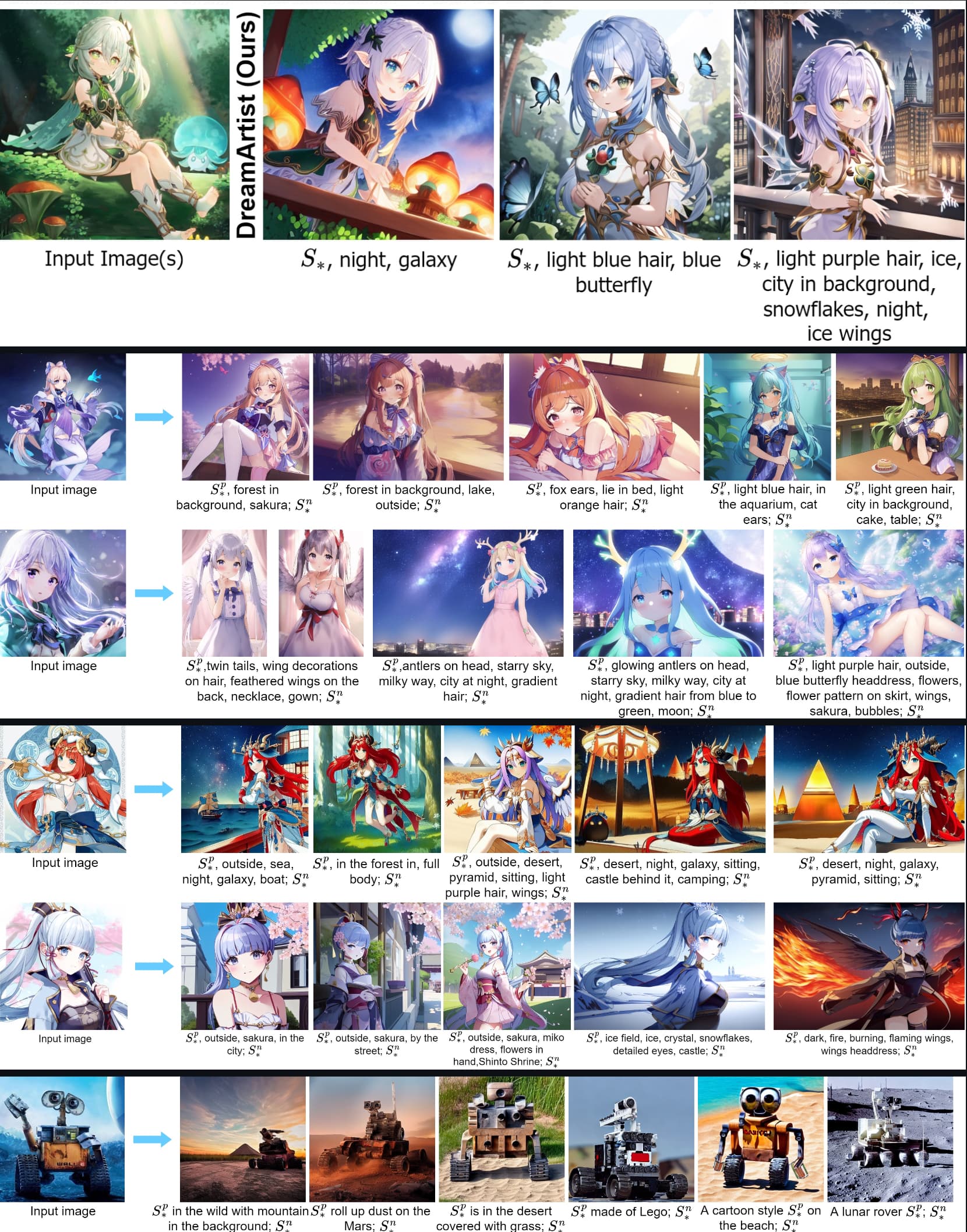
“DreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning”
Claims to achieve similar results to DreamBooth from just ONE image, impressive! Also cool how you can interweave multiple learned concepts together into one prompt (prompt composition). The paper doesn’t appear to be listed yet but here is the code already.
code
In this paper we introduce Paella, a novel text-toimage model requiring less than 10 steps to sample highfidelity images, using a speed-optimized architecture allowing to sample a single image in less than 500 ms, while having 573M parameters. The model operates on a compressed
& quantized latent space, it is conditioned on CLIP embeddings and uses an improved sampling function over previous works. Aside from text-conditional image generation,
our model is able to do latent space interpolation and image
manipulations such as inpainting, outpainting, and structural editing.
code
In this work, we expand the existing single-flow diffusion pipeline into a
multi-flow network, dubbed Versatile Diffusion (VD), that
handles text-to-image, image-to-text, image-variation, and
text-variation in one unified model. Moreover, we generalize VD to a unified multi-flow multimodal diffusion framework with grouped layers, swappable streams, and other
propositions that can process modalities beyond images and
text.
In this paper, we propose an optimization-free and zero fine-tuning framework that applies complex and non-rigid edits to a single real image via a text prompt, avoiding all the pitfalls described above. Using widely-available generic pre-trained text-to-image diffusion models, we demonstrate the ability
to modulate pose, scene, background, style, color, and even racial identity in an extremely flexible manner through a single target text detailing the desired edit. Furthermore, our method, which we name Direct Inversion, proposes multiple intuitively configurable hyperparameters to allow for a wide range of types and extents of real image edits.
Dataset of 14 million images generated using Stable Diffusion and their respective prompt and hyperparameters scraped from the official Stable Diffusion Discord server.
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image.
What’s exciting about InstructP2P is that it elevates quite a restricted application, prompt-to-prompt, and makes generalized natural language editing possible. Prompt-to-prompt is like a super-effective DiffEdit–awesome!–but it only works on diffusion-generated images, so you can’t edit arbitrary images. But it does a really great job of editing within the diffusion model universe. InstructP2P uses GPT-3 to generate the prompts and Prompt-to-prompt to generate the original and the edited images. Now you have a diffusion model that’s conditioned on a) editing text (“make this jacket out of leather”) b) start image and it “diffuses” the edited image.
It all seems quite tidy and straightforward – and effective!
BTW I’d love for us to dig into prompt-to-prompt a bit, because it plays with the internals of the attention mechanism. The code’s all there GitHub - google/prompt-to-prompt
I just saw this and checked in to forum if somebody had already posted it.
This usage of diffusion technique just clicked something in my brain, I can already see now how it might be used for plenty of other things. Suddenly, diffusion models are now very interesting to me. Will be looking into this paper later today.
In this work, we introduce a universal approach to guide a pretrained text-to-image diffusion model, with a spatial map from another domain (e.g., sketch) during inference time. Unlike previous works, our method does not require to train a dedicated model or a specialized encoder for the task.
A downside of classifier-free guided diffusion models is that they are computationally expensive at inference time since they require evaluating two diffusion models, a class-conditional model and an unconditional model, tens to hundreds of times. To deal with this limitation, we propose an approach to distilling classifier-free guided diffusion models into models that are fast to sample from
We propose a novel model-based guidance built upon the classifier-free guidance so that the knowledge from the model trained on a single image can be distilled into the pre-trained diffusion model, enabling content creation even with one given image. Additionally, we propose a patch-based fine-tuning that can effectively help the model generate images of arbitrary resolution.