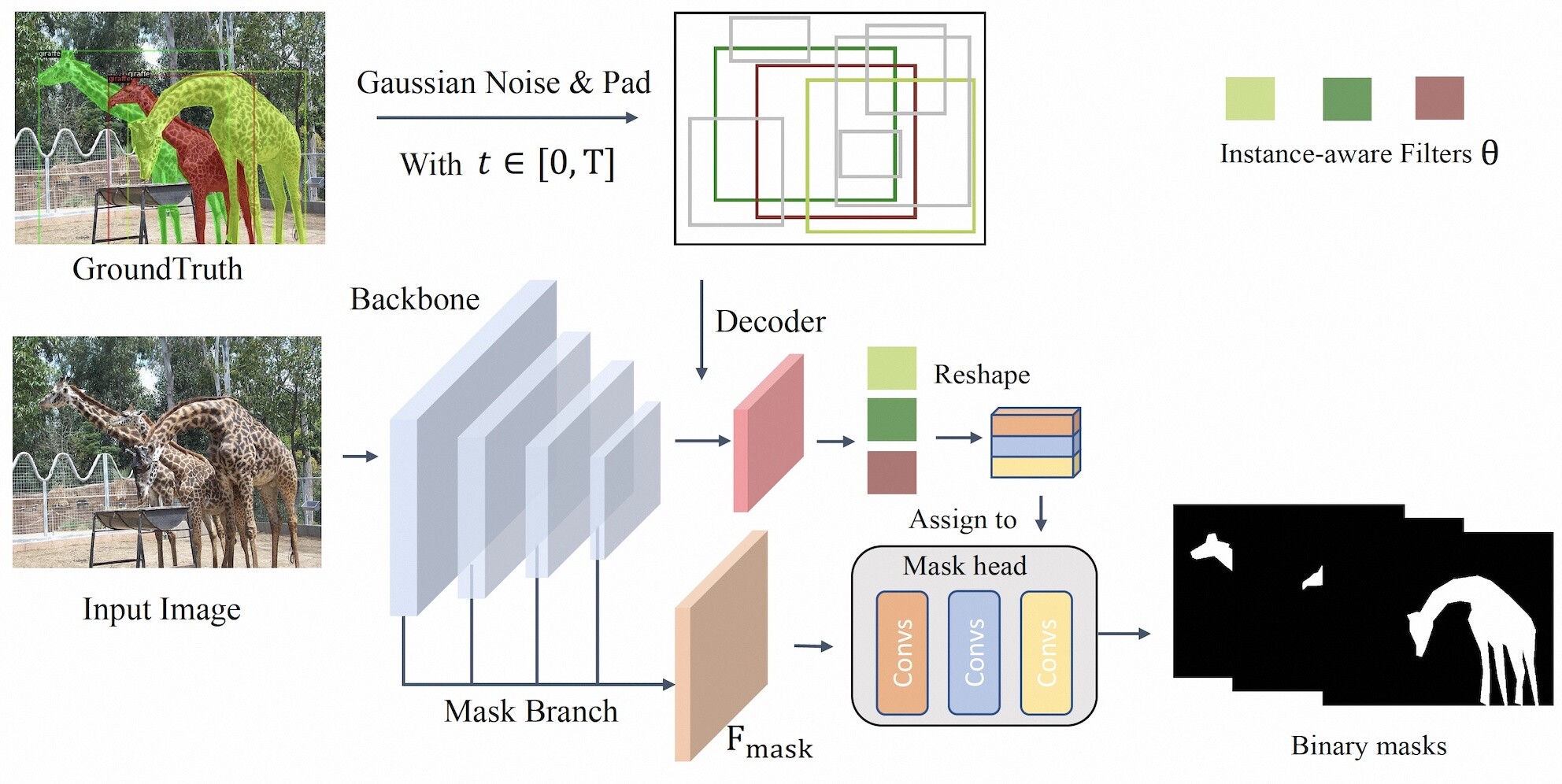
This paper proposes DiffusionInst, a novel framework that represents instances as instance-aware filters and formulates instance segmentation as a noise-to-filter denoising process. The model is trained to reverse the noisy groundtruth without any inductive bias from RPN. During inference, it takes a randomly generated filter as input and outputs mask in one-step or multi-step denoising.
Stable Artist, an image editing approach enabling fine-grained control of the image generation process. The main component is semantic guidance (SEGA) which steers the diffusion process along variable numbers of semantic directions. This allows for subtle edits to images, changes in composition and style, as well as optimization of the overall artistic conception. Furthermore, SEGA enables probing of latent spaces to gain insights into the representation of concepts learned by the model, even complex ones such as ‘carbon emission’.
The official implementation of the paper is available here and the demo colab notebook is here.
We present DiffusionBERT, a new generative masked language model based on discrete diffusion models. We explore training BERT to learn the reverse process of a discrete diffusion process with an absorbing state and elucidate several designs to improve it. First, we propose a new noise schedule for the forward diffusion process that controls the degree of noise added at each step based on the information of each token. Second, we investigate several designs of incorporating the time step into BERT.
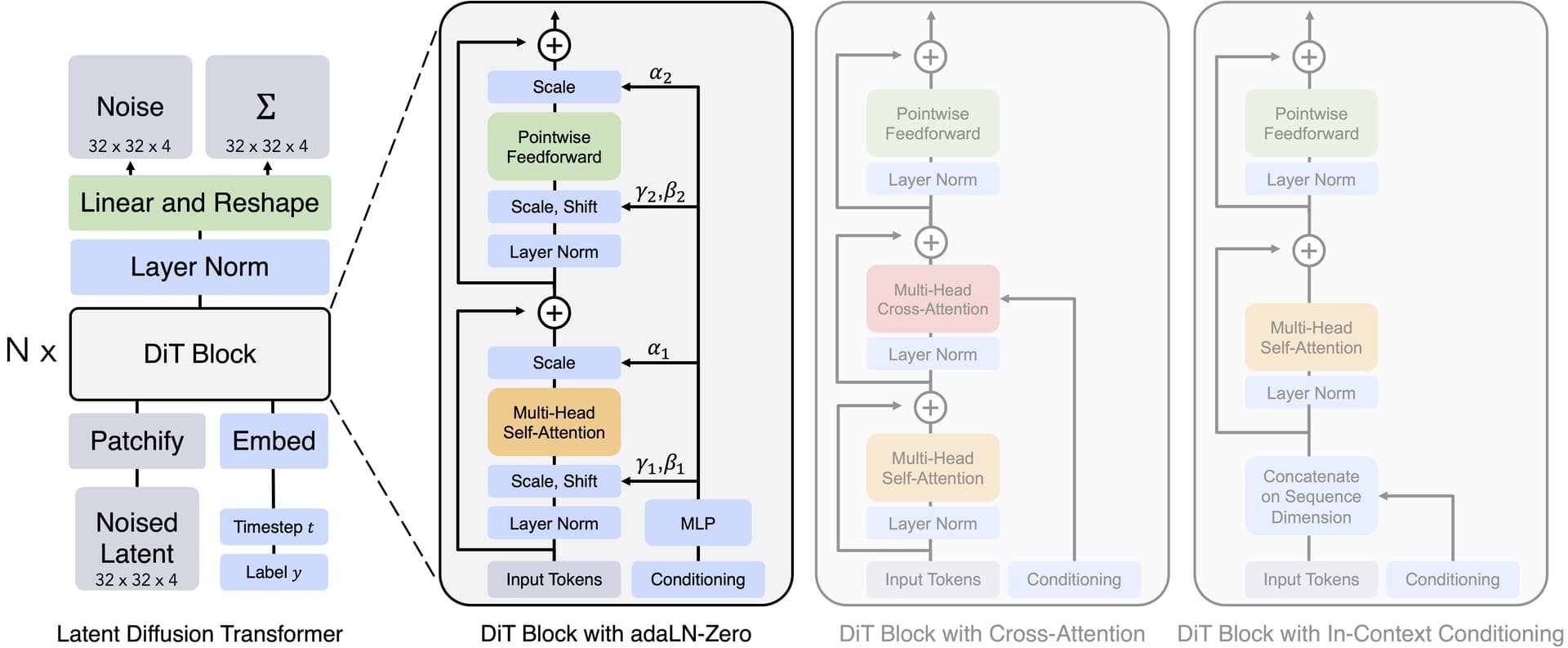
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches.
The official pytorch implementation of the paper is available here and the demo colab notebook is here.
this one seems particularly significant, opening the door to leveraging the vision transformer literature.
One question looms large: transformers are infamously slow to train. This was done during Peebles internship at Meta. (Interrns do a lot of the most interesting, cutting-edge work!) I wonder if someone can help me do the back-of-the-envelope math required to figure out the training cost here. It looks like they train on the order of 500k-1m steps. They train on “TPU v3 pods at 5.7 iterations/seocond on a TPU v3-256 pod with a batch size of 256.” 1m / 5.7 / 3600 … That’s almost exactly 48 hours for 1m iterations. (Is that right?)
It’s hard to nail down the price of a TPU v3-256 pod on GCP, but it’s probably less than $200, which a 3-year old reddit post indicates. That gives us a ceiling of $200 * 48 ~= $10k for training just ImageNet. Training on LAION and COCO would be a O(100) multiple on that.
That suggests (a speculative view) that while ViT’s are the future of diffusion, they might be cost-prohibitive unless Stability pours some venture funding into it, or we wait until 2024. On the other hand, maybe my “ceiling” was 10x too high given the rapid drop in compute costs over the last few years. TPUs are still pricy though, IIUC.
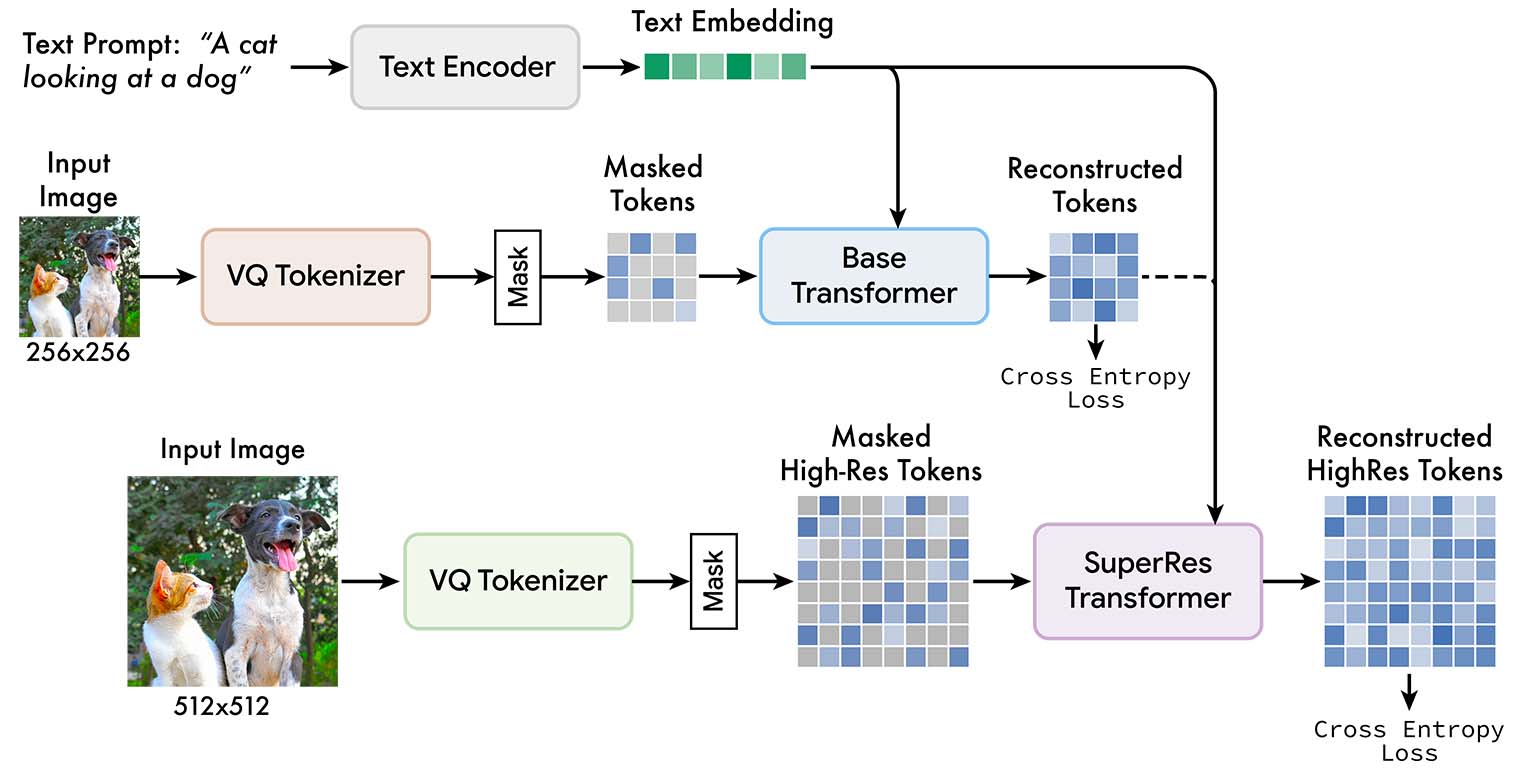
Muse training pipeline: Feed low resolution and high resolution images into two independent VQGAN tokenizer networks. These tokens are then masked, and low resolution (“base”) and high resolution (“superres”) transformers are trained to predict masked tokens, conditioned on unmasked tokens and T5 text embeddings.
Model
Resolution
Inference Time (↓)
Stable Diffusion 1.4*
512x512
3.7s
Parti-3B
256x256
6.4s
Imagen
256x256
9.1s
Imagen
1024x1024
13.3s
Muse-3B
256x256
0.5s
Muse-3B
512x512
1.3s
Stable Diffusion times represent the best reported inference times and were not measured internally. The configuration used to achieve FID of 12.63 uses 5x more diffusion steps than what was used for benchmarking, roughly equivalent to 18.5s sampling time.
Gen-1 announced by RunwayML today looks really amazing! I am really looking forward to testing this out once its available, you can sign up for the waitlist now.